
AI大模型探索
前言
由于gpt4已经出了4o版本,当前日期2024/7/10,总的来说已经十分强大了,但是国内外仍然有很多公司或者团队在自己研究自己的大模型,根本原因是gpt4不开源,而且提供的可调用的apitoken也比较贵,一个人对话次数频繁的话,一个小时几十块就没了,带着ai大模型和知识库的背景下,开始研究开源免费的ai大模型
AI是啥?大模型是啥?

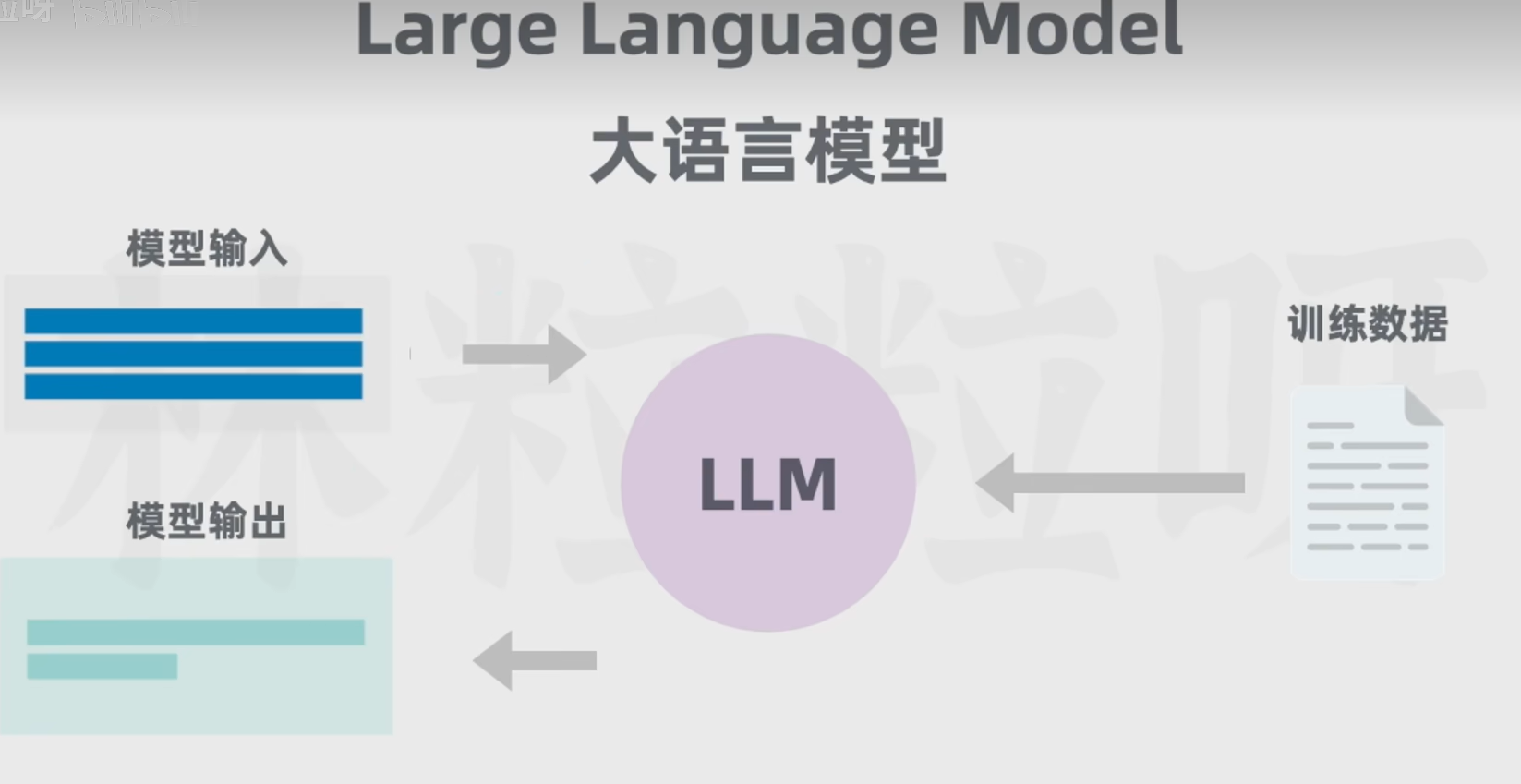
设备环境:
win11+GPU3060Ti(8G显存)+16G运行内存(这个不影响)
大模型环境 ollama:
由于大模型这两年已经比较成熟了,ollama已经能加载大部分开源大模型,所以相对于以前的cuda,现在的ollama更好用,由于我们是windows系统,ollama就直接装就完事儿了
ollama官网:https://ollama.com/
不过得记一下常用的ollama命令:
ollama list #查看大模型列表
ollama rm '大模型名称' #删除大模型
ollama creat '大模型名称' -f 'modelfile' #从本地调优后加载大模型
ollama run '大模型名称' # 运行大模型
本地大模型有了后,我们还需要前端页面呀,因此这里介绍三种前端可以连接大模型的页面:
UI样式
anything
页面自定义比较好,但是有不少小bug,上传文件后模型就回复慢甚至报错,shit一坨,浪费我时间
maxkb
个人认为是国内做的最好的知识库和ai大模型的前端,缺点就是不能自定义很多样式页面,也不支持多模态和excel
open-webUI
ollama最适配的前端页面,长得也像chatgpt,有点怀疑抄袭,支持多模态,也最全能,不过不能做知识库类型
部署这些前端的前提是本地要有docker环境,所以我们在windows下安装好docker,这个过程可能比linux要麻烦很多,要建议看视频
【【Docker教程】如何在Windows系统安装Docker】 https://www.bilibili.com/video/BV19J4m1j7nh/?share_source=copy_web&vd_source=4bbe3631cef72a69d43ef5defa5ba7d9
当我们有了docker环境后,库库一顿命令输出后,就有了现在的三个容器
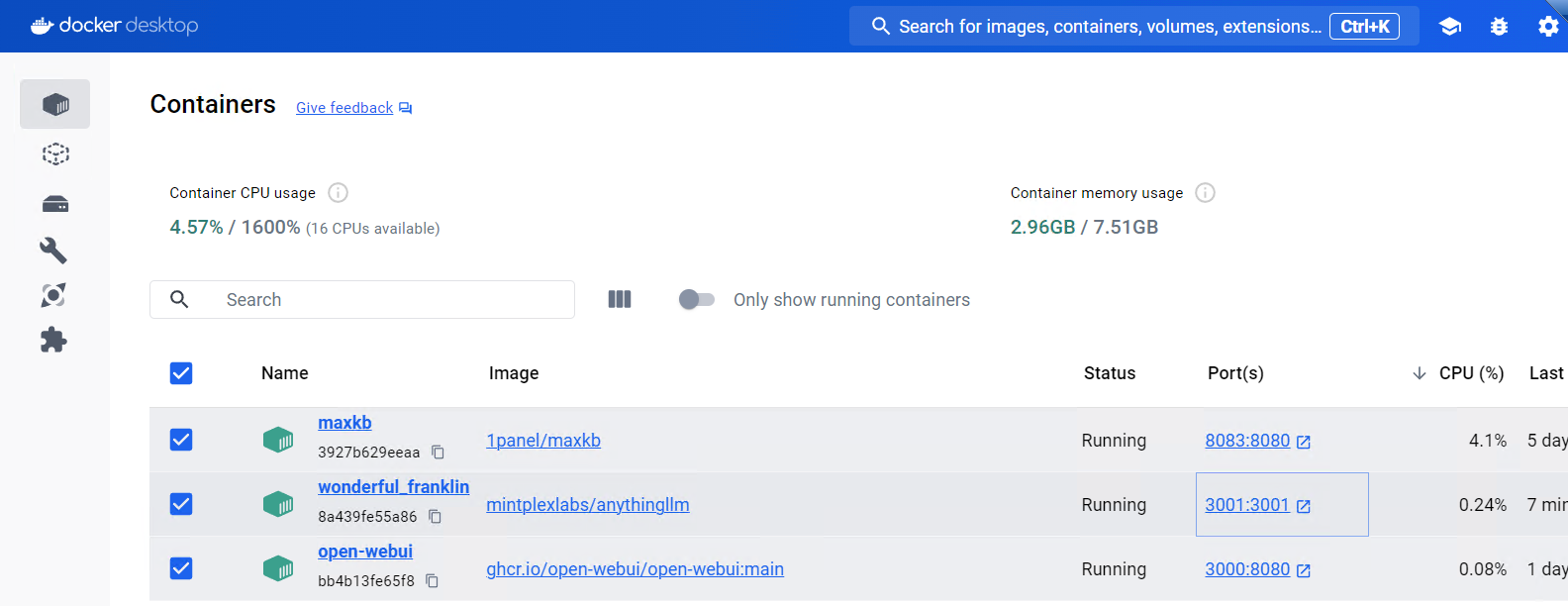
OK,上面也介绍完3大AI的UI了,如果是知识库用,那么最好用maxkb,如果是个人ai用,那么还是推荐open-webUI
ai大模型和知识库的结合:
那么我们首选还是maxkb作为前端页面,而大模型选择我们有很多
通义千问(阿里出品):一直在维护和更新(使用起来不咋地)
llama3:还可以,中文不太行
llama3-chinese:中文调教版本
glm4(智谱清言):比较吊,但是整体感觉不如llama3-chinese
通过一系列的踩坑和使用下来,这边大模型选择llama3-chinese,闭包模型我们从一个清华博士那下载https://huggingface.co/shenzhi-wang
不得不感慨一句:原来颜值和才华真的能并存啊
我们下载后会得到.gguf的模型文件,大概5个G左右,那么此时,我们需要编辑一个modelFile,通过modelFile去加载大模型(Ollama Modelfile 是一个配置文件,用于定义和管理 Ollama 平台上的模型。通过模型文件创建新模型或修改调整现有模型,以应对一些特殊的应用场景。自定义提示嵌入到模型中,修改和调整上下文长度、温度、随机种子、降低无意义程度、增加或减少输出文本的多样性等。(注:这不是微调,只是调整原来的模型的参数。))
# Modelfile generated by "ollama show"
# To build a new Modelfile based on this one, replace the FROM line with:
# FROM llama3:latest
FROM D:\softwares\maxkb\llama3\Llama3-8B-Chinese-Chat.q4_k_m.GGUF
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER temperature 0.6
PARAMETER top_p 0.9
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
PARAMETER stop "<|reserved_special_token"
使用 ollama create 命令根据自定义模型文件创建新模型。
ollama create llama3-chinese --file Modelfile-Llama3-8b
启动模型:
ollama run llama3-chinese
然后查看是否启动成功:
ollama list
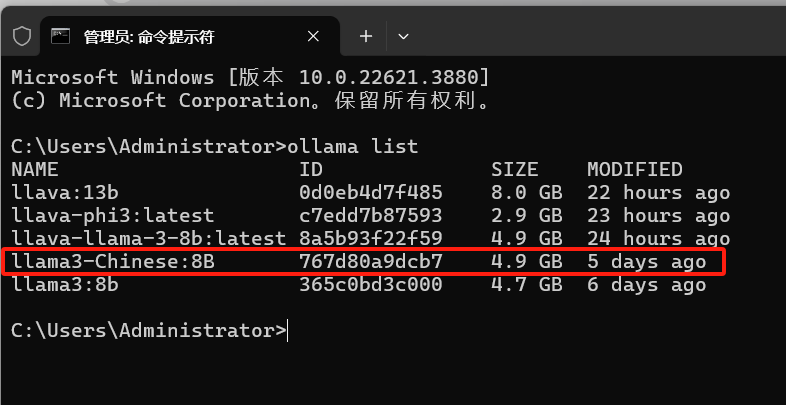
然后我们docker启动maxkb,装载llama3-chinese
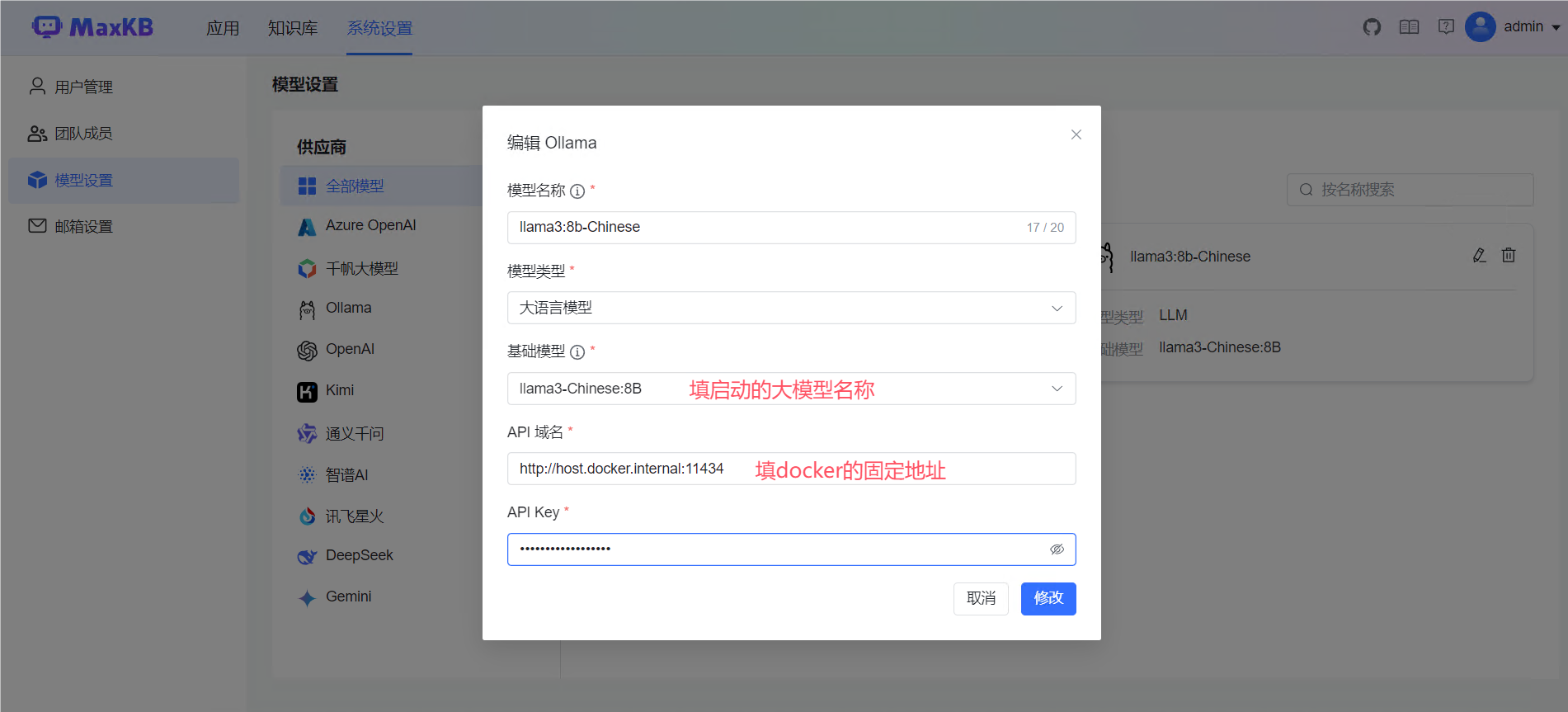
然后上传文件作为我们的知识库
然后创建应用
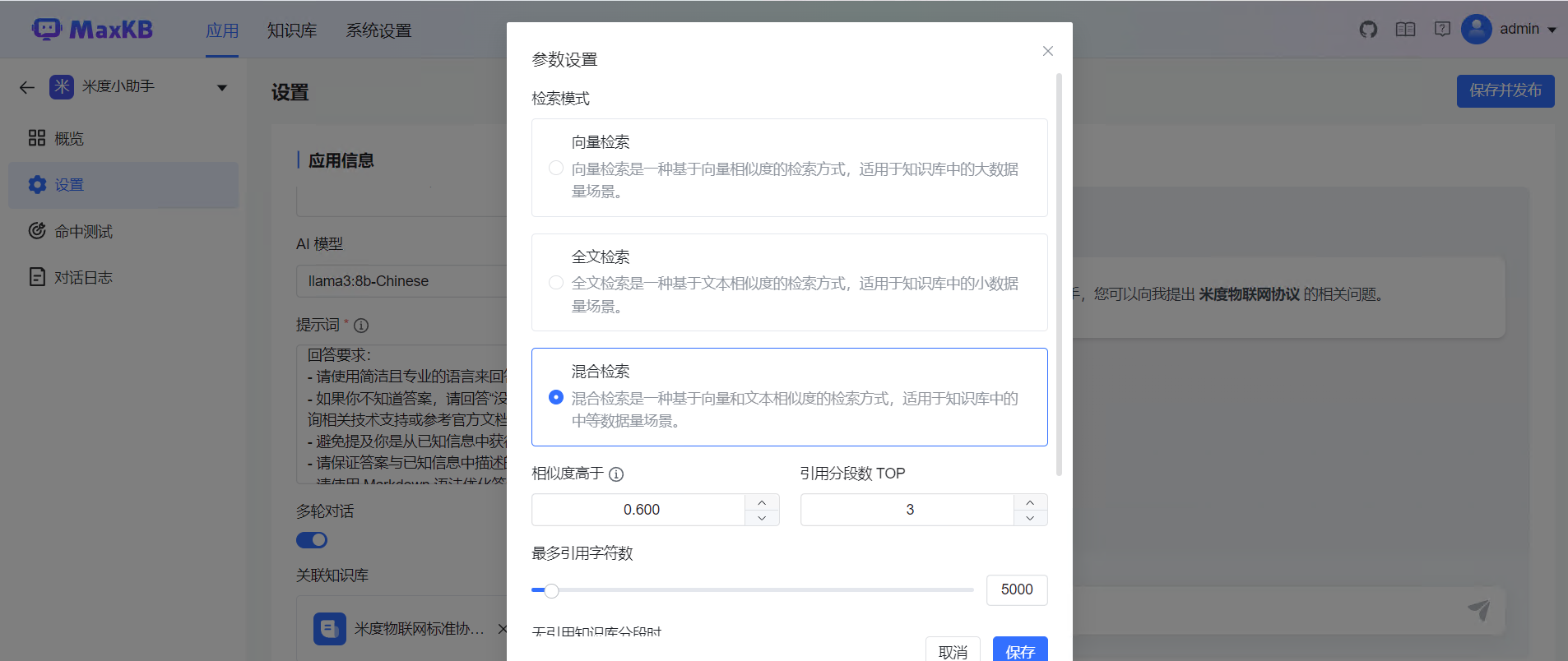
这里选择混合检索命中率高一些,然后选择我们的文档知识库和大模型,发布之后就可以应用啦,下面是知识库大模型的测试情况:
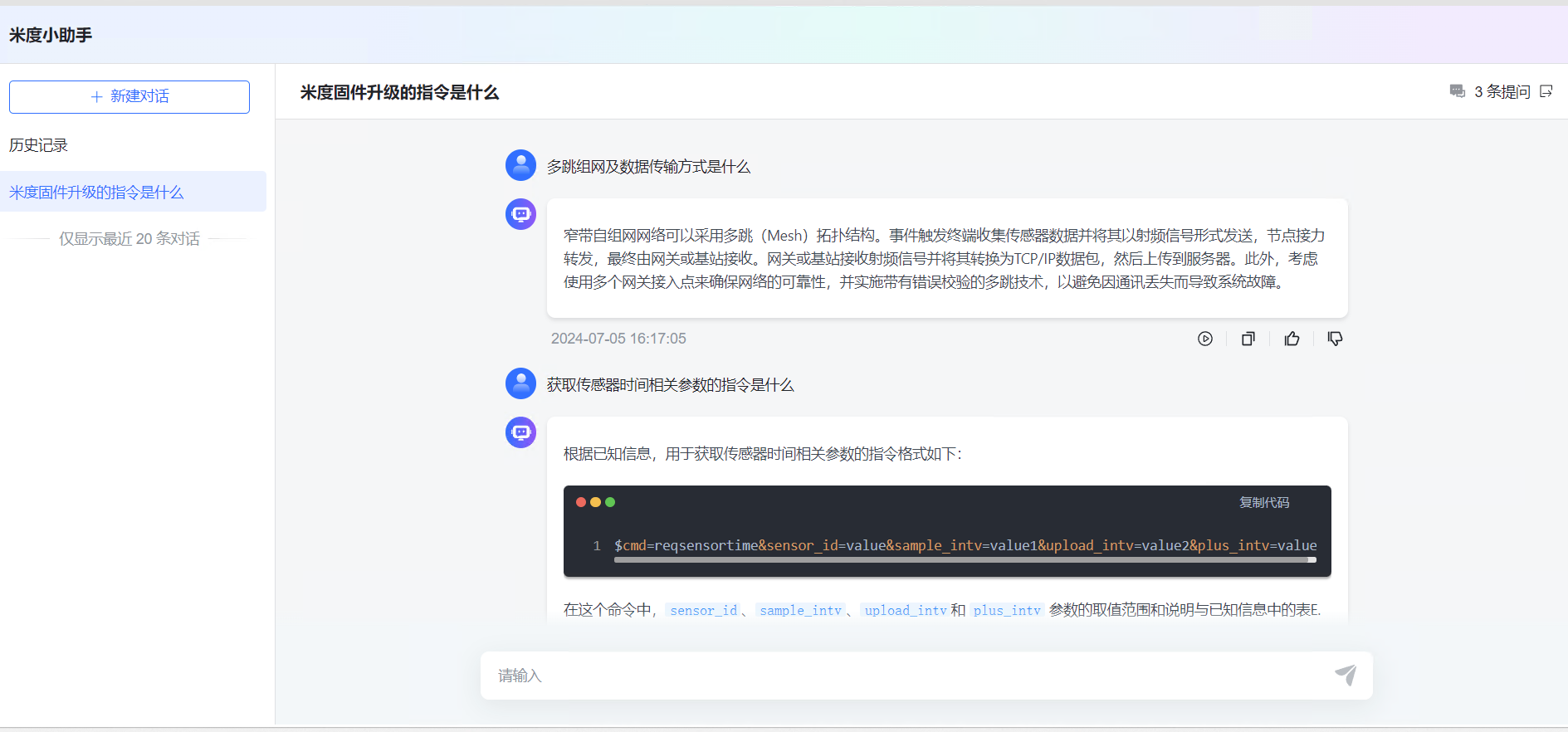
整体来说:还比较好用,回答的精准率和文档的规范性有很大的关系
ai对excel的支持
目前来说,ai对excel的支持并不友好,数据量稍微一大,查询和处理excel的能力要差很多,就拿现在最厉害的gpt4o来说
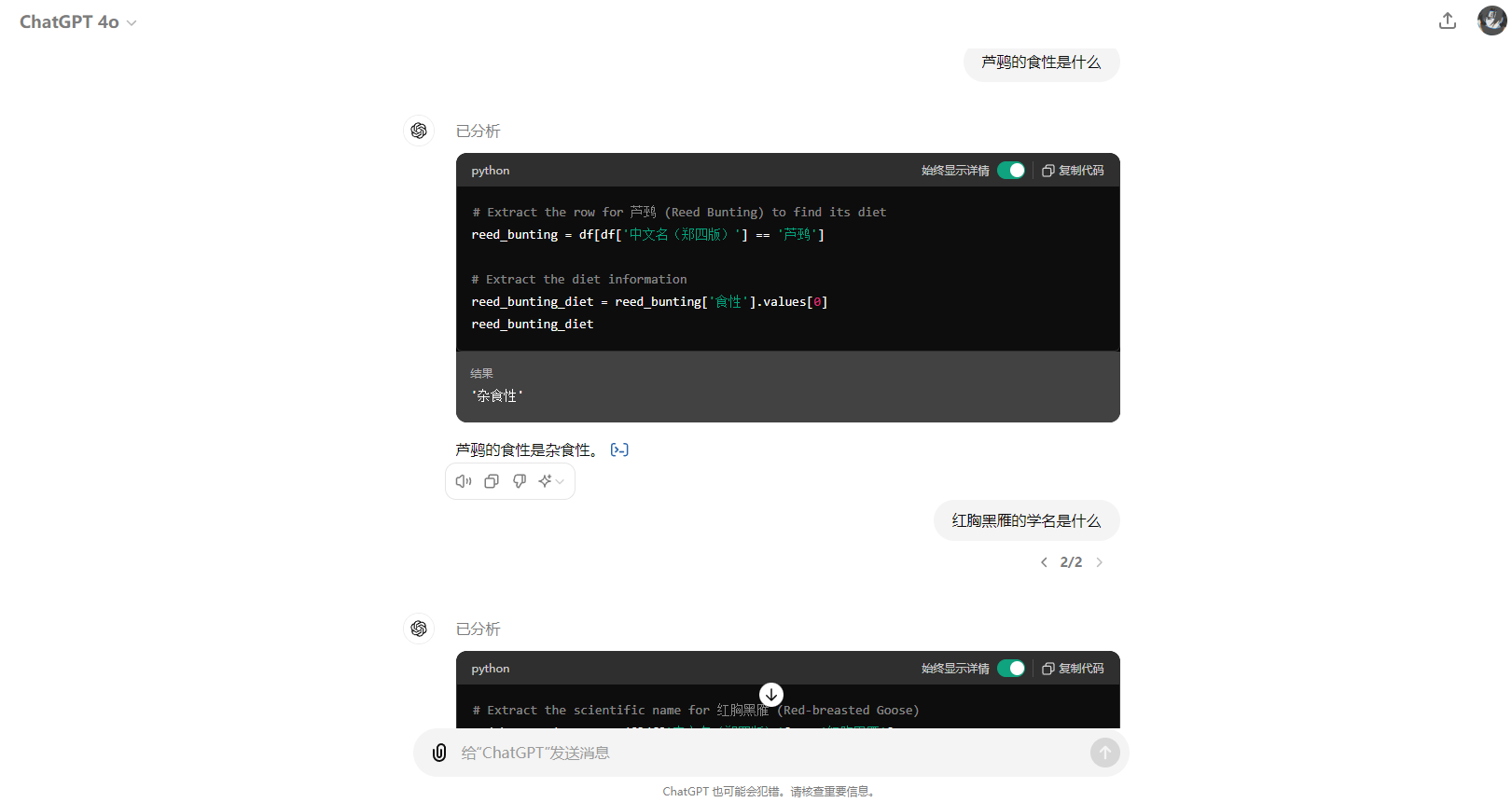
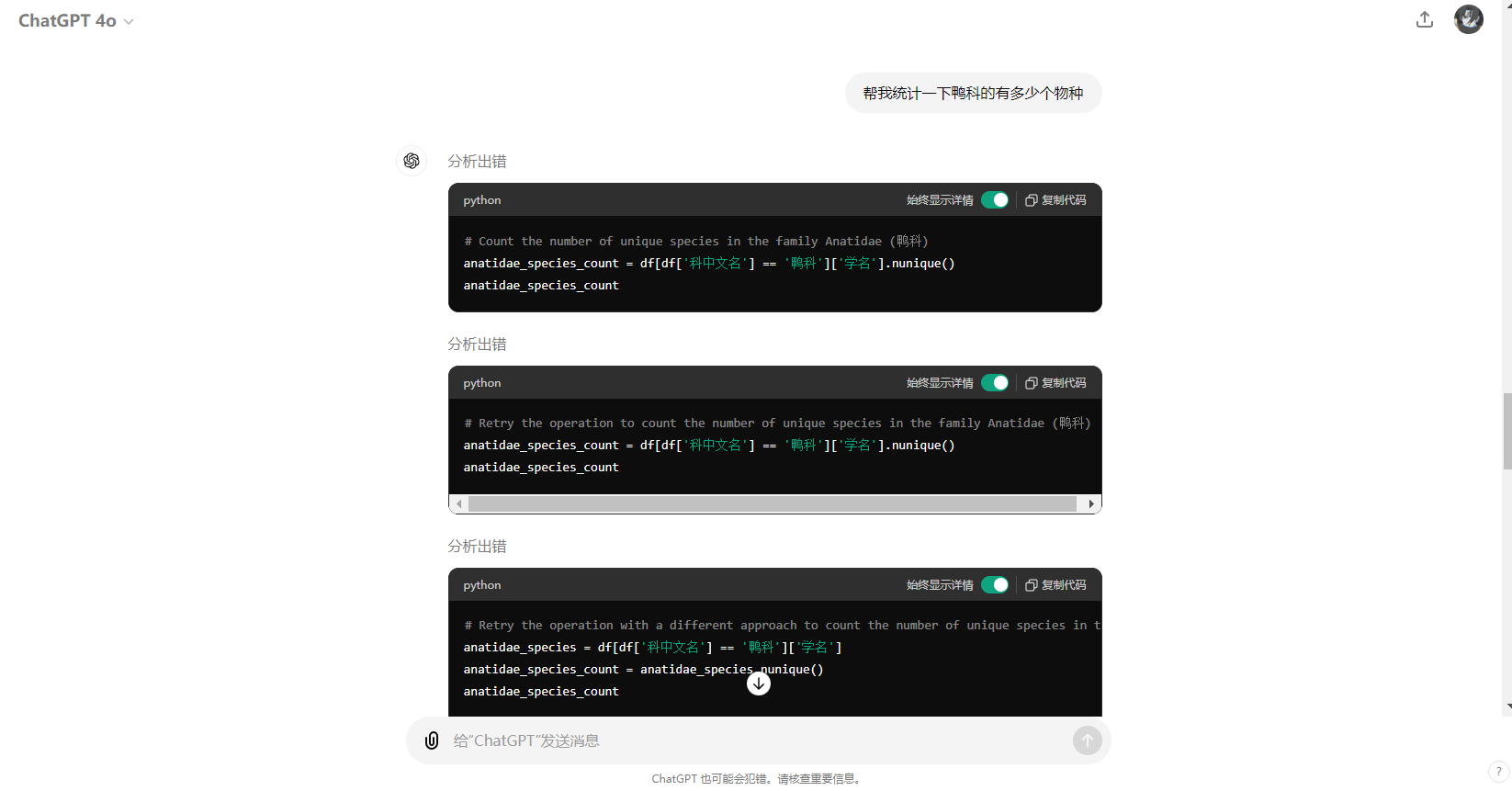
他对excel的处理方式也是自己通过写一段pandas代码去查询或者处理数据,而一旦涉及到复杂的统计情况,gpt4o就直接报错了,测试了其他几款大模型,效果都差不多,或许在excel这种数据类型上,ai并不能做的很好
ai多模态
ollama 上模型库(https://ollama.com/library)支持的多模态大模型只有llava和bakllava
那么理所当然的,中文不友好,于是乎,我找到加了中文参数的llava-ph3,下面看原生llava和llava-ph3的对比情况
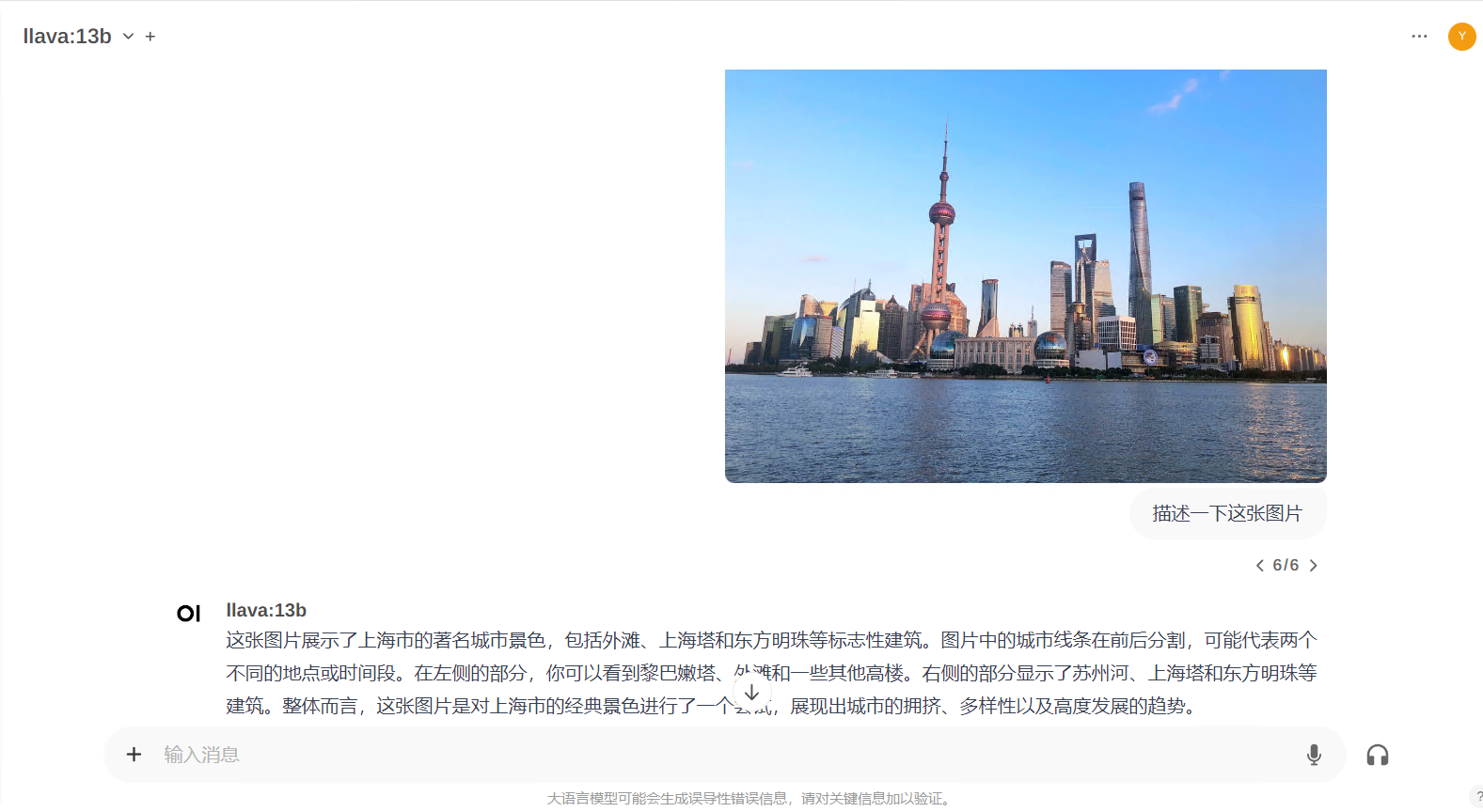
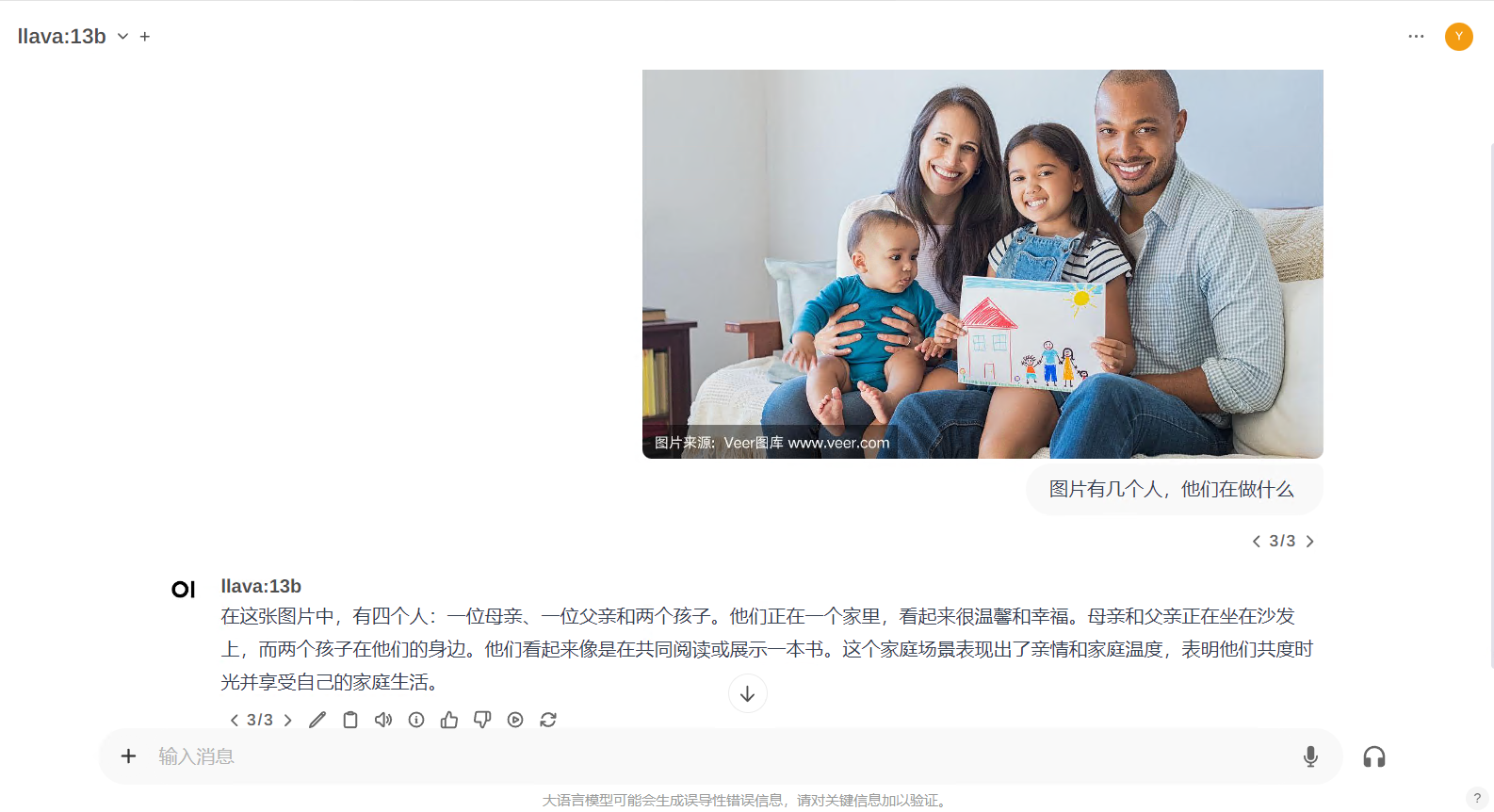
llava:13B:
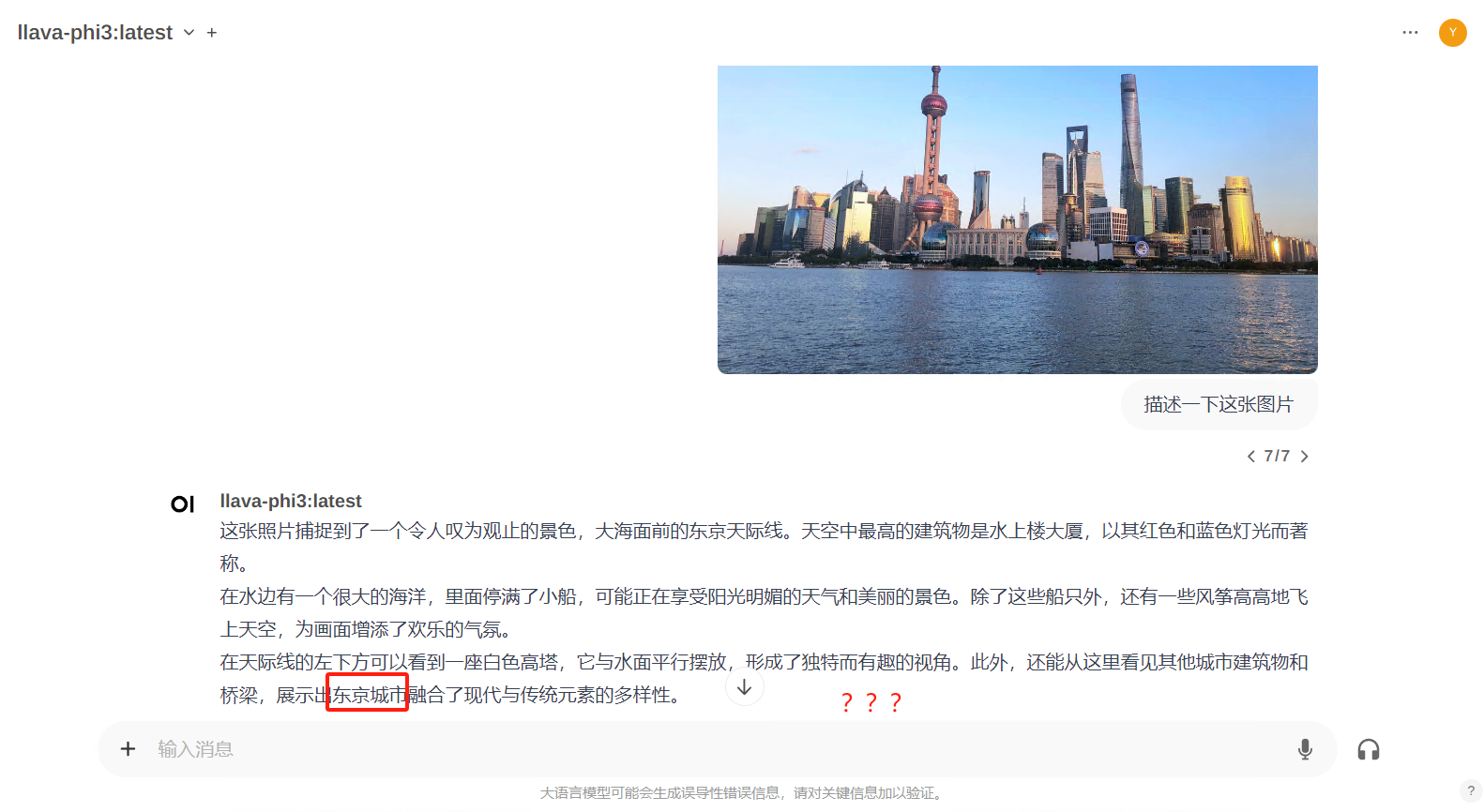
llava-phi3:

整体测试下来,llava比较慢,有可能和我机器有关,有可能模型参数太多,但是准确率没得话说,缺点也有,很容易英文回复
而llava-ph3虽然模型精炼,但是准确率和速度都非常慢,也很容易英文回复,那么在对比一下
chatgpt


没得话说,其他的大模型多模态还需努努力呀,这已经是最新的开源大模型了,差距还是很明显的,不太实用,甚至可以说是垃圾