开篇
记录一下自己对卷积神经网络进行句子分类情况的实现,国外研究情况:
- Kim在Theano中的实现: https://github.com/yoonkim/CNN_sentence
- Denny Britz在Tensorflow中的实现: https://github.com/dennybritz/cnn-text-classification-tf
- Alexander Rakhlin在Keras中的实现: https://github.com/alexander-rakhlin/CNN-for-Sentence-Classification-in-Keras
由于他们都大致实现过卷积神经网络,我这里就不再去构建模型了,基于已有模型探索一下卷积神经网络怎么做文本情感分析的
要求
- python 3
- pytorch > 0.1
- torchtext > 0.1
- numpy
结果
尝试了两个数据集,MR和SST。
| 数据集 | 类别数 | 我训练的最佳结果 | Kim的论文结果 |
|---|---|---|---|
| MR | 2 | 75.89%(CNN-rand-static) | 76.1%(CNN-rand-nostatic) |
| SST | 5 | 37.60%(CNN-rand-static) | 45.0%(CNN-rand-nostatic) |
还没有认真调整SST的超参数。
用法
bashCopy code
./main.py -h
或者
cssCopy code
python3 main.py -h
训练
bashCopy code
./main.py
会得到以下结果:
yamlCopy codeBatch[100] - loss: 0.655424 acc: 59.3750%
Evaluation - loss: 0.672396 acc: 57.6923%(615/1066)
测试
加载数据时,分别选择MR本地线上SST数据集
train_iter, dev_iter = mr(text_field, label_field, device=-1, repeat=False)
train_iter**,** dev_iter**,** test_iter = sst(text_field**,** label_field**,** device=-1**,** repeat=False)
运行成功后,控制台会打印每一个batch对应的损失精度和准确率,如下图
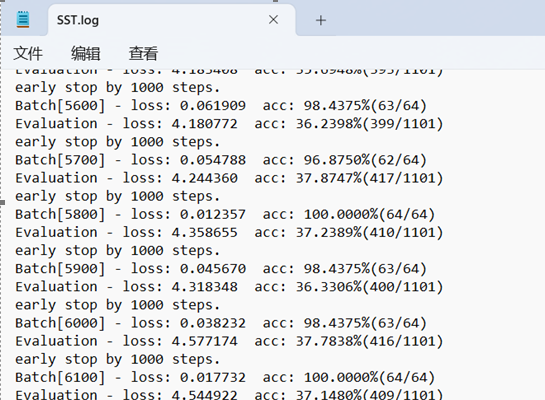
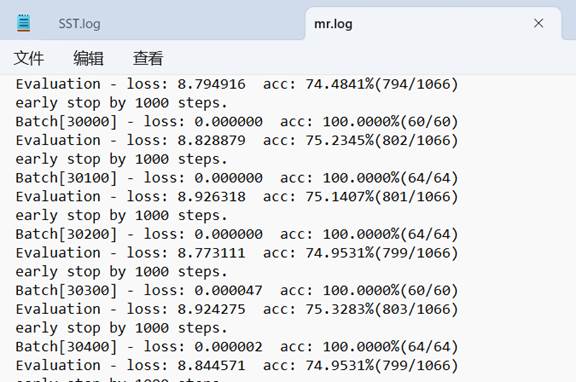
测试好后,每个训练好的mr和sst对应的模型快照目录分别为:
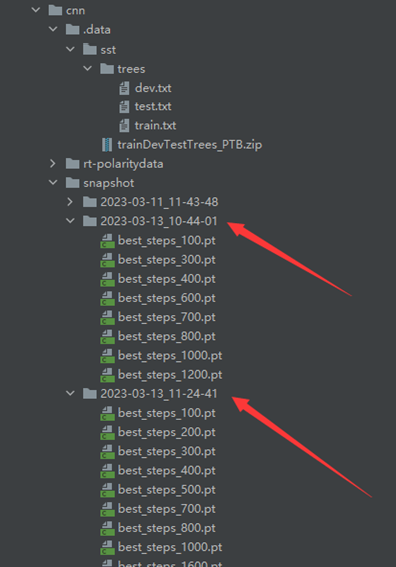
预测
使用mr数据集预测:
注:预测文本必须由空格分隔,即使是标点符号。此外,文本应该比最大卷积核尺寸要长。快照选项表示模型从哪里加载。如果没有指定它,模型将从头开始训练。
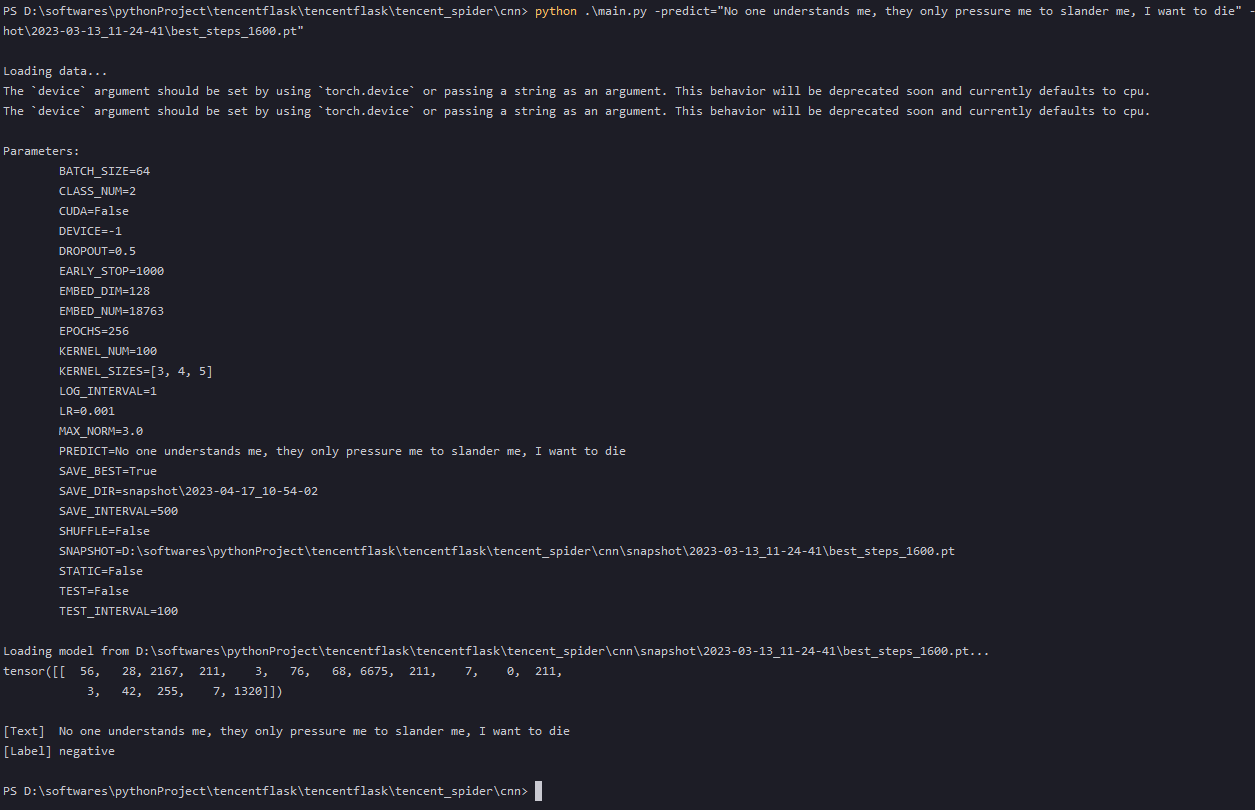
python .\main.py -predict="No one understands me, they only pressure me to slander me, I want to die" -snapshot="D:\softwares\pythonProject\tencentflask\tencentflask\tencent_spider\cnn\snapshot\2023-03-13_11-24-41\best_steps_1600.pt"
预测结果:nagative,如下图所示
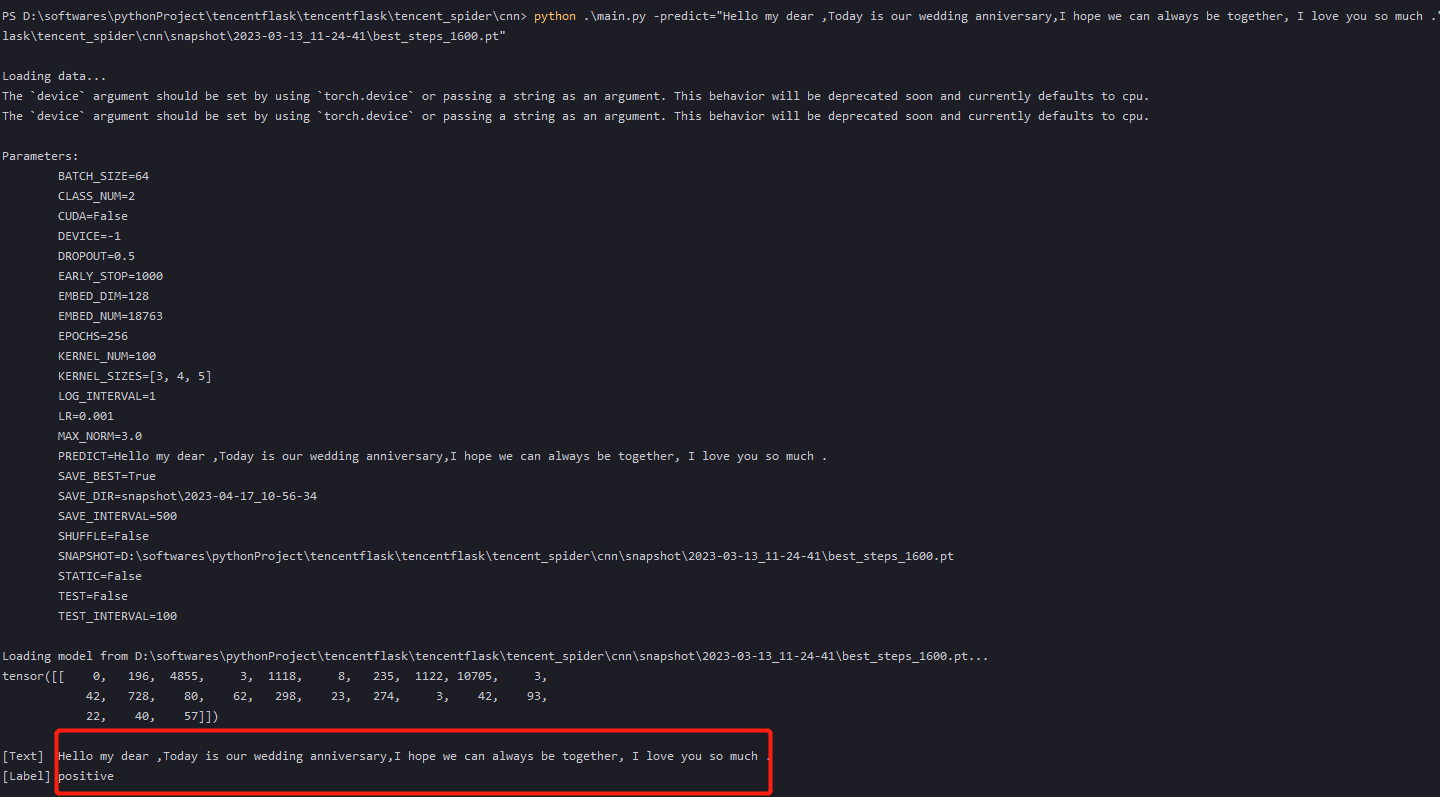
python .\main.py -predict="Hello my dear ,Today is our wedding anniversary,I hope we can always be together, I love you so much ." -snapshot="D:\softwares\pythonProject\tencentflask\tencentflask\tencent_spider\cnn\snapshot\2023-03-13_11-24-41\best_steps_1600.pt"
预测结果:positive,如下图所示
使用sst数据集测试:
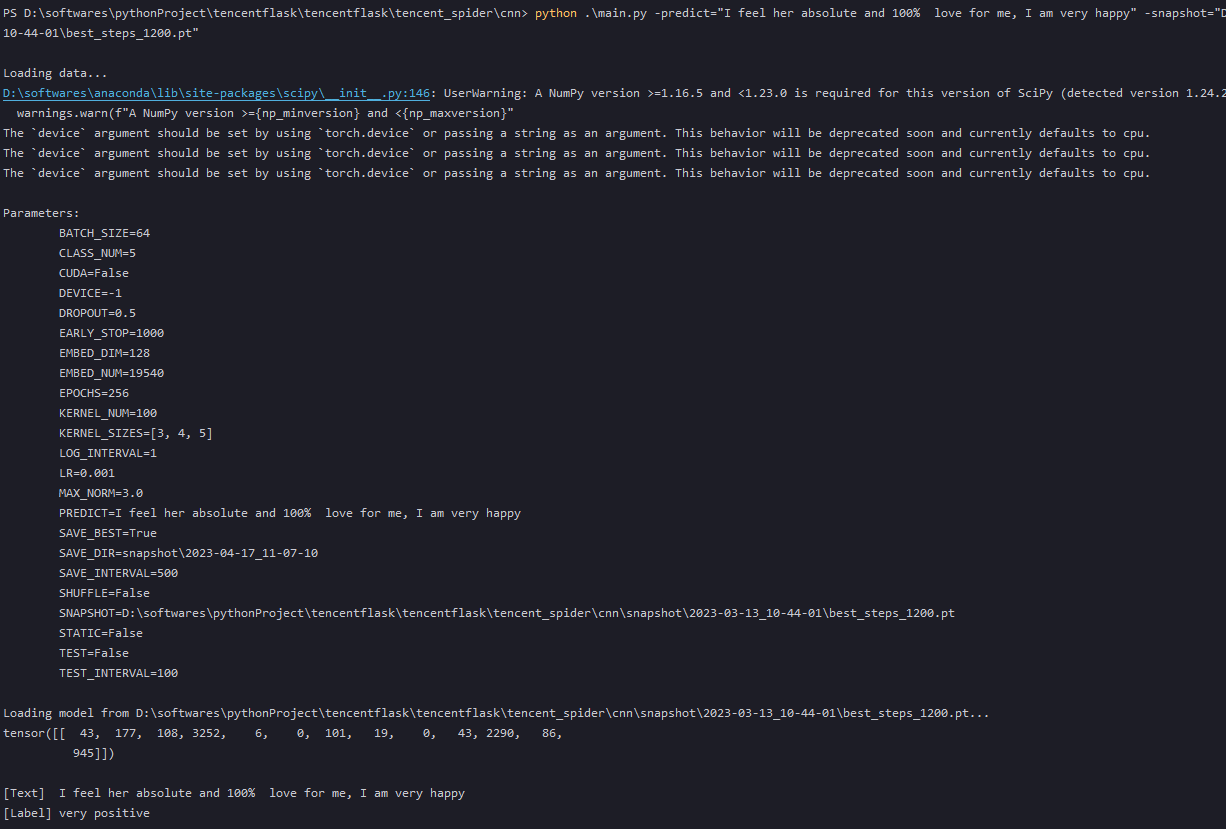
python .\main.py -predict="I feel her absolute and 100% love for me, I am very happy" -snapshot="D:\softwares\pythonProject\tencentflask\tencentflask\tencent_spider\cnn\snapshot\2023-03-13_10-44-01\best_steps_1200.pt"
预测结果:very positive,如下图所示
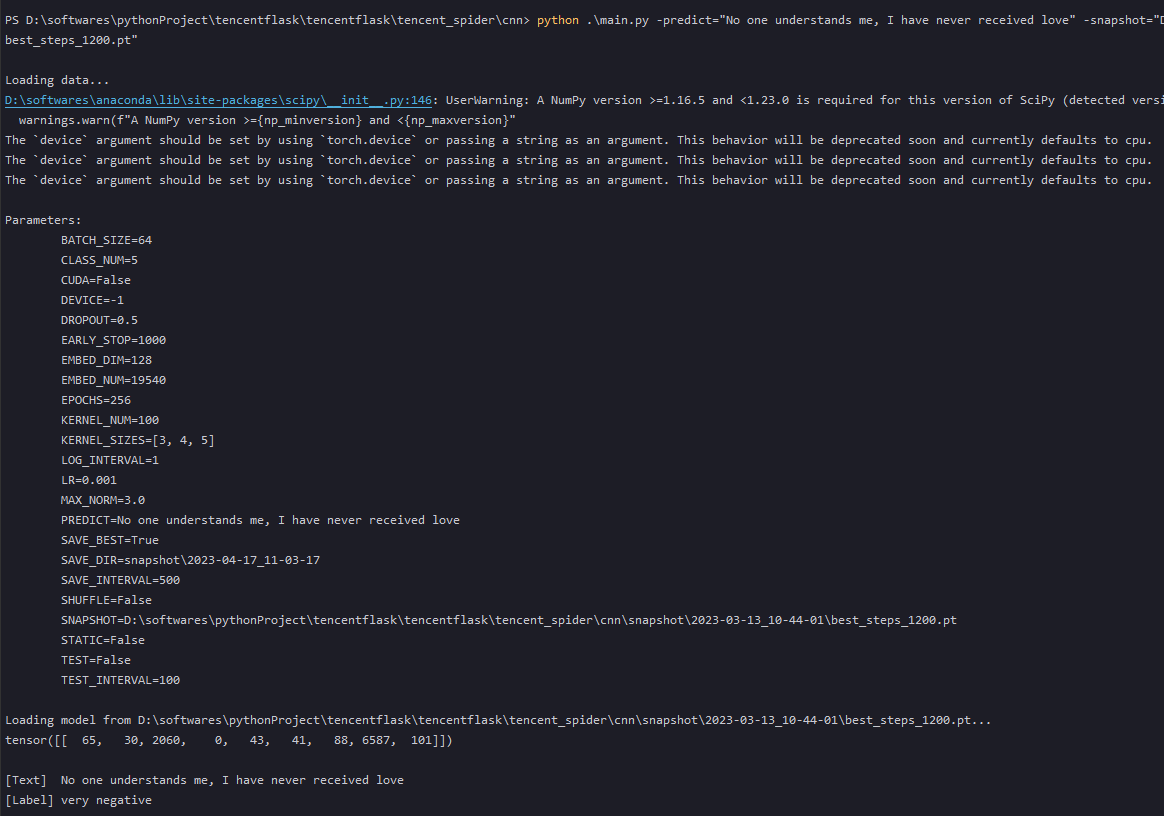
python .\main.py -predict="No one understands me, I have never received love" -snapshot="D:\softwares\pythonProject\tencentflask\tencentflask\tencent_spider\cnn\snapshot\2023-03-13_10-44-01\best_steps_1200.pt"
预测结果:very nagative,如下图所示
具体实现:
main.py
- 导入必要的 Python 库,包括 argparse、os、datetime、torch、torchtext.datasets、model、train 和 mydatasets 等。
- 使用 argparse 库解析命令行参数,包括学习率、训练周期数、批次大小、日志打印周期、测试周期、保存周期、快照保存路径、停止迭代的最大次数、最佳模型保存开关等。
- 定义了两个函数 sst 和 mr,用于加载数据集。其中 sst 函数可以加载 SST 数据集,mr 函数可以加载 MR 数据集。
- 加载数据,并使用 CNN_Text 类实现模型,该模型包含了卷积层和池化层等。模型的输入是一个文本数据集,输出是文本分类结果。
- 对模型进行训练,并对模型进行测试,最终输出训练和测试结果。
#! /usr/bin/env python
import os
import argparse
import datetime
import torch
# from torchtext import data
import torchtext.legacy.data as data
import torchtext.legacy.datasets as datasets
import model
import train
import mydatasets
parser = argparse.ArgumentParser(description='CNN text classificer')
# learning
parser.add_argument('-lr', type=float, default=0.001, help='initial learning rate [default: 0.001]')
parser.add_argument('-epochs', type=int, default=256, help='number of epochs for train [default: 256]')
parser.add_argument('-batch-size', type=int, default=64, help='batch size for training [default: 64]')
parser.add_argument('-log-interval', type=int, default=1, help='how many steps to wait before logging training status [default: 1]')
parser.add_argument('-test-interval', type=int, default=100, help='how many steps to wait before testing [default: 100]')
parser.add_argument('-save-interval', type=int, default=500, help='how many steps to wait before saving [default:500]')
parser.add_argument('-save-dir', type=str, default='snapshot', help='where to save the snapshot')
parser.add_argument('-early-stop', type=int, default=1000, help='iteration numbers to stop without performance increasing')
parser.add_argument('-save-best', type=bool, default=True, help='whether to save when get best performance')
# data
parser.add_argument('-shuffle', action='store_true', default=False, help='shuffle the data every epoch')
# model
parser.add_argument('-dropout', type=float, default=0.5, help='the probability for dropout [default: 0.5]')
parser.add_argument('-max-norm', type=float, default=3.0, help='l2 constraint of parameters [default: 3.0]')
parser.add_argument('-embed-dim', type=int, default=128, help='number of embedding dimension [default: 128]')
parser.add_argument('-kernel-num', type=int, default=100, help='number of each kind of kernel')
parser.add_argument('-kernel-sizes', type=str, default='3,4,5', help='comma-separated kernel size to use for convolution')
parser.add_argument('-static', action='store_true', default=False, help='fix the embedding')
# device
parser.add_argument('-device', type=int, default=-1, help='device to use for iterate data, -1 mean cpu [default: -1]')
parser.add_argument('-no-cuda', action='store_true', default=False, help='disable the gpu')
# option
parser.add_argument('-snapshot', type=str, default=None, help='filename of model snapshot [default: None]')
parser.add_argument('-predict', type=str, default=None, help='predict the sentence given')
parser.add_argument('-test', action='store_true', default=False, help='train or test')
args = parser.parse_args()
# load SST dataset
def sst(text_field, label_field, **kargs):
train_data, dev_data, test_data = datasets.SST.splits(text_field, label_field, fine_grained=True)
text_field.build_vocab(train_data, dev_data, test_data)
label_field.build_vocab(train_data, dev_data, test_data)
train_iter, dev_iter, test_iter = data.BucketIterator.splits(
(train_data, dev_data, test_data),
batch_sizes=(args.batch_size,
len(dev_data),
len(test_data)),
**kargs)
return train_iter, dev_iter, test_iter
# load MR dataset
def mr(text_field, label_field, **kargs):
train_data, dev_data = mydatasets.MR.splits(text_field, label_field)
text_field.build_vocab(train_data, dev_data)
label_field.build_vocab(train_data, dev_data)
train_iter, dev_iter = data.Iterator.splits(
(train_data, dev_data),
batch_sizes=(args.batch_size, len(dev_data)),
**kargs)
return train_iter, dev_iter
# load data
print("\nLoading data...")
text_field = data.Field(lower=True)
label_field = data.Field(sequential=False)
# train_iter, dev_iter = mr(text_field, label_field, device=-1, repeat=False)
train_iter, dev_iter, test_iter = sst(text_field, label_field, device=-1, repeat=False)
#
# update args and print
args.embed_num = len(text_field.vocab)
args.class_num = len(label_field.vocab) - 1
args.cuda = (not args.no_cuda) and torch.cuda.is_available(); del args.no_cuda
args.kernel_sizes = [int(k) for k in args.kernel_sizes.split(',')]
args.save_dir = os.path.join(args.save_dir, datetime.datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
print("\nParameters:")
for attr, value in sorted(args.__dict__.items()):
print("\t{}={}".format(attr.upper(), value))
# model
cnn = model.CNN_Text(args)
if args.snapshot is not None:
print('\nLoading model from {}...'.format(args.snapshot))
cnn.load_state_dict(torch.load(args.snapshot))
if args.cuda:
torch.cuda.set_device(args.device)
cnn = cnn.cuda()
# train or predict
if args.predict is not None:
label = train.predict(args.predict, cnn, text_field, label_field, args.cuda)
print('\n[Text] {}\n[Label] {}\n'.format(args.predict, label))
elif args.test:
try:
train.eval(test_iter, cnn, args)
except Exception as e:
print("\nSorry. The test dataset doesn't exist.\n")
else:
print()
try:
train.train(train_iter, dev_iter, cnn, args)
except KeyboardInterrupt:
print('\n' + '-' * 89)
print('Exiting from training early')
model.py
- 首先导入 PyTorch 库,包括 nn、functional 和 Variable 等模块。
- 定义了一个名为 CNN_Text 的类,继承自 nn.Module 类,因此这是一个 PyTorch 模型。
- 在初始化方法 init 中,定义了模型的各个超参数,包括词汇表大小、嵌入维度、类别数量、卷积核数量、卷积核大小等。
- 定义了一个词嵌入层 self.embed,用于将输入的文本转换为向量表示。
- 定义了多个卷积层 self.convs,每个卷积层包含一个卷积核和一个 ReLU 激活函数。
- 定义了一个 dropout 层 self.dropout,用于在训练过程中随机丢弃一部分神经元,以防止过拟合。
- 定义了一个全连接层 self.fc1,将所有卷积层的输出连接起来并映射到类别数量。
- 在前向传播方法 forward 中,首先将输入的文本通过词嵌入层转换为向量表示。
- 然后将向量表示转换为 4D 张量,作为卷积层的输入,其中第二个维度表示通道数,因为这里只有一个通道,所以为 1。
- 对每个卷积层进行卷积运算,并使用 ReLU 激活函数进行非线性变换。
- 对每个卷积层的输出进行最大池化操作,得到一个向量表示。
- 将所有卷积层的输出连接起来,得到一个维度为 len(Ks)*Co 的向量。
- 使用 dropout 层随机丢弃一部分神经元,以防止过拟合。
- 最后将向量表示通过全连接层映射到类别数量,得到预测结果。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class CNN_Text(nn.Module):
def __init__(self, args):
super(CNN_Text, self).__init__()
self.args = args
V = args.embed_num
D = args.embed_dim
C = args.class_num
Ci = 1
Co = args.kernel_num
Ks = args.kernel_sizes
self.embed = nn.Embedding(V, D)
self.convs = nn.ModuleList([nn.Conv2d(Ci, Co, (K, D)) for K in Ks])
self.dropout = nn.Dropout(args.dropout)
self.fc1 = nn.Linear(len(Ks) * Co, C)
if self.args.static:
self.embed.weight.requires_grad = False
def forward(self, x):
x = self.embed(x) # (N, W, D)
x = x.unsqueeze(1) # (N, Ci, W, D)
x = [F.relu(conv(x)).squeeze(3) for conv in self.convs] # [(N, Co, W), ...]*len(Ks)
x = [F.max_pool1d(i, i.size(2)).squeeze(2) for i in x] # [(N, Co), ...]*len(Ks)
x = torch.cat(x, 1)
x = self.dropout(x) # (N, len(Ks)*Co)
logit = self.fc1(x) # (N, C)
return logit
train.py
使用PyTorch深度学习框架,并定义了四个函数:train(训练函数)、eval(评估函数)、predict(预测函数)和save(保存函数)。
train(train_iter, dev_iter, model, args): 训练函数,接收训练数据迭代器、验证数据迭代器、模型和一些参数作为输入。使用Adam优化器对模型进行训练,计算交叉熵损失和精度,并在达到一定步数后保存模型和输出训练日志。eval(data_iter, model, args): 评估函数,接收数据迭代器、模型和一些参数作为输入。用来评估模型的性能,计算损失和精度。predict(text, model, text_field, label_feild, cuda_flag): 预测函数,接收一个文本字符串、模型、文本域、标签域和一个CUDA标志作为输入。将输入文本转换为模型的输入格式,使用模型进行推理,并返回预测标签。save(model, save_dir, save_prefix, steps): 保存模型函数,接收模型、保存目录、保存前缀和步数作为输入。将模型参数保存在指定路径下。
其他的变量包括import语句导入了需要使用的库,torch.cuda和torch.autograd分别用于控制GPU的使用和计算图构建,F.cross_entropy()是交叉熵损失函数,optimizer是Adam优化器,args是一些超参数和训练参数的集合,用于控制模型的训练过程。
import os
import sys
import torch
import torch.autograd as autograd
import torch.nn.functional as F
def train(train_iter, dev_iter, model, args):
if args.cuda:
model.cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
steps = 0
best_acc = 0
last_step = 0
for epoch in range(1, args.epochs+1):
for batch in train_iter:
model.train()
feature, target = batch.text, batch.label
feature.t_(), target.sub_(1) # batch first, index align
if args.cuda:
feature, target = feature.cuda(), target.cuda()
optimizer.zero_grad()
logit = model(feature)
loss = F.cross_entropy(logit, target)
loss.backward()
optimizer.step()
steps += 1
if steps % args.log_interval == 0:
corrects = (torch.max(logit, 1)[1].view(target.size()).data == target.data).sum()
accuracy = 100.0 * corrects/batch.batch_size
sys.stdout.write(
'\rBatch[{}] - loss: {:.6f} acc: {:.4f}%({}/{})'.format(steps,
loss.item(),
accuracy.item(),
corrects.item(),
batch.batch_size))
if steps % args.test_interval == 0:
dev_acc = eval(dev_iter, model, args)
if dev_acc > best_acc:
best_acc = dev_acc
last_step = steps
if args.save_best:
save(model, args.save_dir, 'best', steps)
else:
if steps - last_step >= args.early_stop:
print('early stop by {} steps.'.format(args.early_stop))
elif steps % args.save_interval == 0:
save(model, args.save_dir, 'snapshot', steps)
def eval(data_iter, model, args):
model.eval()
corrects, avg_loss = 0, 0
for batch in data_iter:
feature, target = batch.text, batch.label
feature.t_(), target.sub_(1) # batch first, index align
if args.cuda:
feature, target = feature.cuda(), target.cuda()
logit = model(feature)
loss = F.cross_entropy(logit, target, size_average=False)
avg_loss += loss.item()
corrects += (torch.max(logit, 1)
[1].view(target.size()).data == target.data).sum()
size = len(data_iter.dataset)
avg_loss /= size
accuracy = 100.0 * corrects/size
print('\nEvaluation - loss: {:.6f} acc: {:.4f}%({}/{}) \n'.format(avg_loss,
accuracy,
corrects,
size))
return accuracy
def predict(text, model, text_field, label_feild, cuda_flag):
assert isinstance(text, str)
model.eval()
# text = text_field.tokenize(text)
text = text_field.preprocess(text)
text = [[text_field.vocab.stoi[x] for x in text]]
x = torch.tensor(text)
x = autograd.Variable(x)
if cuda_flag:
x = x.cuda()
print(x)
output = model(x)
_, predicted = torch.max(output, 1)
return label_feild.vocab.itos[predicted.item()+1]
def save(model, save_dir, save_prefix, steps):
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
save_prefix = os.path.join(save_dir, save_prefix)
save_path = '{}_steps_{}.pt'.format(save_prefix, steps)
torch.save(model.state_dict(), save_path)
mydatasets.py
定义了一个叫做 MR 的类,它是 TarDataset 类的子类,表示了在可下载的 tar 文件中读取文本分类数据集 MR 的过程。
TarDataset 类是用来处理 tar 文件的一个自定义的数据集类,通过继承它,MR 类可以直接使用 TarDataset 类中的 download_or_unzip 方法下载数据集,并使用其中的 url、filename 和 dirname 属性指定下载链接、文件名和目录名。
MR 类的 __init__ 方法接收 text_field 和 label_field 两个参数,用于指定文本数据和标签数据的字段类型,以及 path 和 examples 参数,用于指定数据文件的路径和数据样例。在 __init__ 方法中,它使用 open 函数读取 tar 文件中的 rt-polarity.neg 和 rt-polarity.pos 两个文件,读取后使用 data.Example.fromlist 方法将每个数据样例处理为一个 Example 对象,并将其加入到 examples 列表中,最终通过调用父类 data.Dataset 的 __init__ 方法完成实例化过程。
MR 类的 splits 方法用于根据指定的数据集划分比例,返回包含训练集和验证集的元组。在该方法中,先使用 download_or_unzip 方法下载数据集并使用 __init__ 方法读取所有数据样例,然后使用 random.shuffle 方法将样例顺序打乱,最后根据 dev_ratio 参数指定的比例将样例划分为训练集和验证集,返回一个元组。
import re
import os
import random
import tarfile
import urllib
from torchtext import legacy
# import torchtext.data as data
import torchtext.legacy.data as data
class TarDataset(legacy.data.Dataset):
@classmethod
def download_or_unzip(cls, root):
path = os.path.join(root, cls.dirname)
if not os.path.isdir(path):
tpath = os.path.join(root, cls.filename)
if not os.path.isfile(tpath):
print('downloading')
urllib.request.urlretrieve(cls.url, tpath)
with tarfile.open(tpath, 'r') as tfile:
print('extracting')
tfile.extractall(root)
return os.path.join(path, '')
class MR(TarDataset):
url = 'https://www.cs.cornell.edu/people/pabo/movie-review-data/rt-polaritydata.tar.gz'
filename = 'rt-polaritydata.tar.gz'
dirname = 'rt-polaritydata'
@staticmethod
def sort_key(ex):
return len(ex.text)
def __init__(self, text_field, label_field, path=None, examples=None, **kwargs):
def clean_str(string):
string = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", string)
string = re.sub(r"\'s", " \'s", string)
string = re.sub(r"\'ve", " \'ve", string)
string = re.sub(r"n\'t", " n\'t", string)
string = re.sub(r"\'re", " \'re", string)
string = re.sub(r"\'d", " \'d", string)
string = re.sub(r"\'ll", " \'ll", string)
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", " \( ", string)
string = re.sub(r"\)", " \) ", string)
string = re.sub(r"\?", " \? ", string)
string = re.sub(r"\s{2,}", " ", string)
return string.strip()
text_field.tokenize = lambda x: clean_str(x).split()
fields = [('text', text_field), ('label', label_field)]
if examples is None:
path = self.dirname if path is None else path
examples = []
with open(os.path.join(path, 'rt-polarity.neg'), errors='ignore') as f:
examples += [
data.Example.fromlist([line, 'negative'], fields) for line in f]
with open(os.path.join(path, 'rt-polarity.pos'), errors='ignore') as f:
examples += [
data.Example.fromlist([line, 'positive'], fields) for line in f]
super(MR, self).__init__(examples, fields, **kwargs)
@classmethod
def splits(cls, text_field, label_field, dev_ratio=.1, shuffle=True, root='.', **kwargs):
path = cls.download_or_unzip(root)
examples = cls(text_field, label_field, path=path, **kwargs).examples
if shuffle: random.shuffle(examples)
dev_index = -1 * int(dev_ratio*len(examples))
return (cls(text_field, label_field, examples=examples[:dev_index]),
cls(text_field, label_field, examples=examples[dev_index:]))
遇到的问题:
一:版本问题
AttributeError: module 'torchtext.data' has no attribute 'Iterator'
AttributeError: module 'torchtext.data' has no attribute 'Dataset'
AttributeError: module 'torchtext.data' has no attribute 'Field'
AttributeError: module 'torchtext.data' has no attribute 'Example'
由于安装的版本torchtext为0.9.1,在torchtext0.9以上移除了Dataset,和Field,所以
# from torchtext import data修改为
from torchtext.legacy import data
# import torchtext.data as data修改为
import torchtext.legacy.data as data
二:下载超时问题
requests.exceptions.ProxyError: HTTPConnectionPool(host='127.0.0.1', port=10809): Max retries exceeded with url: http://nlp.stanford.edu/sentiment/trainDevTestTrees_PTB.zip (Caused by ProxyError('Cannot connect to proxy.', NewConnectionError('<urllib3.connection.HTTPConnection object at 0x000001E31A477BB0>: Failed to establish a new connection: [WinError 10061] 由于目标计算机积极拒绝,无法连接。')))
这个是因为短时间内请求多次导致的,解决办法等一会儿,或者使用代理ip去请求
三:缺少文件问题
使用sst模型快照去预测的时候,报如下错误
ImportError: DLL load failed while importing _sqlite3: 找不到指定的模块。
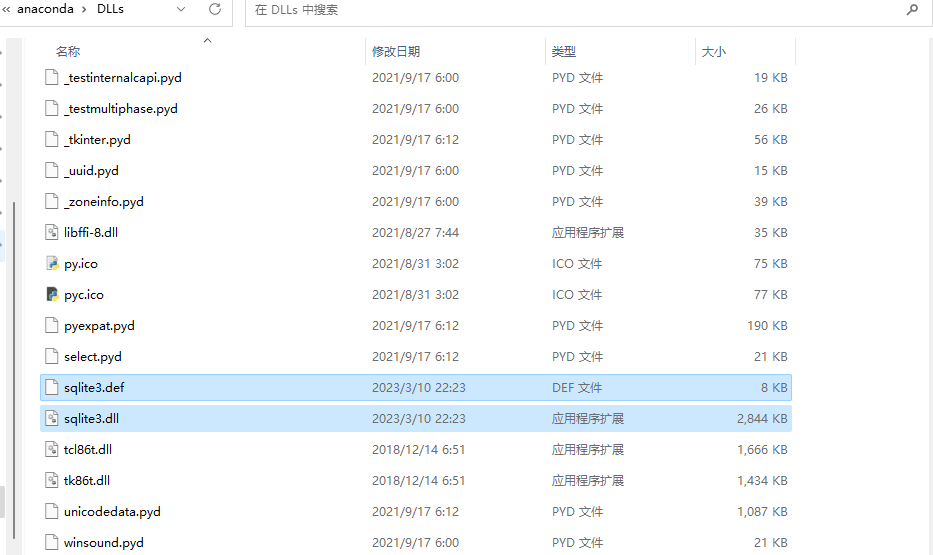
由于缺少 sqlite3.dll 文件或者系统路径中没有找到该文件导致的。,在https://www.sqlite.org/download.html 下载好
解压后丢到anaconda的目录DDl里面