
第一章:爬虫原理和数据爬取
1.1 通用爬虫和聚焦爬虫
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种.
通用爬虫
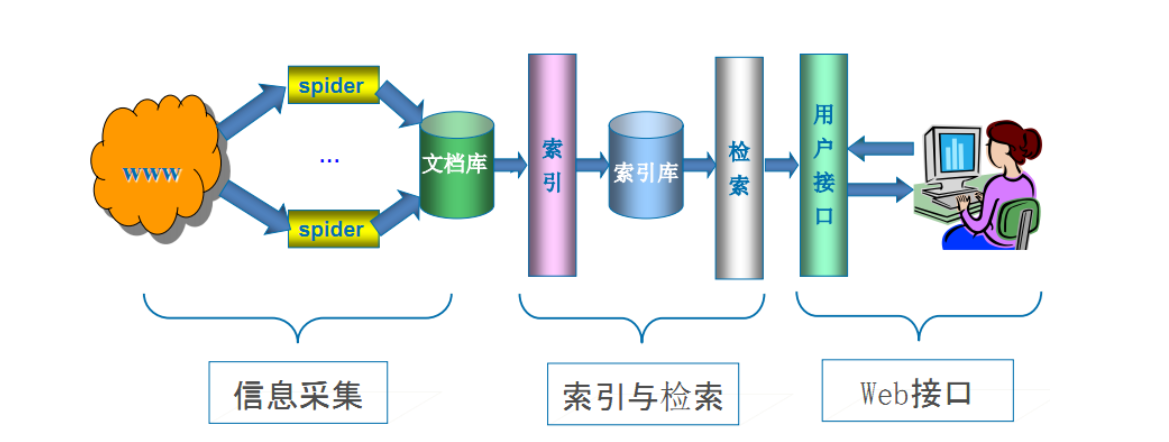
通用网络爬虫 是 捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
通用搜索引擎(Search Engine)工作原理:
通用网络爬虫 从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。
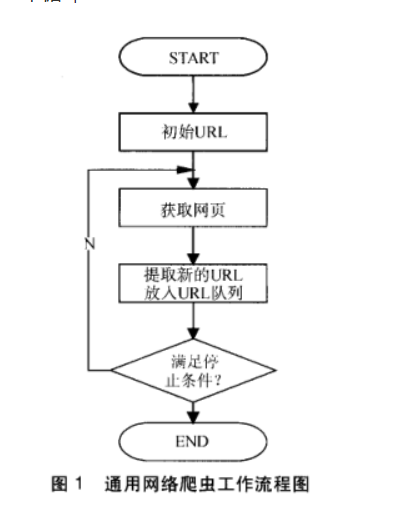
第一步:抓取网页
搜索引擎网络爬虫的基本工作流程如下:
-
首先选取一部分的种子URL,将这些URL放入待抓取URL队列;
-
取出待抓取URL,解析DNS得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中,并且将这些URL放进已抓取URL队列。
-
分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环…
搜索引擎如何获取一个新网站的URL:
-
新网站向搜索引擎主动提交网址:(如百度http://zhanzhang.baidu.com/linksubmit/url)
-
在其他网站上设置新网站外链(尽可能处于搜索引擎爬虫爬取范围)
-
搜索引擎和DNS解析服务商(如DNSPod等)合作,新网站域名将被迅速抓取。
但是搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件的内容,如标注为nofollow的链接,或者是Robots协议。
Robots协议(也叫爬虫协议、机器人协议等),全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,例如:
第二步:数据存储
搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。
搜索引擎蜘蛛在抓取页面时,也做一定的重复内容检测,一旦遇到访问权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不再爬行。
第三步:预处理
搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理。
- 提取文字
- 中文分词
- 消除噪音(比如版权声明文字、导航条、广告等……)
- 索引处理
- 链接关系计算
- 特殊文件处理
- …
除了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型。
但搜索引擎还不能处理图片、视频、Flash 这类非文字内容,也不能执行脚本和程序。
第四步:提供检索服务,网站排名
搜索引擎在对信息进行组织和处理后,为用户提供关键字检索服务,将用户检索相关的信息展示给用户。
同时会根据页面的PageRank值(链接的访问量排名)来进行网站排名,这样Rank值高的网站在搜索结果中会排名较前,当然也可以直接使用 Money 购买搜索引擎网站排名,简单粗暴。
课外阅读:Google搜索引擎的工作原理
但是,这些通用性搜索引擎也存在着一定的局限性:
- 通用搜索引擎所返回的结果都是网页,而大多情况下,网页里90%的内容对用户来说都是无用的。
- 不同领域、不同背景的用户往往具有不同的检索目的和需求,搜索引擎无法提供针对具体某个用户的搜索结果。
- 万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎对这些文件无能为力,不能很好地发现和获取。
- 通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询,无法准确理解用户的具体需求。
针对这些情况,聚焦爬虫技术得以广泛使用。
聚焦爬虫
聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
而下面的要学的网络爬虫,就是聚焦爬虫。
1.2 HTTP和HTTPS
HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法。
HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,在HTTP下加入SSL层。
SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
HTTP的端口号为80,HTTPS的端口号为443
HTTP的请求与响应
HTTP通信由两部分组成: 客户端请求消息 与 服务器响应消息
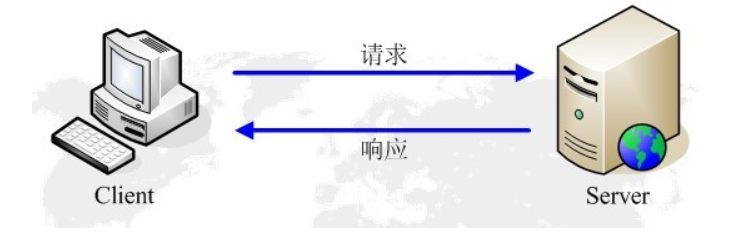
浏览器发送HTTP请求的过程:
- 当用户在浏览器的地址栏中输入一个URL并按回车键之后,浏览器会向HTTP服务器发送HTTP请求。HTTP请求主要分为“Get”和“Post”两种方法。
- 当我们在浏览器输入URL http://www.baidu.com 的时候,浏览器发送一个Request请求去获取 http://www.baidu.com 的html文件,服务器把Response文件对象发送回给浏览器。
- 浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。 浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
- 当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
URL(Uniform / Universal Resource Locator的缩写):统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种标识方法。
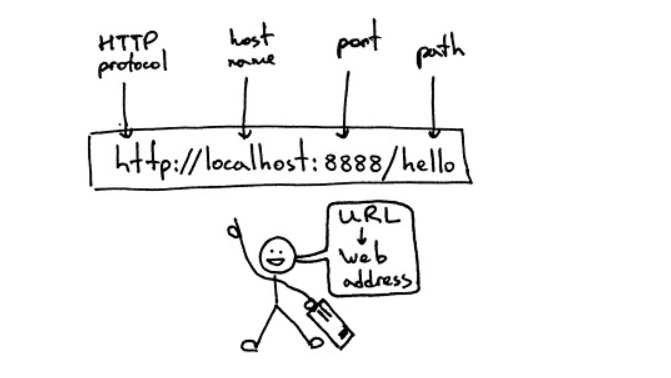
基本格式:scheme://host[:port#]/path/…/[?query-string][#anchor]
- scheme:协议(例如:http, https, ftp)
- host:服务器的IP地址或者域名
- port#:服务器的端口(如果是走协议默认端口,缺省端口80)
- path:访问资源的路径
- query-string:参数,发送给http服务器的数据
- anchor:锚(跳转到网页的指定锚点位置)
例如:
客户端HTTP请求
URL只是标识资源的位置,而HTTP是用来提交和获取资源。客户端发送一个HTTP请求到服务器的请求消息,包括以下格式:
请求行`、`请求头部`、`空行`、`请求数据
四个部分组成,下图给出了请求报文的一般格式。
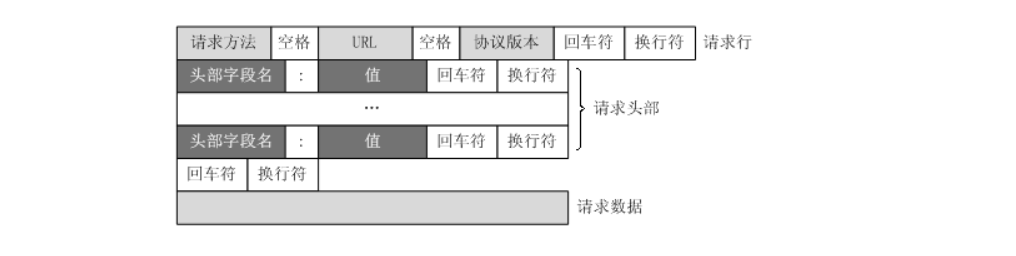
一个典型的HTTP请求示例
GET https://www.baidu.com/ HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Referer: http://www.baidu.com/
Accept-Encoding: gzip, deflate, sdch, br
Accept-Language: zh-CN,zh;q=0.8,en;q=0.6
Cookie: BAIDUID=04E4001F34EA74AD4601512DD3C41A7B:FG=1; BIDUPSID=04E4001F34EA74AD4601512DD3C41A7B; PSTM=1470329258; MCITY=-343%3A340%3A; BDUSS=nF0MVFiMTVLcUh-Q2MxQ0M3STZGQUZ4N2hBa1FFRkIzUDI3QlBCZjg5cFdOd1pZQVFBQUFBJCQAAAAAAAAAAAEAAADpLvgG0KGyvLrcyfrG-AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFaq3ldWqt5XN; H_PS_PSSID=1447_18240_21105_21386_21454_21409_21554; BD_UPN=12314753; sug=3; sugstore=0; ORIGIN=0; bdime=0; H_PS_645EC=7e2ad3QHl181NSPbFbd7PRUCE1LlufzxrcFmwYin0E6b%2BW8bbTMKHZbDP0g; BDSVRTM=0
请求方法
GET https://www.baidu.com/ HTTP/1.1
根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP 0.9:只有基本的文本 GET 功能。
HTTP 1.0:完善的请求/响应模型,并将协议补充完整,定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP 1.1:在 1.0 基础上进行更新,新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
HTTP 2.0(未普及):请求/响应首部的定义基本没有改变,只是所有首部键必须全部小写,而且请求行要独立为 :method、:scheme、:host、:path这些键值对。
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体。 |
| 2 | HEAD | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件),数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| 5 | DELETE | 请求服务器删除指定的页面。 |
| 6 | CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
HTTP请求主要分为Get和Post两种方法
- GET是从服务器上获取数据,POST是向服务器传送数据
- GET请求参数显示,都显示在浏览器网址上,HTTP服务器根据该请求所包含URL中的参数来产生响应内容,即“Get”请求的参数是URL的一部分。 例如:
http://www.baidu.com/s?wd=Chinese - POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送,通常用来向HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传操作等),请求的参数包含在“Content-Type”消息头里,指明该消息体的媒体类型和编码,
注意:避免使用Get方式提交表单,因为有可能会导致安全问题。 比如说在登陆表单中用Get方式,用户输入的用户名和密码将在地址栏中暴露无遗。
常用的请求报头
- Host (主机和端口号)
Host:对应网址URL中的Web名称和端口号,用于指定被请求资源的Internet主机和端口号,通常属于URL的一部分。
- Connection (链接类型)
Connection:表示客户端与服务连接类型
- Client 发起一个包含
Connection:keep-alive的请求,HTTP/1.1使用keep-alive为默认值。 - Server收到请求后:
- 如果 Server 支持 keep-alive,回复一个包含 Connection:keep-alive 的响应,不关闭连接;
- 如果 Server 不支持 keep-alive,回复一个包含 Connection:close 的响应,关闭连接。
- 如果client收到包含
Connection:keep-alive的响应,向同一个连接发送下一个请求,直到一方主动关闭连接
keep-alive在很多情况下能够重用连接,减少资源消耗,缩短响应时间,比如当浏览器需要多个文件时(比如一个HTML文件和相关的图形文件),不需要每次都去请求建立连接。
- Upgrade-Insecure-Requests (升级为HTTPS请求)
Upgrade-Insecure-Requests:升级不安全的请求,意思是会在加载 http 资源时自动替换成 https 请求,让浏览器不再显示https页面中的http请求警报。
*HTTPS 是以安全为目标的 HTTP 通道,所以在 HTTPS 承载的页面上不允许出现 HTTP 请求,一旦出现就是提示或报错。*
- User-Agent (浏览器名称)
User-Agent:是客户浏览器的名称,以后会详细讲。
- Accept (传输文件类型)
Accept:指浏览器或其他客户端可以接受的MIME(Multipurpose Internet Mail Extensions(多用途互联网邮件扩展))文件类型,服务器可以根据它判断并返回适当的文件格式。
举例:
Accept: */*:表示什么都可以接收。
Accept:image/gif:表明客户端希望接受GIF图像格式的资源;
Accept:text/html:表明客户端希望接受html文本。
Accept: text/html, application/xhtml+xml;q=0.9, image/*;q=0.8:表示浏览器支持的 MIME 类型分别是 html文本、xhtml和xml文档、所有的图像格式资源。
*q是权重系数,范围 0 =< q <= 1,q 值越大,请求越倾向于获得其“;”之前的类型表示的内容。若没有指定q值,则默认为1,按从左到右排序顺序;若被赋值为0,则用于表示浏览器不接受此内容类型。*
*Text:用于标准化地表示的文本信息,文本消息可以是多种字符集和或者多种格式的;Application:用于传输应用程序数据或者二进制数据。详细请点击*
- Referer (页面跳转处)
Referer:表明产生请求的网页来自于哪个U
RL,用户是从该 Referer页面访问到当前请求的页面。这个属性可以用来跟踪Web请求来自哪个页面,是从什么网站来的等。
有时候遇到下载某网站图片,需要对应的referer,否则无法下载图片,那是因为人家做了防盗链,原理就是根据referer去判断是否是本网站的地址,如果不是,则拒绝,如果是,就可以下载;
- Accept-Encoding(文件编解码格式)
Accept-Encoding:指出浏览器可以接受的编码方式。编码方式不同于文件格式,它是为了压缩文件并加速文件传递速度。浏览器在接收到Web响应之后先解码,然后再检查文件格式,许多情形下这可以减少大量的下载时间。
举例:Accept-Encoding:gzip;q=1.0, identity; q=0.5, *;q=0
如果有多个Encoding同时匹配, 按照q值顺序排列,本例中按顺序支持 gzip, identity压缩编码,支持gzip的浏览器会返回经过gzip编码的HTML页面。 如果请求消息中没有设置这个域服务器假定客户端对各种内容编码都可以接受。
- Accept-Language(语言种类)
Accept-Langeuage:指出浏览器可以接受的语言种类,如en或en-us指英语,zh或者zh-cn指中文,当服务器能够提供一种以上的语言版本时要用到。
- Accept-Charset(字符编码)
Accept-Charset:指出浏览器可以接受的字符编码。
举例:Accept-Charset:iso-8859-1,gb2312,utf-8
- ISO8859-1:通常叫做Latin-1。Latin-1包括了书写所有西方欧洲语言不可缺少的附加字符,英文浏览器的默认值是ISO-8859-1.
- gb2312:标准简体中文字符集;
- utf-8:UNICODE 的一种变长字符编码,可以解决多种语言文本显示问题,从而实现应用国际化和本地化。
如果在请求消息中没有设置这个域,缺省是任何字符集都可以接受。
- Cookie (Cookie)
Cookie:浏览器用这个属性向服务器发送Cookie。Cookie是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息,也可以用来实现会话功能,以后会详细讲。
- Content-Type (POST数据类型)
Content-Type:POST请求里用来表示的内容类型。
举例:Content-Type = Text/XML; charset=gb2312:
指明该请求的消息体中包含的是纯文本的XML类型的数据,字符编码采用“gb2312”。
服务端HTTP响应
HTTP响应也由四个部分组成,分别是: 状态行、消息报头、空行、响应正文
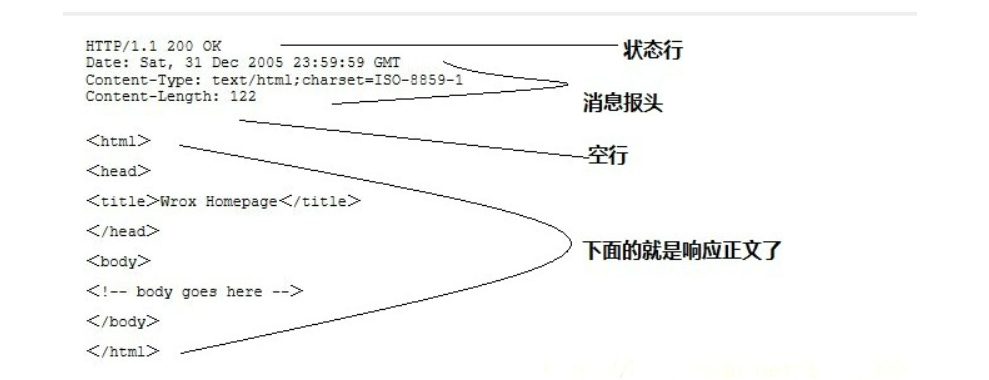
HTTP/1.1 200 OK
Server: Tengine
Connection: keep-alive
Date: Wed, 30 Nov 2016 07:58:21 GMT
Cache-Control: no-cache
Content-Type: text/html;charset=UTF-8
Keep-Alive: timeout=20
Vary: Accept-Encoding
Pragma: no-cache
X-NWS-LOG-UUID: bd27210a-24e5-4740-8f6c-25dbafa9c395
Content-Length: 180945
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" ....
常用的响应报头(了解)
理论上所有的响应头信息都应该是回应请求头的。但是服务端为了效率,安全,还有其他方面的考虑,会添加相对应的响应头信息,从上图可以看到:
- Cache-Control:must-revalidate, no-cache, private。
这个值告诉客户端,服务端不希望客户端缓存资源,在下次请求资源时,必须要从新请求服务器,不能从缓存副本中获取资源。
- Cache-Control是响应头中很重要的信息,当客户端请求头中包含Cache-Control:max-age=0请求,明确表示不会缓存服务器资源时,Cache-Control作为作为回应信息,通常会返回no-cache,意思就是说,“那就不缓存呗”。
- 当客户端在请求头中没有包含Cache-Control时,服务端往往会定,不同的资源不同的缓存策略,比如说oschina在缓存图片资源的策略就是Cache-Control:max-age=86400,这个意思是,从当前时间开始,在86400秒的时间内,客户端可以直接从缓存副本中读取资源,而不需要向服务器请求。
- Connection:keep-alive
这个字段作为回应客户端的Connection:keep-alive,告诉客户端服务器的tcp连接也是一个长连接,客户端可以继续使用这个tcp连接发送http请求。
- Content-Encoding:gzip
告诉客户端,服务端发送的资源是采用gzip编码的,客户端看到这个信息后,应该采用gzip对资源进行解码。
- Content-Type:text/html;charset=UTF-8
告诉客户端,资源文件的类型,还有字符编码,客户端通过utf-8对资源进行解码,然后对资源进行html解析。通常我们会看到有些网站是乱码的,往往就是服务器端没有返回正确的编码。
- Date:Sun, 21 Sep 2016 06:18:21 GMT
这个是服务端发送资源时的服务器时间,GMT是格林尼治所在地的标准时间。http协议中发送的时间都是GMT的,这主要是解决在互联网上,不同时区在相互请求资源的时候,时间混乱问题。
- Expires:Sun, 1 Jan 2000 01:00:00 GMT
这个响应头也是跟缓存有关的,告诉客户端在这个时间前,可以直接访问缓存副本,很显然这个值会存在问题,因为客户端和服务器的时间不一定会都是相同的,如果时间不同就会导致问题。所以这个响应头是没有Cache-Control:max-age=*这个响应头准确的,因为max-age=date中的date是个相对时间,不仅更好理解,也更准确。
- Pragma:no-cache
这个含义与Cache-Control等同。
8.Server:Tengine/1.4.6
这个是服务器和相对应的版本,只是告诉客户端服务器的信息。
- Transfer-Encoding:chunked
这个响应头告诉客户端,服务器发送的资源的方式是分块发送的。一般分块发送的资源都是服务器动态生成的,在发送时还不知道发送资源的大小,所以采用分块发送,每一块都是独立的,独立的块都能标示自己的长度,最后一块是0长度的,当客户端读到这个0长度的块时,就可以确定资源已经传输完了。
- Vary: Accept-Encoding
告诉缓存服务器,缓存压缩文件和非压缩文件两个版本,现在这个字段用处并不大,因为现在的浏览器都是支持压缩的。
Cookie 和 Session:
服务器和客户端的交互仅限于请求/响应过程,结束之后便断开,在下一次请求时,服务器会认为新的客户端。
为了维护他们之间的链接,让服务器知道这是前一个用户发送的请求,必须在一个地方保存客户端的信息。
Cookie:通过在 客户端 记录的信息确定用户的身份。
Session:通过在 服务器端 记录的信息确定用户的身份。
响应状态码
响应状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。
常见状态码:
100~199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。200~299:表示服务器成功接收请求并已完成整个处理过程。常用200(OK 请求成功)。300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用302(所请求的页面已经临时转移至新的url)、307和304(使用缓存资源)。400~499:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服务器拒绝访问,权限不够)。500~599:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)。
HTTP响应状态码参考:
1xx:信息
100 Continue
服务器仅接收到部分请求,但是一旦服务器并没有拒绝该请求,客户端应该继续发送其余的请求。
101 Switching Protocols
服务器转换协议:服务器将遵从客户的请求转换到另外一种协议。
2xx:成功
200 OK
请求成功(其后是对GET和POST请求的应答文档)
201 Created
请求被创建完成,同时新的资源被创建。
202 Accepted
供处理的请求已被接受,但是处理未完成。
203 Non-authoritative Information
文档已经正常地返回,但一些应答头可能不正确,因为使用的是文档的拷贝。
204 No Content
没有新文档。浏览器应该继续显示原来的文档。如果用户定期地刷新页面,而Servlet可以确定用户文档足够新,这个状态代码是很有用的。
205 Reset Content
没有新文档。但浏览器应该重置它所显示的内容。用来强制浏览器清除表单输入内容。
206 Partial Content
客户发送了一个带有Range头的GET请求,服务器完成了它。
3xx:重定向
300 Multiple Choices
多重选择。链接列表。用户可以选择某链接到达目的地。最多允许五个地址。
301 Moved Permanently
所请求的页面已经转移至新的url。
302 Moved Temporarily
所请求的页面已经临时转移至新的url。
303 See Other
所请求的页面可在别的url下被找到。
304 Not Modified
未按预期修改文档。客户端有缓冲的文档并发出了一个条件性的请求(一般是提供If-Modified-Since头表示客户只想比指定日期更新的文档)。服务器告诉客户,原来缓冲的文档还可以继续使用。
305 Use Proxy
客户请求的文档应该通过Location头所指明的代理服务器提取。
306 Unused
此代码被用于前一版本。目前已不再使用,但是代码依然被保留。
307 Temporary Redirect
被请求的页面已经临时移至新的url。
4xx:客户端错误
400 Bad Request
服务器未能理解请求。
401 Unauthorized
被请求的页面需要用户名和密码。
401.1
登录失败。
401.2
服务器配置导致登录失败。
401.3
由于 ACL 对资源的限制而未获得授权。
401.4
筛选器授权失败。
401.5
ISAPI/CGI 应用程序授权失败。
401.7
访问被 Web 服务器上的 URL 授权策略拒绝。这个错误代码为 IIS 6.0 所专用。
402 Payment Required
此代码尚无法使用。
403 Forbidden
对被请求页面的访问被禁止。
403.1
执行访问被禁止。
403.2
读访问被禁止。
403.3
写访问被禁止。
403.4
要求 SSL。
403.5
要求 SSL 128。
403.6
IP 地址被拒绝。
403.7
要求客户端证书。
403.8
站点访问被拒绝。
403.9
用户数过多。
403.10
配置无效。
403.11
密码更改。
403.12
拒绝访问映射表。
403.13
客户端证书被吊销。
403.14
拒绝目录列表。
403.15
超出客户端访问许可。
403.16
客户端证书不受信任或无效。
403.17
客户端证书已过期或尚未生效。
403.18
在当前的应用程序池中不能执行所请求的 URL。这个错误代码为 IIS 6.0 所专用。
403.19
不能为这个应用程序池中的客户端执行 CGI。这个错误代码为 IIS 6.0 所专用。
403.20
Passport 登录失败。这个错误代码为 IIS 6.0 所专用。
404 Not Found
服务器无法找到被请求的页面。
404.0
没有找到文件或目录。
404.1
无法在所请求的端口上访问 Web 站点。
404.2
Web 服务扩展锁定策略阻止本请求。
404.3
MIME 映射策略阻止本请求。
405 Method Not Allowed
请求中指定的方法不被允许。
406 Not Acceptable
服务器生成的响应无法被客户端所接受。
407 Proxy Authentication Required
用户必须首先使用代理服务器进行验证,这样请求才会被处理。
408 Request Timeout
请求超出了服务器的等待时间。
409 Conflict
由于冲突,请求无法被完成。
410 Gone
被请求的页面不可用。
411 Length Required
"Content-Length" 未被定义。如果无此内容,服务器不会接受请求。
412 Precondition Failed
请求中的前提条件被服务器评估为失败。
413 Request Entity Too Large
由于所请求的实体的太大,服务器不会接受请求。
414 Request-url Too Long
由于url太长,服务器不会接受请求。当post请求被转换为带有很长的查询信息的get请求时,就会发生这种情况。
415 Unsupported Media Type
由于媒介类型不被支持,服务器不会接受请求。
416 Requested Range Not Satisfiable
服务器不能满足客户在请求中指定的Range头。
417 Expectation Failed
执行失败。
423
锁定的错误。
5xx:服务器错误
500 Internal Server Error
请求未完成。服务器遇到不可预知的情况。
500.12
应用程序正忙于在 Web 服务器上重新启动。
500.13
Web 服务器太忙。
500.15
不允许直接请求 Global.asa。
500.16
UNC 授权凭据不正确。这个错误代码为 IIS 6.0 所专用。
500.18
URL 授权存储不能打开。这个错误代码为 IIS 6.0 所专用。
500.100
内部 ASP 错误。
501 Not Implemented
请求未完成。服务器不支持所请求的功能。
502 Bad Gateway
请求未完成。服务器从上游服务器收到一个无效的响应。
502.1
CGI 应用程序超时。 ·
502.2
CGI 应用程序出错。
503 Service Unavailable
请求未完成。服务器临时过载或当机。
504 Gateway Timeout
网关超时。
505 HTTP Version Not Supported
服务器不支持请求中指明的HTTP协议版本
1.3 str和bytes的区别
bytes
bytes对象只负责以二进制字节序列的形式记录所需记录的对象,至于该对象到底表示什么(比如到底是什么字符)则由相应的编码格式解码所决定
Python2 中
>>> type(b'xxxxx')
<type 'str'>
>>> type('xxxxx')
<type 'str'>
Python3 中
>>> type(b'xxxxx')
<class 'bytes'>
>>> type('xxxxx')
<class 'str'>
bytes是Python 3中特有的,Python 2 里不区分bytes和str。
python3中:
str 使用encode方法转化为 bytes
bytes通过decode转化为str
In [9]: str1='人生苦短,我用Python!'
In [10]: type(str1)
Out[10]: str
In [11]: b=str1.encode()#编码
In [12]: b
Out[12]: b'\xe4\xba\xba\xe7\x94\x9f\xe8\x8b\xa6\xe7\x9f\xad\
xef\xbc\x8c\xe6\x88\x91\xe7\x94\xa8Python!'
In [13]: type(str1.encode())
Out[13]: bytes
bytes转换成str:
In [22]: b
Out[22]: b'\xe4\xba\xba\xe7\x94\x9f\xe8\x8b\xa6\xe7\x9f\xad\
xef\xbc\x8c\xe6\x88\x91\xe7\x94\xa8Python!'
In [23]: type(b)
Out[23]: bytes
In [24]: b.decode()
Out[24]: '人生苦短,我用Python!'
In [25]: type(b.decode())
Out[25]: str
在Python 2中由于不区分str和bytes所以可以直接通过encode()和decode()方法进行编码解码。
而在Python 3中把两者给分开了这个在使用中需要注意。实际应用中在互联网上是通过二进制进行传输,所以就需要将str转换成bytes进行传输,而在接收中通过decode()解码成我们需要的编码进行处理数据这样不管对方是什么编码而本地是我们使用的编码这样就不会乱码。
bytearray
bytearray和bytes不一样的地方在于,bytearray是可变的。
In [26]: str1
Out[26]: '人生苦短,我用Python!'
In [28]: b1=bytearray(str1.encode())
In [29]: b1
Out[29]: bytearray(b'\xe4\xba\xba\xe7\x94\x9f\xe8\x8b\xa6\xe7\x9f\xad\xef\xbc\x8c\xe6\x88\x91\xe7\x94\xa8Python!')
In [30]: b1.decode()
Out[30]: '人生苦短,我用Python!'
In [31]: b1[:6]=bytearray('生命'.encode())
In [32]: b1
Out[32]: bytearray(b'\xe7\x94\x9f\xe5\x91\xbd\xe8\x8b\xa6\xe7\x9f\xad\xef\xbc\x8c\xe6\x88\x91\xe7\x94\xa8Python!')
In [33]: b1.decode()
Out[33]: '生命苦短,我用Python!'
1.4 Requests的简单应用
Requests: 让 HTTP 服务人类
虽然Python的标准库中 urllib 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更简洁方便。
Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用:)
Requests 继承了urllib的所有特性。Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。
requests 的底层实现其实就是 urllib
Requests的文档非常完备,中文文档也相当不错。Requests能完全满足当前网络的需求,支持Python 2.6–3.5,而且能在PyPy下完美运行。
开源地址:https://github.com/kennethreitz/requests
中文文档 API: http://docs.python-requests.org/zh_CN/latest/index.html
安装方式
利用 pip 安装 或者利用 easy_install 都可以完成安装:
$ pip install requests
$ easy_install requests
基本GET请求(headers参数 和 parmas参数)
1. 最基本的GET请求可以直接用get方法
response = requests.get("http://www.baidu.com/")
# 也可以这么写
# response = requests.request("get", "http://www.baidu.com/")
2. 添加 headers 和 查询参数
如果想添加 headers,可以传入headers参数来增加请求头中的headers信息。如果要将参数放在url中传递,可以利用 params 参数。
import requests
kw = {'wd':'长城'}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# params 接收一个字典或者字符串的查询参数,字典类型自动转换为url编码,不需要urlencode()
response = requests.get("http://www.baidu.com/s?", params = kw, headers = headers)
# 查看响应内容,response.text 返回的是Unicode格式的数据
print (response.text)
# 查看响应内容,response.content返回的字节流数据
print (respones.content)
# 查看完整url地址
print (response.url)
# 查看响应头部字符编码
print (response.encoding)
# 查看响应码
print (response.status_code)
运行结果
......
......
'http://www.baidu.com/s?wd=%E9%95%BF%E5%9F%8E'
'utf-8'
200
- 使用response.text 时,Requests 会基于 HTTP 响应的文本编码自动解码响应内容,大多数 Unicode 字符集都能被无缝地解码。
- 使用response.content 时,返回的是服务器响应数据的原始二进制字节流,可以用来保存图片等二进制文件。
小栗子
3. 通过requests获取新浪首页
#coding=utf-8
import requests
response = requests.get("http://www.sina.com")
print(response.request.headers)
print(response.content.decode())
结果
{'User-Agent': 'python-requests/2.12.4', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
<!DOCTYPE html>
<!-- [ published at 2017-06-09 15:15:23 ] -->
<html>
<head>
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<title>新浪首页</title>
<meta name="keywords" content="新浪,新浪网,SINA,sina,sina.com.cn,新浪首页,门户,资讯" />
...
#coding=utf-8
import requests
response = requests.get("http://www.sina.com")
print(response.request.headers)
print(response.text)
结果
{'User-Agent': 'python-requests/2.12.4', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
<!DOCTYPE html>
<!-- [ published at 2017-06-09 15:18:10 ] -->
<html>
<head>
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<title>新浪首页</title>
<meta name="keywords" content="新浪,新浪网,SINA,sina,sina.com.cn,新浪首页,门户,资讯" />
<meta name="description" content="新浪网为全çƒç”¨æˆ·24å°æ—¶æ供全é¢åŠæ—¶çš„ä¸æ–‡èµ„讯,内容覆盖国内外çªå‘新闻事件ã€ä½“å›èµ›äº‹ã€å¨±ä¹æ—¶å°šã€äº§ä¸šèµ„讯ã€å®žç”¨ä¿¡æ¯ç‰ï¼Œè®¾æœ‰æ–°é—»ã€ä½“育ã€å¨±ä¹ã€è´¢ç»ã€ç§‘技ã€æˆ¿äº§ã€æ±½è½¦ç‰30多个内容频é“,åŒæ—¶å¼€è®¾åšå®¢ã€è§†é¢‘ã€è®ºå›ç‰è‡ªç”±äº’动交æµç©ºé—´ã€‚" />
<link rel="mask-icon" sizes="any" href="//www.sina.com.cn/favicon.svg" color="red">
`
产生问题的原因分析
- requests默认自带的Accept-Encoding导致或者新浪默认发送的就是压缩之后的网页
- 但是为什么content.read()没有问题,因为requests,自带解压压缩网页的功能
- 当收到一个响应时,Requests 会猜测响应的编码方式,用于在你调用response.text 方法时对响应进行解码。Requests 首先在 HTTP 头部检测是否存在指定的编码方式,如果不存在,则会使用 chardet.detect来尝试猜测编码方式(存在误差)
- 更推荐使用response.content.deocde()
4. 通过requests获取网络上图片的大小
from io import BytesIO,StringIO
import requests
from PIL import Image
img_url = "http://imglf1.ph.126.net/pWRxzh6FRrG2qVL3JBvrDg==/6630172763234505196.png"
response = requests.get(img_url)
f = BytesIO(response.content)
img = Image.open(f)
print(img.size)
输出结果:
(500, 262)
理解一下 BytesIO 和StringIO
很多时候,数据读写不一定是文件,也可以在内存中读写。
StringIO顾名思义就是在内存中读写str。
BytesIO 就是在内存中读写bytes类型的二进制数据
例子中如果使用StringIO 即f = StringIO(response.text)会产生"cannot identify image file"的错误
当然上述例子也可以把图片存到本地之后再使用Image打开来获取图片大小
1.5 requests深入
基本POST请求(data参数)
1. 最基本post方法
response = requests.post("http://www.baidu.com/", data = data)
2. 传入data数据
对于 POST 请求来说,我们一般需要为它增加一些参数。那么最基本的传参方法可以利用 data 这个参数。
import requests
formdata = {
"type":"AUTO",
"i":"i love python",
"doctype":"json",
"xmlVersion":"1.8",
"keyfrom":"fanyi.web",
"ue":"UTF-8",
"action":"FY_BY_ENTER",
"typoResult":"true"
}
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null"
headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
response = requests.post(url, data = formdata, headers = headers)
print (response.text)
# 如果是json文件可以直接显示
print (response.json())
运行结果
{"type":"EN2ZH_CN","errorCode":0,"elapsedTime":3,"translateResult":[[{"src":"i love python","tgt":"我喜欢python"}]],"smartResult":{"type":1,"entries":["","肆文","","","高德纳","",""]}}
{'type': 'EN2ZH_CN', 'errorCode': 0, 'elapsedTime': 3, 'translateResult': [[{'src': 'i love python', 'tgt': '我喜欢python'}]], 'smartResult': {'type': 1, 'entries': ['', '肆文', '', '', '高德纳', '', '']}}
代理(proxies参数)
如果需要使用代理,你可以通过为任意请求方法提供 proxies 参数来配置单个请求:
import requests
# 根据协议类型,选择不同的代理
proxies = {
"http": "http://12.34.56.79:9527",
"https": "http://12.34.56.79:9527",
}
response = requests.get("http://www.baidu.com", proxies = proxies)
print (response.text)
也可以通过本地环境变量 HTTP_PROXY 和 HTTPS_PROXY 来配置代理:
export HTTP_PROXY="http://12.34.56.79:9527"
export HTTPS_PROXY="https://12.34.56.79:9527"
私密代理验证(特定格式) 和 Web客户端验证(auth 参数)
私密代理
import requests
# 如果代理需要使用HTTP Basic Auth,可以使用下面这种格式:
proxy = { "http": "mr_mao_hacker:sffqry9r@61.158.163.130:16816" }
response = requests.get("http://www.baidu.com", proxies = proxy)
print (response.text)
web客户端验证
如果是Web客户端验证,需要添加 auth = (账户名, 密码)
import requests
auth=('test', '123456')
response = requests.get('http://192.168.199.107', auth = auth)
print (response.text)
Cookies 和 Sission
Cookies
如果一个响应中包含了cookie,那么我们可以利用 cookies参数拿到:
import requests
response = requests.get("http://www.baidu.com/")
# 7\. 返回CookieJar对象:
cookiejar = response.cookies
# 8\. 将CookieJar转为字典:
cookiedict = requests.utils.dict_from_cookiejar(cookiejar)
print (cookiejar)
print (cookiedict)
运行结果:
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
{'BDORZ': '27315'}
session
在 requests 里,session对象是一个非常常用的对象,这个对象代表一次用户会话:从客户端浏览器连接服务器开始,到客户端浏览器与服务器断开。
会话能让我们在跨请求时候保持某些参数,比如在同一个 Session 实例发出的所有请求之间保持 cookie 。
实现人人网登录
import requests
# 1\. 创建session对象,可以保存Cookie值
ssion = requests.session()
# 2\. 处理 headers
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 3\. 需要登录的用户名和密码
data = {"email":"mr_mao_hacker@163.com", "password":"alarmchime"}
# 4\. 发送附带用户名和密码的请求,并获取登录后的Cookie值,保存在ssion里
ssion.post("http://www.renren.com/PLogin.do", data = data)
# 5\. ssion包含用户登录后的Cookie值,可以直接访问那些登录后才可以访问的页面
response = ssion.get("http://www.renren.com/410043129/profile")
# 6\. 打印响应内容
print (response.text)
处理HTTPS请求 SSL证书验证
Requests也可以为HTTPS请求验证SSL证书:
- 要想检查某个主机的SSL证书,你可以使用 verify 参数(也可以不写)
import requests
response = requests.get("https://www.baidu.com/", verify=True)
# 也可以省略不写
# response = requests.get("https://www.baidu.com/")
print (r.text)
运行结果:
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type
content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible
content=IE=Edge>百度一下,你就知道 ....
- 如果SSL证书验证不通过,或者不信任服务器的安全证书,则会报出SSLError,据说 12306 证书是自己做的:
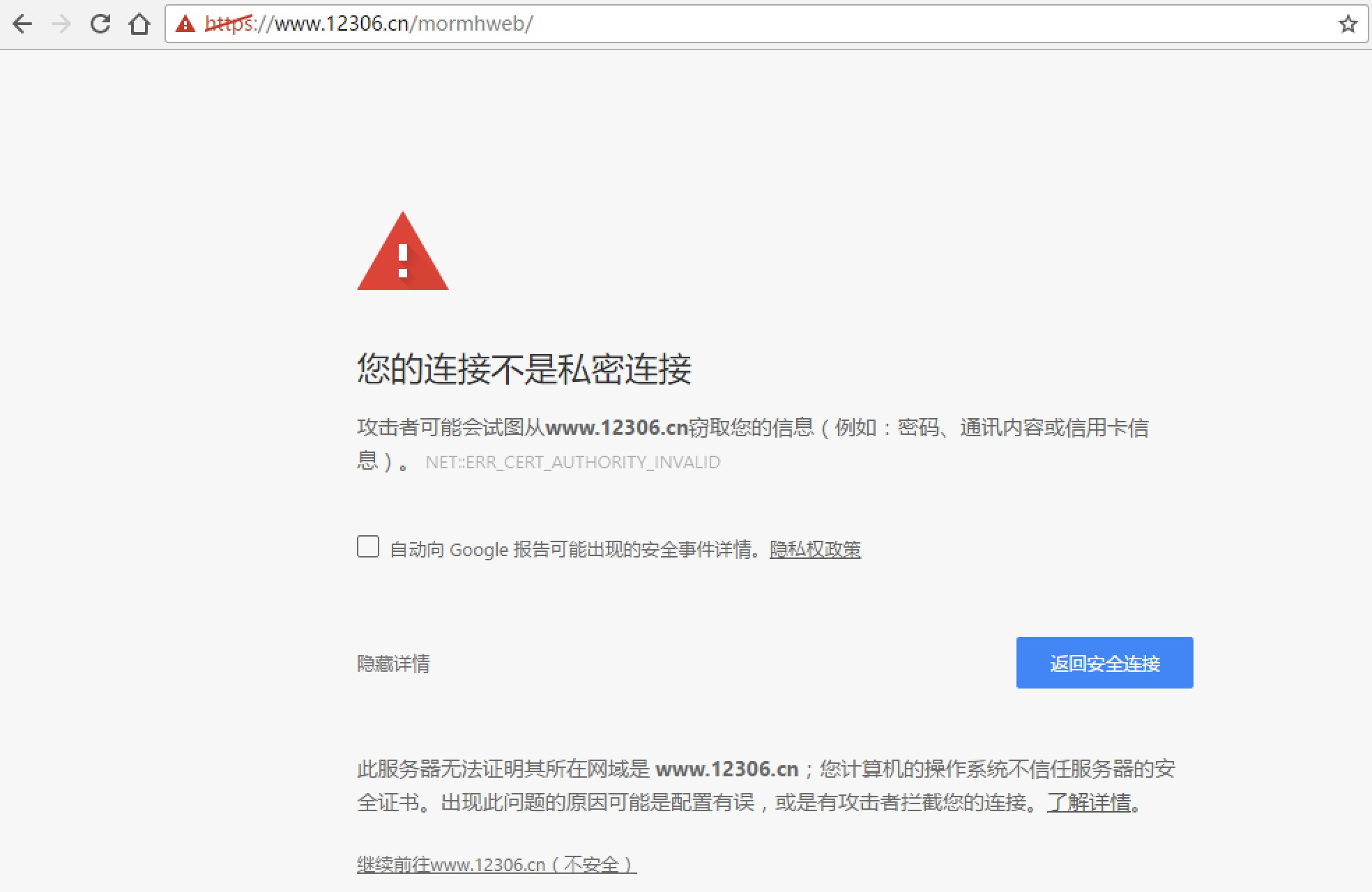
来测试一下:
import requests
response = requests.get("https://www.12306.cn/mormhweb/")
print (response.text)
果然:
SSLError: ("bad handshake: Error([('SSL routines', 'ssl3_get_server_certificate', 'certificate verify failed')],)",)
如果我们想跳过 12306 的证书验证,把 verify 设置为 False 就可以正常请求了。
r = requests.get("https://www.12306.cn/mormhweb/", verify = False)
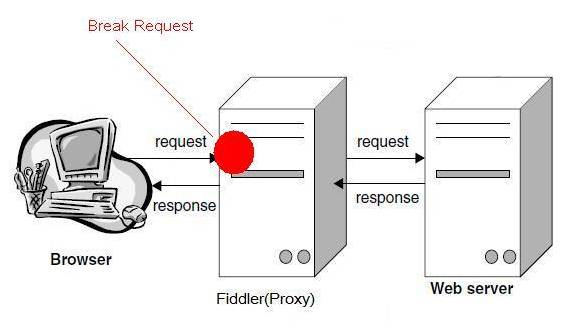
1.6 HTTP代理神器Fiddler
Fiddler是一款强大Web调试工具,它能记录所有客户端和服务器的HTTP请求。 Fiddler启动的时候,默认IE的代理设为了127.0.0.1:8888,而其他浏览器是需要手动设置。
工作原理
Fiddler 是以代理web服务器的形式工作的,它使用代理地址:127.0.0.1,端口:8888
Fiddler抓取HTTPS设置
-
启动Fiddler,打开菜单栏中的 Tools > Telerik Fiddler Options,打开“Fiddler Options”对话框。
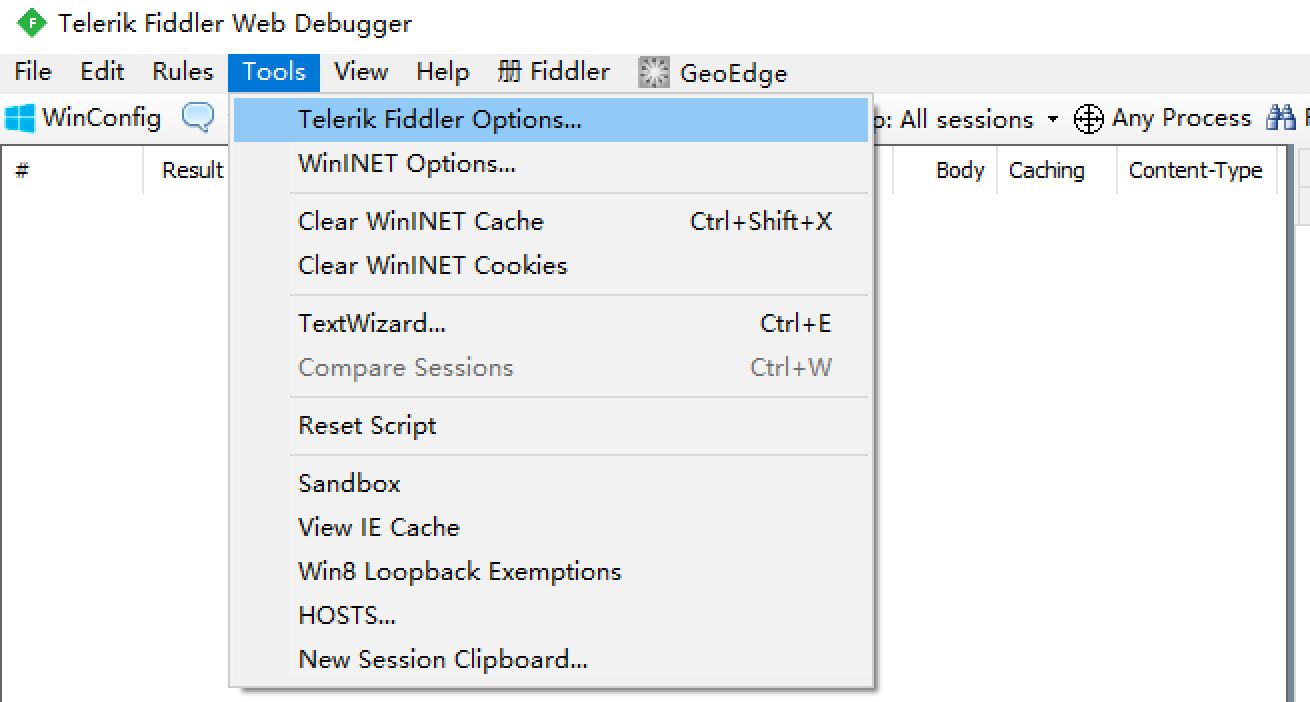
-
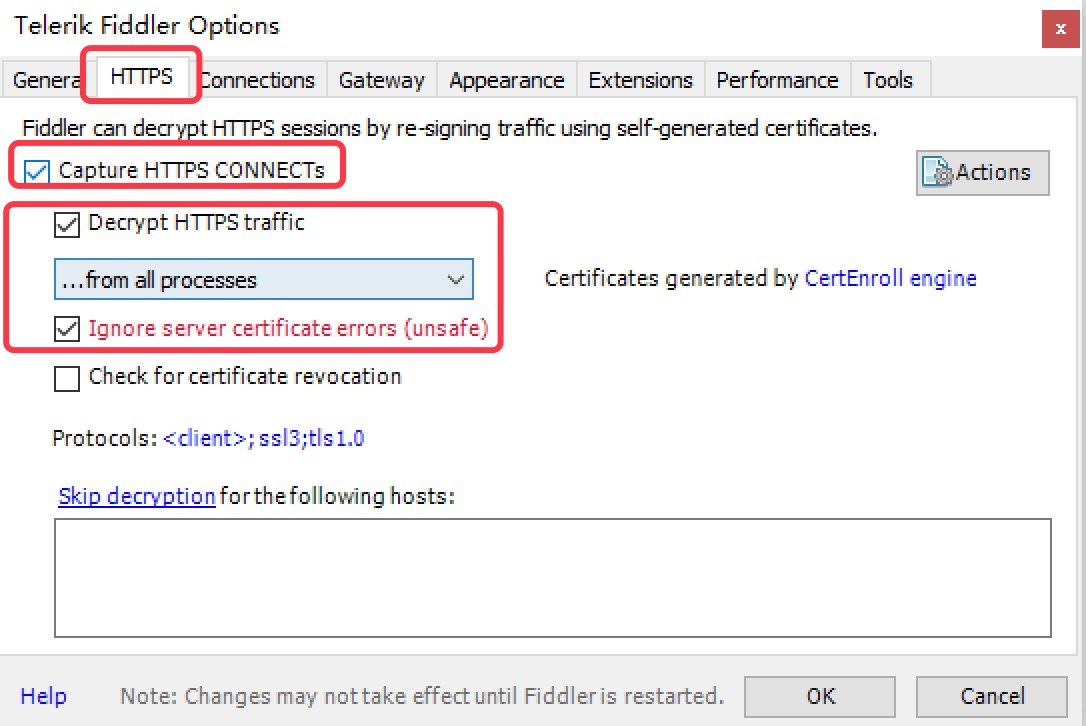
对Fiddler进行设置:
-
打开工具栏->Tools->Fiddler Options->HTTPS,
-
选中Capture HTTPS CONNECTs (捕捉HTTPS连接),
-
选中Decrypt HTTPS traffic(解密HTTPS通信)
-
另外我们要用Fiddler获取本机所有进程的HTTPS请求,所以中间的下拉菜单中选中…from all processes (从所有进程)
-
选中下方Ignore server certificate errors(忽略服务器证书错误)
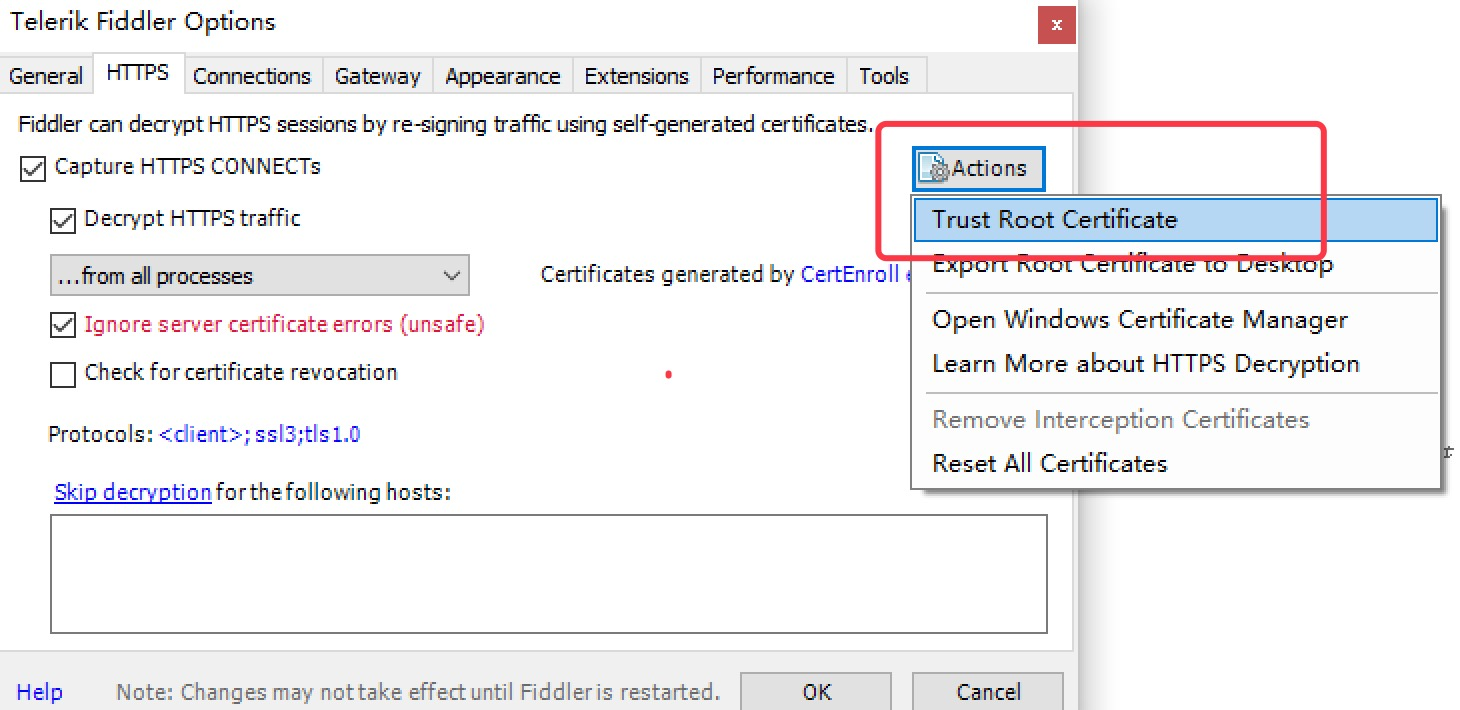
-
-
为 Fiddler 配置Windows信任这个根证书解决安全警告:Trust Root Certificate(受信任的根证书)。
-
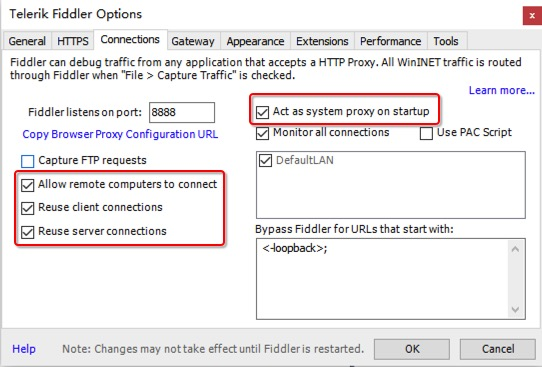
Fiddler 主菜单 Tools -> Fiddler Options…-> Connections
-
选中Allow remote computers to connect(允许远程连接)
-
Act as system proxy on startup(作为系统启动代理)
-
-
重启Fiddler,使配置生效(这一步很重要,必须做)。
Fiddler 如何捕获Chrome的会话
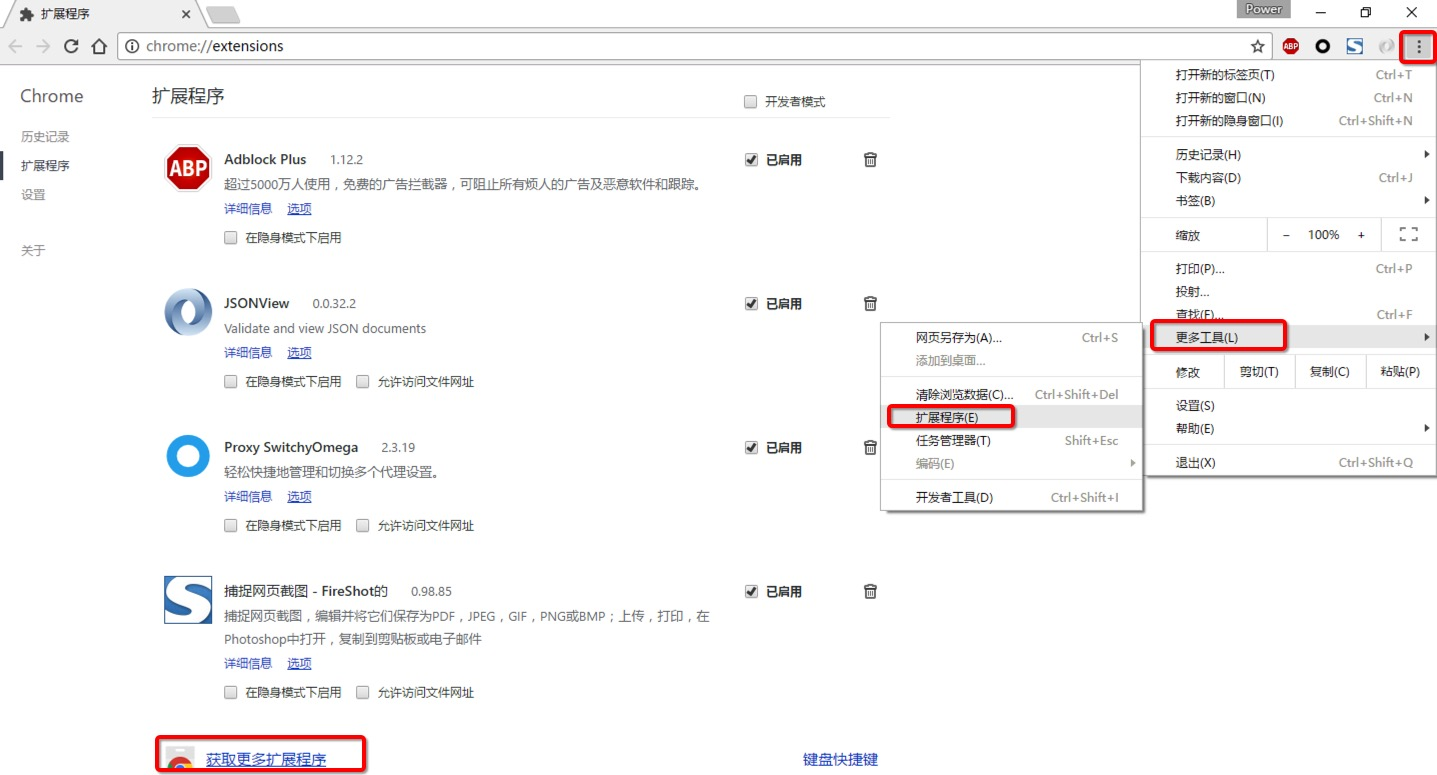
-
安装SwitchyOmega 代理管理 Chrome 浏览器插件
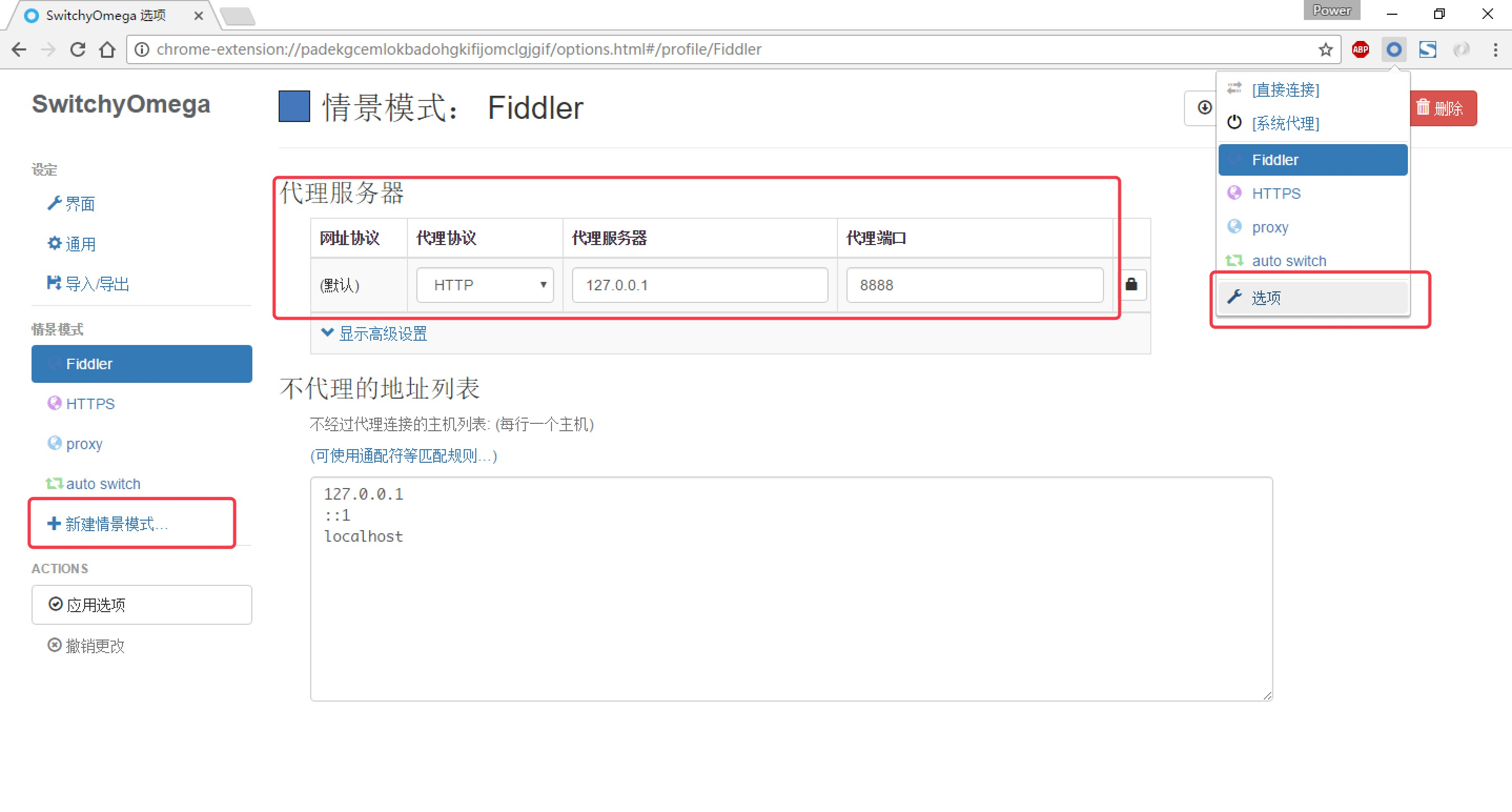
-
如图所示,设置代理服务器为127.0.0.1:8888
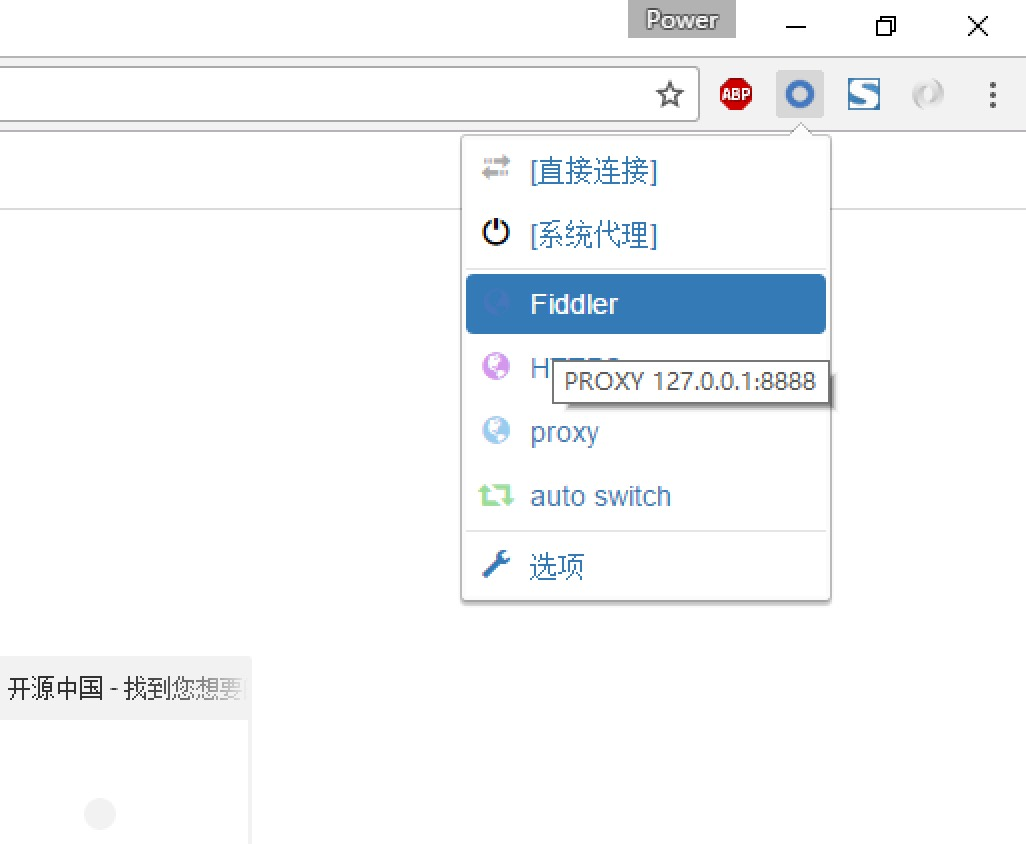
-
通过浏览器插件切换为设置好的代理。
Fiddler界面
设置好后,本机HTTP通信都会经过127.0.0.1:8888代理,也就会被Fiddler拦截到。
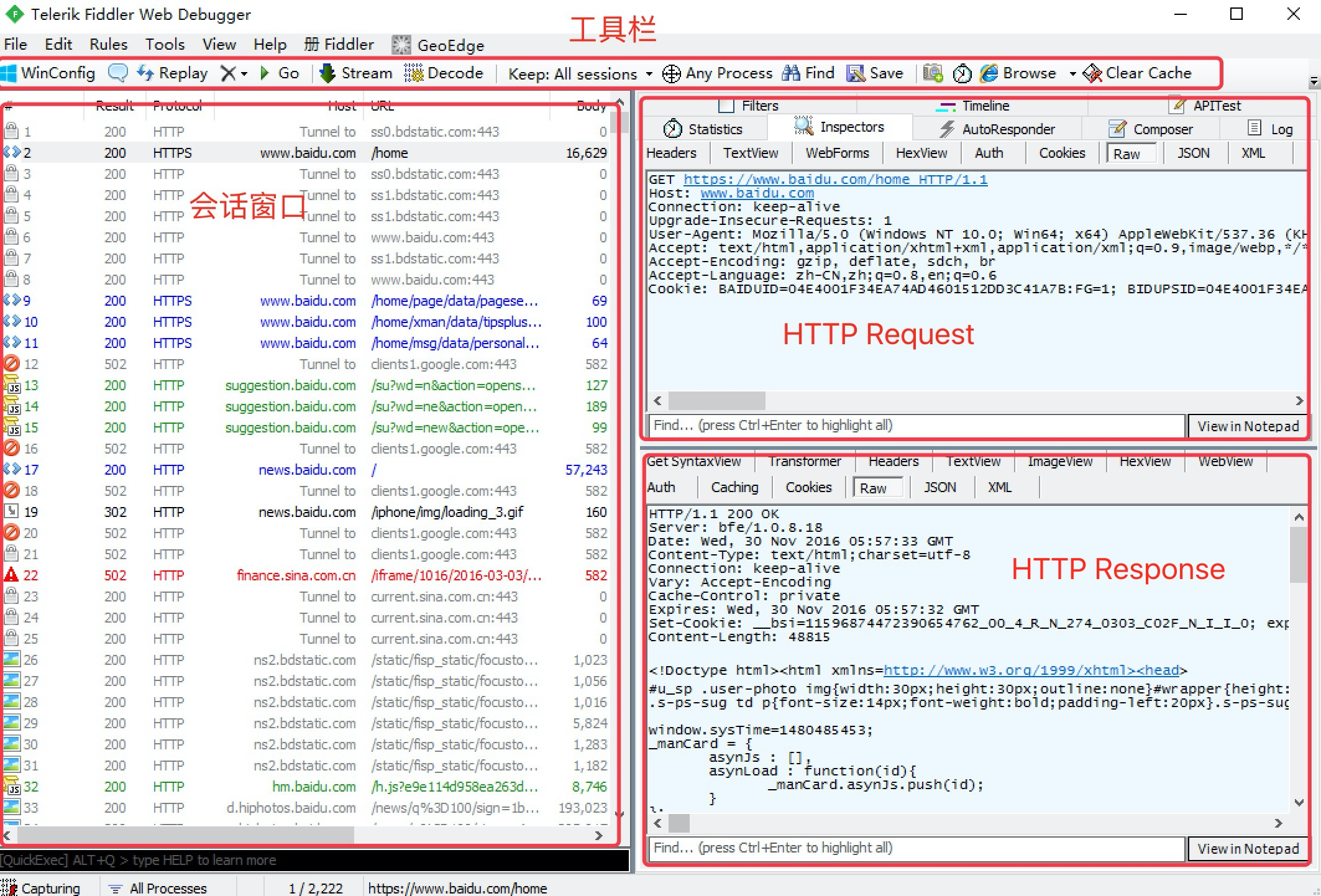
请求 (Request) 部分详解
- Headers —— 显示客户端发送到服务器的 HTTP 请求的 header,显示为一个分级视图,包含了 Web 客户端信息、Cookie、传输状态等。
- Textview —— 显示 POST 请求的 body 部分为文本。
- WebForms —— 显示请求的 GET 参数 和 POST body 内容。
- HexView —— 用十六进制数据显示请求。
- Auth —— 显示响应 header 中的 Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息.
- Raw —— 将整个请求显示为纯文本。
- JSON - 显示JSON格式文件。
- XML —— 如果请求的 body 是 XML 格式,就是用分级的 XML 树来显示它。
响应 (Response) 部分详解
- Transformer —— 显示响应的编码信息。
- Headers —— 用分级视图显示响应的 header。
- TextView —— 使用文本显示相应的 body。
- ImageVies —— 如果请求是图片资源,显示响应的图片。
- HexView —— 用十六进制数据显示响应。
- WebView —— 响应在 Web 浏览器中的预览效果。
- Auth —— 显示响应 header 中的 Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息。
- Caching —— 显示此请求的缓存信息。
- Privacy —— 显示此请求的私密 (P3P) 信息。
- Raw —— 将整个响应显示为纯文本。
- JSON - 显示JSON格式文件。
- XML —— 如果响应的 body 是 XML 格式,就是用分级的 XML 树来显示它 。
1.7 urllib库的基本使用
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。 在Python中有很多库可以用来抓取网页,我们先学习urllib。
*在 python2 中,urllib 被分为urllib,urllib2等*
urlopen
我们先来段代码:
# urllib_request.py
# 导入urllib.request 库
import urllib.request
# 向指定的url发送请求,并返回服务器响应的类文件对象
response = urllib.request.urlopen("https://www.baidu.com")
# 类文件对象支持文件对象的操作方法,如read()方法读取文件全部内容,返回字符串
html = response.read()
# 打印字符串
print (html)
执行写的python代码,将打印结果
Power@PowerMac ~$: python urllib_request.py
实际上,如果我们在浏览器上打开百度主页, 右键选择“查看源代码”,你会发现,跟我们刚才打印出来的是一模一样。也就是说,上面的4行代码就已经帮我们把百度的首页的全部代码爬了下来。
一个基本的url请求对应的python代码真的非常简单。
Request
在我们第一个例子里,urlopen()的参数就是一个url地址;
但是如果需要执行更复杂的操作,比如增加HTTP报头,必须创建一个 Request 实例来作为urlopen()的参数;而需要访问的url地址则作为 Request 实例的参数。
我们编辑urllib_request.py
# urllib_request.py
import urllib.request
# url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request("http://www.baidu.com")
# Request对象作为urlopen()方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request)
html = response.read().decode()
print (html)
运行结果是完全一样的:
新建Request实例,除了必须要有 url 参数之外,还可以设置另外两个参数:
- data(默认空):是伴随 url 提交的数据(比如要post的数据),同时 HTTP 请求将从 "GET"方式 改为 "POST"方式。
- headers(默认空):是一个字典,包含了需要发送的HTTP报头的键值对。
这两个参数下面会说到。
User-Agent
但是这样直接用urllib给一个网站发送请求的话,确实略有些唐突了,就好比,人家每家都有门,你以一个路人的身份直接闯进去显然不是很礼貌。而且有一些站点不喜欢被程序(非人为访问)访问,有可能会拒绝你的访问请求。
但是如果我们用一个合法的身份去请求别人网站,显然人家就是欢迎的,所以我们就应该给我们的这个代码加上一个身份,就是所谓的User-Agent头。
- 浏览器 就是互联网世界上公认被允许的身份,如果我们希望我们的爬虫程序更像一个真实用户,那我们第一步,就是需要伪装成一个被公认的浏览器。用不同的浏览器在发送请求的时候,会有不同的User-Agent头。 urllib默认的User-Agent头为:
Python-urllib/x.y(x和y是Python主版本和次版本号,例如 Python-urllib/2.7)
#urllib_request.py
import urllib.request
url = "http://www.itcast.cn"
#IE 9.0 的 User-Agent,包含在 ua_header里
ua_header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
# url 连同 headers,一起构造Request请求,这个请求将附带 IE9.0 浏览器的User-Agent
request = urllib.request.Request(url, headers = ua_header)
# 向服务器发送这个请求
response = urllib.request.urlopen(request)
html = response.read()
print (html)
添加更多的Header信息
在 HTTP Request 中加入特定的 Header,来构造一个完整的HTTP请求消息。
可以通过调用
Request.add_header()添加/修改一个特定的header 也可以通过调用Request.get_header()来查看已有的header。
- 添加一个特定的header
# urllib_headers.py
import urllib.request
url = "http://www.itcast.cn"
#IE 9.0 的 User-Agent
header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
request = urllib.request.Request(url, headers = header)
#也可以通过调用Request.add_header() 添加/修改一个特定的header
request.add_header("Connection", "keep-alive")
# 也可以通过调用Request.get_header()来查看header信息
# request.get_header(header_name="Connection")
response = urllib.request.urlopen(request)
print (response.code) #可以查看响应状态码
html = response.read().decode()
print (html)
- 随机添加/修改User-Agent
# urllib_add_headers.py
import urllib
import random
url = "http://www.itcast.cn"
ua_list = [
"Mozilla/5.0 (Windows NT 6.1; ) Apple.... ",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0)... ",
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X.... ",
"Mozilla/5.0 (Macintosh; Intel Mac OS... "
]
user_agent = random.choice(ua_list)
request = urllib.request.Request(url)
#也可以通过调用Request.add_header() 添加/修改一个特定的header
request.add_header("User-Agent", user_agent)
# get_header()的字符串参数,第一个字母大写,后面的全部小写
request.get_header("User-agent")
response = urllib.request.urlopen(requestr)
html = response.read()
print (html)
1.8 urllib默认只支持HTTP/HTTPS的GET和POST方法
urllib.parse.urlencode()
- 编码工作使用urllib.parse的
urlencode()函数,帮我们将key:value这样的键值对转换成"key=value"这样的字符串,解码工作可以使用urllib.parse的unquote()函数。
# IPython3 中的测试结果
In [1]: import urllib.parse
In [2]: word = {"wd" : "传智播客"}
# 通过urllib.urlencode()方法,将字典键值对按URL编码转换,从而能被web服务器接受。
In [3]: urllib.parse.urlencode(word)
Out[3]: "wd=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2"
# 通过urllib.unquote()方法,把 URL编码字符串,转换回原先字符串。
In [4]: print urllib.parse.unquote("wd=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2")
wd=传智播客
一般HTTP请求提交数据,需要编码成 URL编码格式,然后做为url的一部分,或者作为参数传到Request对象中。
Get方式
GET请求一般用于我们向服务器获取数据,比如说,我们用百度搜索传智播客:https://www.baidu.com/s?wd=传智播客
浏览器的url会跳转成如图所示:
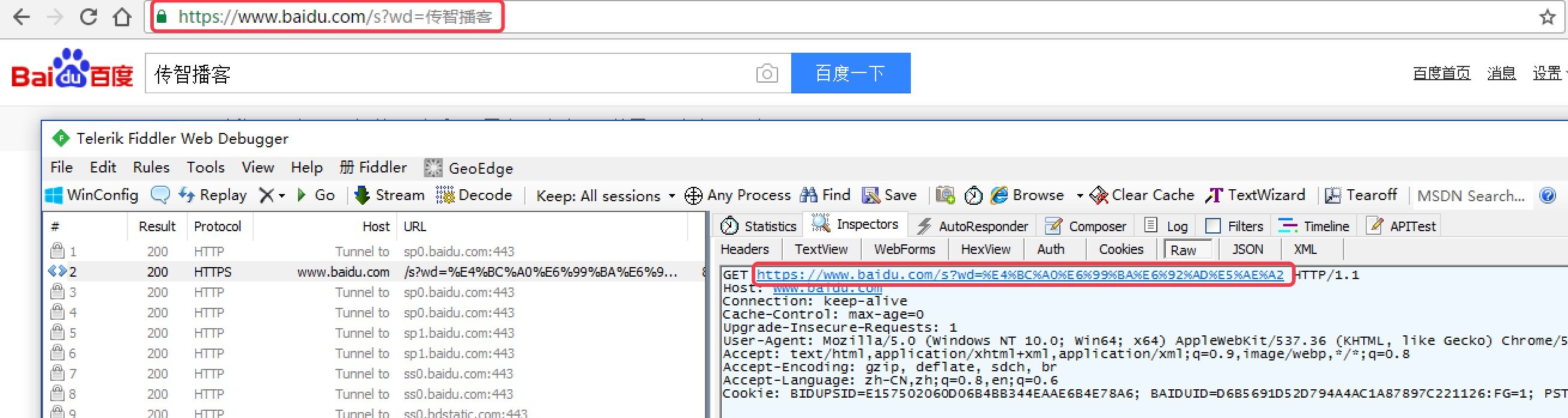
在其中我们可以看到在请求部分里,http://www.baidu.com/s? 之后出现一个长长的字符串,其中就包含我们要查询的关键词传智播客,于是我们可以尝试用默认的Get方式来发送请求。
# urllib_get.py
url = "http://www.baidu.com/s"
word = {"wd":"传智播客"}
word = urllib.parse.urlencode(word) #转换成url编码格式(字符串)
newurl = url + "?" + word # url首个分隔符就是 ?
headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
request = urllib.request.Request(newurl, headers=headers)
response = urllib.request.urlopen(request)
print (response.read())
批量爬取贴吧页面数据
首先我们创建一个python文件, tiebaSpider.py,我们要完成的是,输入一个百度贴吧的地址,比如:
百度贴吧LOL吧第一页:http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=0
第二页: http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=50
第三页: http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=100
发现规律了吧,贴吧中每个页面不同之处,就是url最后的pn的值,其余的都是一样的,我们可以抓住这个规律。
简单写一个小爬虫程序,来爬取百度LOL吧的所有网页。
- 先写一个main,提示用户输入要爬取的贴吧名,并用urllib.urlencode()进行转码,然后组合url,假设是lol吧,那么组合后的url就是http://tieba.baidu.com/f?kw=lol
# 模拟 main 函数
if __name__ == "__main__":
kw = raw_input("请输入需要爬取的贴吧:")
# 输入起始页和终止页,str转成int类型
beginPage = int(raw_input("请输入起始页:"))
endPage = int(raw_input("请输入终止页:"))
url = "http://tieba.baidu.com/f?"
key = urllib.parse.urlencode({"kw" : kw})
# 组合后的url示例:http://tieba.baidu.com/f?kw=lol
url = url + key
tiebaSpider(url, beginPage, endPage)
- 接下来,我们写一个百度贴吧爬虫接口,我们需要传递3个参数给这个接口, 一个是main里组合的url地址,以及起始页码和终止页码,表示要爬取页码的范围。
def tiebaSpider(url, beginPage, endPage):
"""
作用:负责处理url,分配每个url去发送请求
url:需要处理的第一个url
beginPage: 爬虫执行的起始页面
endPage: 爬虫执行的截止页面
"""
for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50
filename = "第" + str(page) + "页.html"
# 组合为完整的 url,并且pn值每次增加50
fullurl = url + "&pn=" + str(pn)
#print fullurl
# 调用loadPage()发送请求获取HTML页面
html = loadPage(fullurl, filename)
# 将获取到的HTML页面写入本地磁盘文件
writeFile(html, filename)
- 我们已经之前写出一个爬取一个网页的代码。现在,我们可以将它封装成一个小函数loadPage,供我们使用。
def loadPage(url, filename):
'''
作用:根据url发送请求,获取服务器响应文件
url:需要爬取的url地址
filename: 文件名
'''
print ("正在下载" + filename)
headers = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
request = urllib.request.Request(url, headers = headers)
response = urllib.request.urlopen(request)
return response.read()
- 最后如果我们希望将爬取到了每页的信息存储在本地磁盘上,我们可以简单写一个存储文件的接口。
def writeFile(html, filename):
"""
作用:保存服务器响应文件到本地磁盘文件里
html: 服务器响应文件
filename: 本地磁盘文件名
"""
print ("正在存储" + filename)
with open(filename, 'w') as f:
f.write(html)
print "-" * 20
其实很多网站都是这样的,同类网站下的html页面编号,分别对应网址后的网页序号,只要发现规律就可以批量爬取页面了。
POST方式:
上面我们说了Request请求对象的里有data参数,它就是用在POST里的,我们要传送的数据就是这个参数data,data是一个字典,里面要匹配键值对。
有道词典翻译网站:
输入测试数据,再通过使用Fiddler观察,其中有一条是POST请求,而向服务器发送的请求数据并不是在url里,那么我们可以试着模拟这个POST请求。
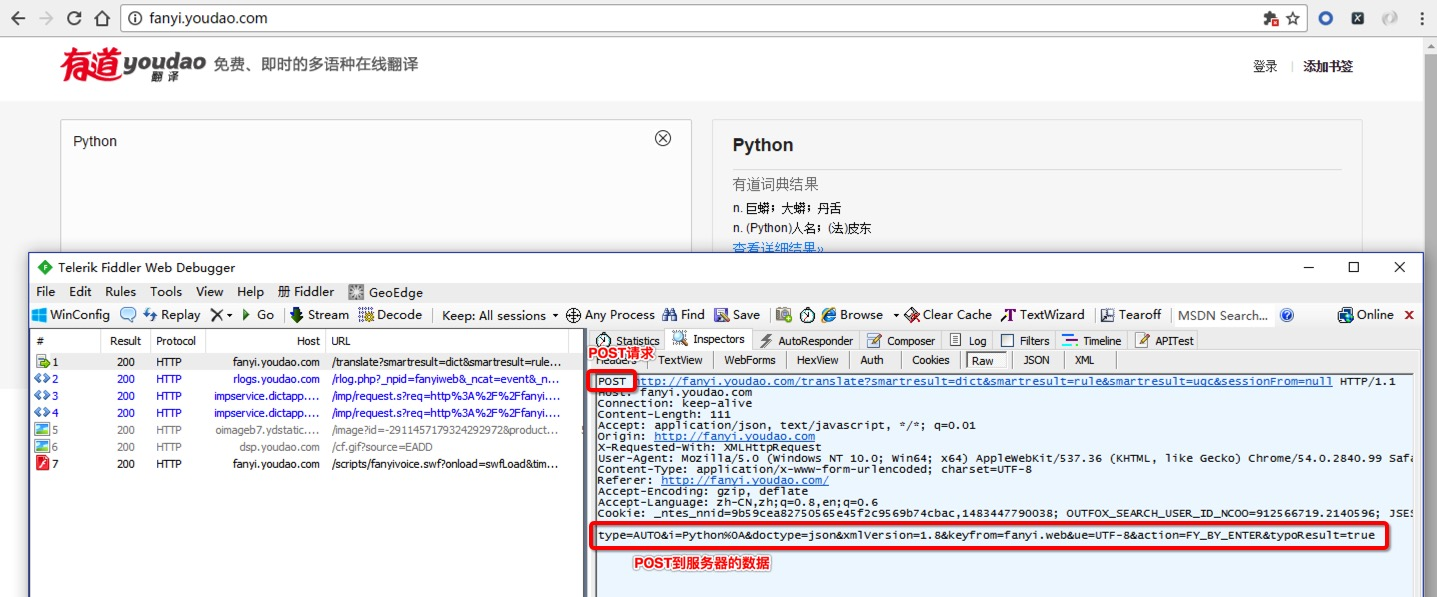
于是,我们可以尝试用POST方式发送请求。
import urllib
# POST请求的目标URL
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null"
headers={"User-Agent": "Mozilla...."}
formdata = {
"type":"AUTO",
"i":"i love python",
"doctype":"json",
"xmlVersion":"1.8",
"keyfrom":"fanyi.web",
"ue":"UTF-8",
"action":"FY_BY_ENTER",
"typoResult":"true"
}
data = urllib.parse.urlencode(formdata)
request = urllib.request.Request(url, data = data, headers = headers)
response = urllib.request.urlopen(request)
print (response.read())
发送POST请求时,需要特别注意headers的一些属性:
Content-Length: 144: 是指发送的表单数据长度为144,也就是字符个数是144个。
Content-Type: application/x-www-form-urlencoded: 表示浏览器提交 Web 表单时使用,表单数据会按照 name1=value1&name2=value2 键值对形式进行编码。
X-Requested-With: XMLHttpRequest:表示Ajax异步请求。
获取AJAX加载的内容
有些网页内容使用AJAX加载,这种数据无法直接对网页url进行获取。只要记得,AJAX一般返回的是JSON,只要对AJAX地址进行post或get,就能返回JSON数据了。
如果非要从HTML页面里获取展现出来的数据,也不是不可以。但是要记住,作为一名爬虫工程师,你更需要关注的是数据的来源。
import urllib
# demo1
url = "https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action"
headers={"User-Agent": "Mozilla...."}
# 变动的是这两个参数,从start开始往后显示limit个
formdata = {
'start':'0',
'limit':'10'
}
data = urllib.parse.urlencode(formdata)
request = urllib.request.Request(url, data = data, headers = headers)
response = urllib.request.urlopen(request)
print (response.read())
# demo2
url = "https://movie.douban.com/j/chart/top_list?"
headers={"User-Agent": "Mozilla...."}
# 处理所有参数
formdata = {
'type':'11',
'interval_id':'100:90',
'action':'',
'start':'0',
'limit':'10'
}
data = urllib.parse.urlencode(formdata)
request = urllib.request.Request(url, data = data, headers = headers)
response = urllib.request.urlopen(request)
print (response.read())
- GET方式是直接以链接形式访问,链接中包含了所有的参数,服务器端用Request.QueryString获取变量的值。如果包含了密码的话是一种不安全的选择,不过你可以直观地看到自己提交了什么内容。
- POST则不会在网址上显示所有的参数,服务器端用Request.Form获取提交的数据,在Form提交的时候。但是HTML代码里如果不指定 method 属性,则默认为GET请求,Form中提交的数据将会附加在url之后,以
?分开与url分开。- 表单数据可以作为 URL 字段(method=“get”)或者 HTTP POST (method=“post”)的方式来发送。比如在下面的HTML代码中,表单数据将因为 (method=“get”) 而附加到 URL 上:
<form action="form_action.asp" method="get">
<p>First name: <input type="text" name="fname" /></p>
<p>Last name: <input type="text" name="lname" /></p>
<input type="submit" value="Submit" />
</form>
处理HTTPS请求 SSL证书验证
现在随处可见 https 开头的网站,urllib可以为 HTTPS 请求验证SSL证书,就像web浏览器一样,如果网站的SSL证书是经过CA认证的,则能够正常访问,如:https://www.baidu.com/等…
如果SSL证书验证不通过,或者操作系统不信任服务器的安全证书,比如浏览器在访问12306网站如:https://www.12306.cn/mormhweb/的时候,会警告用户证书不受信任。(据说 12306 网站证书是自己做的,没有通过CA认证)

urllib在访问的时候则会报出SSLError:
import urllib
url = "https://www.12306.cn/mormhweb/"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
request = urllib.request.Request(url, headers = headers)
response = urllib.request.urlopen(request)
print (response.read())
运行结果:
URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:749)>
所以,如果以后遇到这种网站,我们需要单独处理SSL证书,让程序忽略SSL证书验证错误,即可正常访问。
import urllib
# 1. 导入Python SSL处理模块
import ssl
# 2. 表示忽略未经核实的SSL证书认证
context = ssl._create_unverified_context()
url = "https://www.12306.cn/mormhweb/"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
request = urllib.request.Request(url, headers = headers)
# 3. 在urlopen()方法里 指明添加 context 参数
response = urllib.request.urlopen(request, context = context)
print (response.read().decode())
关于CA
CA(Certificate Authority)是数字证书认证中心的简称,是指发放、管理、废除数字证书的受信任的第三方机构
CA的作用是检查证书持有者身份的合法性,并签发证书,以防证书被伪造或篡改,以及对证书和密钥进行管理。
现实生活中可以用身份证来证明身份, 那么在网络世界里,数字证书就是身份证。和现实生活不同的是,并不是每个上网的用户都有数字证书的,往往只有当一个人需要证明自己的身份的时候才需要用到数字证书。
普通用户一般是不需要,因为网站并不关心是谁访问了网站,现在的网站只关心流量。但是反过来,网站就需要证明自己的身份了。
比如说现在钓鱼网站很多的,比如你想访问的是www.baidu.com,但其实你访问的是www.daibu.com”,所以在提交自己的隐私信息之前需要验证一下网站的身份,要求网站出示数字证书。
一般正常的网站都会主动出示自己的数字证书,来确保客户端和网站服务器之间的通信数据是加密安全的。
1.9 urllib:Handler处理器 和 自定义Opener
- opener是 urllib.request.OpenerDirector 的实例,我们之前一直都在使用的urlopen,它是一个特殊的opener(也就是模块帮我们构建好的)。
- 但是基本的urlopen()方法不支持代理、cookie等其他的HTTP/HTTPS高级功能。所以要支持这些功能:
- 使用相关的
Handler处理器来创建特定功能的处理器对象; - 然后通过
urllib.request.build_opener()方法使用这些处理器对象,创建自定义opener对象; - 使用自定义的opener对象,调用
open()方法发送请求。
- 使用相关的
- 如果程序里所有的请求都使用自定义的opener,可以使用
urllib.request.install_opener()将自定义的 opener 对象 定义为 全局opener,表示如果之后凡是调用urlopen,都将使用这个opener(根据自己的需求来选择)
简单的自定义opener()
import urllib.request
# 构建一个HTTPHandler 处理器对象,支持处理HTTP请求
http_handler = urllib.request.HTTPHandler()
# 构建一个HTTPHandler 处理器对象,支持处理HTTPS请求
# http_handler = urllib.request.HTTPSHandler()
# 调用urllib.request.build_opener()方法,创建支持处理HTTP请求的opener对象
opener = urllib.request.build_opener(http_handler)
# 构建 Request请求
request = urllib.request.Request("http://www.baidu.com/")
# 调用自定义opener对象的open()方法,发送request请求
response = opener.open(request)
# 获取服务器响应内容
print (response.read().decode())
这种方式发送请求得到的结果,和使用urllib.request.urlopen()发送HTTP/HTTPS请求得到的结果是一样的。
如果在 HTTPHandler()增加 debuglevel=1参数,还会将 Debug Log 打开,这样程序在执行的时候,会把收包和发包的报头在屏幕上自动打印出来,方便调试,有时可以省去抓包的工作。
# 仅需要修改的代码部分:
# 构建一个HTTPHandler 处理器对象,支持处理HTTP请求,同时开启Debug Log,debuglevel 值默认 0
http_handler = urllib.request.HTTPHandler(debuglevel=1)
# 构建一个HTTPHSandler 处理器对象,支持处理HTTPS请求,同时开启Debug Log,debuglevel 值默认 0
https_handler = urllib.request.HTTPSHandler(debuglevel=1)
ProxyHandler处理器(代理设置)
使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的。
很多网站会检测某一段时间某个IP的访问次数(通过流量统计,系统日志等),如果访问次数多的不像正常人,它会禁止这个IP的访问。
所以我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
urllib.request中通过ProxyHandler来设置使用代理服务器,下面代码说明如何使用自定义opener来使用代理:
#urllib_proxy1.py
import urllib.request
# 构建了两个代理Handler,一个有代理IP,一个没有代理IP
httpproxy_handler = urllib.request.ProxyHandler({"http" : "124.88.67.81:80"})
nullproxy_handler = urllib.request.ProxyHandler({})
proxySwitch = True #定义一个代理开关
# 通过 urllib.request.build_opener()方法使用这些代理Handler对象,创建自定义opener对象
# 根据代理开关是否打开,使用不同的代理模式
if proxySwitch:
opener = urllib.request.build_opener(httpproxy_handler)
else:
opener = urllib.request.build_opener(nullproxy_handler)
request = urllib.request.Request("http://www.baidu.com/")
# 1. 如果这么写,只有使用opener.open()方法发送请求才使用自定义的代理,而urlopen()则不使用自定义代理。
response = opener.open(request)
# 2. 如果这么写,就是将opener应用到全局,之后所有的,不管是opener.open()还是urlopen() 发送请求,都将使用自定义代理。
# urllib.request.install_opener(opener)
# response = urlopen(request)
print (response.read().decode())
免费的开放代理获取基本没有成本,我们可以在一些代理网站上收集这些免费代理,测试后如果可以用,就把它收集起来用在爬虫上面。
免费短期代理网站举例:
如果代理IP足够多,就可以像随机获取User-Agent一样,随机选择一个代理去访问网站。
import urllib.request
import random
proxy_list = [
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"}
]
# 随机选择一个代理
proxy = random.choice(proxy_list)
# 使用选择的代理构建代理处理器对象
httpproxy_handler = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(httpproxy_handler)
request = urllib.request.Request("http://www.baidu.com/")
response = opener.open(request)
print (response.read())
但是,这些免费开放代理一般会有很多人都在使用,而且代理有寿命短,速度慢,匿名度不高,HTTP/HTTPS支持不稳定等缺点(免费没好货)。
所以,专业爬虫工程师或爬虫公司会使用高品质的私密代理,这些代理通常需要找专门的代理供应商购买,再通过用户名/密码授权使用(舍不得孩子套不到狼)。
Cookie
Cookie 是指某些网站服务器为了辨别用户身份和进行Session跟踪,而储存在用户浏览器上的文本文件,Cookie可以保持登录信息到用户下次与服务器的会话。
Cookie原理
HTTP是无状态的面向连接的协议, 为了保持连接状态, 引入了Cookie机制 Cookie是http消息头中的一种属性,包括:
Cookie名字(Name)
Cookie的值(Value)
Cookie的过期时间(Expires/Max-Age)
Cookie作用路径(Path)
Cookie所在域名(Domain),
使用Cookie进行安全连接(Secure)。
前两个参数是Cookie应用的必要条件,另外,还包括Cookie大小(Size,不同浏览器对Cookie个数及大小限制是有差异的)。
Cookie由变量名和值组成,根据 Netscape公司的规定,Cookie格式如下:
Set-Cookie: NAME=VALUE;Expires=DATE;Path=PATH;Domain=DOMAIN_NAME;SECURE
Cookie应用
Cookies在爬虫方面最典型的应用是判定注册用户是否已经登录网站,用户可能会得到提示,是否在下一次进入此网站时保留用户信息以便简化登录手续。
# 获取一个有登录信息的Cookie模拟登陆
import urllib
# 1. 构建一个已经登录过的用户的headers信息
headers = {
"Host":"www.renren.com",
"Connection":"keep-alive",
"Upgrade-Insecure-Requests":"1",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language":"zh-CN,zh;q=0.8,en;q=0.6",
"Referer":"http://www.renren.com/SysHome.do",
# 便于终端阅读,表示不支持压缩文件
# Accept-Encoding: gzip, deflate, sdch,
# 重点:这个Cookie是保存了密码无需重复登录的用户的Cookie,这个Cookie里记录了用户名,密码(通常经过RAS加密)
"Cookie": "anonymid=j3jxk555-nrn0wh; depovince=BJ; _r01_=1; JSESSIONID=abcnLjz9MSvBa-3lJK3Xv; ick=3babfba4-e0ed-4e9f-9312-8e833e4cb826; jebecookies=764bacbd-0e4a-4534-b8e8-37c10560770c|||||; ick_login=84f70f68-7ebd-4c5c-9c0f-d1d9aac778e0; _de=7A7A02E9254501DA6278B9C75EAEEB7A; p=91063de8b39ac5e0d2a57500de7e34077; first_login_flag=1; ln_uact=13146128763; ln_hurl=http://head.xiaonei.com/photos/0/0/men_main.gif; t=39fca09219c06df42604435129960e1f7; societyguester=39fca09219c06df42604435129960e1f7; id=941954027; xnsid=8868df75; ver=7.0; loginfrom=null; XNESSESSIONID=a6da759fe858; WebOnLineNotice_941954027=1; wp_fold=0"
}
# 2. 通过headers里的报头信息(主要是Cookie信息),构建Request对象
urllib.request.Request("http://www.renren.com/941954027#", headers = headers)
# 3. 直接访问renren主页,服务器会根据headers报头信息(主要是Cookie信息),判断这是一个已经登录的用户,并返回相应的页面
response = urllib.request.urlopen(request)
# 4. 打印响应内容
print (response.read().decode())

但是这样做太过复杂,我们先需要在浏览器登录账户,并且设置保存密码,并且通过抓包才能获取这个Cookie,那有么有更简单方便的方法呢?
cookiejar库 和 HTTPCookieProcessor处理器
在Python处理Cookie,一般是通过cookiejar模块和 urllib模块的HTTPCookieProcessor处理器类一起使用。
cookiejar模块:主要作用是提供用于存储cookie的对象
HTTPCookieProcessor处理器:主要作用是处理这些cookie对象,并构建handler对象。
cookiejar 库
该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
- CookieJar:管理HTTP cookie值、存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失。
我们来做几个案例:
1)获取Cookie,并保存到CookieJar()对象中
# urllib_cookiejar_test1.py
import urllib
from http import cookiejar
# 构建一个CookieJar对象实例来保存cookie
cookiejar = cookiejar.CookieJar()
# 使用HTTPCookieProcessor()来创建cookie处理器对象,参数为CookieJar()对象
handler=urllib.request.HTTPCookieProcessor(cookiejar)
# 通过 build_opener() 来构建opener
opener = urllib.request.build_opener(handler)
# 4. 以get方法访问页面,访问之后会自动保存cookie到cookiejar中
opener.open("http://www.baidu.com")
## 可以按标准格式将保存的Cookie打印出来
cookieStr = ""
for item in cookiejar:
cookieStr = cookieStr + item.name + "=" + item.value + ";"
## 舍去最后一位的分号
print (cookieStr[:-1])
我们使用以上方法将Cookie保存到cookiejar对象中,然后打印出了cookie中的值,也就是访问百度首页的Cookie值。
运行结果如下:
BAIDUID=4327A58E63A92B73FF7A297FB3B2B4D0:FG=1;BIDUPSID=4327A58E63A92B73FF7A297FB3B2B4D0;H_PS_PSSID=1429_21115_17001_21454_21409_21554_21398;PSTM=1480815736;BDSVRTM=0;BD_HOME=0
利用cookiejar和post登录人人网
import urllib
from http import cookiejar
# 1. 构建一个CookieJar对象实例来保存cookie
cookie = cookiejar.CookieJar()
# 2. 使用HTTPCookieProcessor()来创建cookie处理器对象,参数为CookieJar()对象
cookie_handler = urllib.request.HTTPCookieProcessor(cookie)
# 3. 通过 build_opener() 来构建opener
opener = urllib.request.build_opener(cookie_handler)
# 4. addheaders 接受一个列表,里面每个元素都是一个headers信息的元祖, opener将附带headers信息
opener.addheaders = [("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36")]
# 5. 需要登录的账户和密码
data = {"email":"13****46**8763", "password":"****"}
# 6. 通过urlencode()转码
postdata = urllib.parse.urlencode(data).encode()
# 7. 构建Request请求对象,包含需要发送的用户名和密码
request = urllib.request.Request("http://www.renren.com/PLogin.do", data = postdata)
# 8. 通过opener发送这个请求,并获取登录后的Cookie值,
opener.open(request)
# 9. opener包含用户登录后的Cookie值,可以直接访问那些登录后才可以访问的页面
response = opener.open("http://www.renren.com/410043129/profile")
# 10. 打印响应内容
print (response.read().decode())
模拟登录要注意几点:
- 登录一般都会先有一个HTTP GET,用于拉取一些信息及获得Cookie,然后再HTTP POST登录。
- HTTP POST登录的链接有可能是动态的,从GET返回的信息中获取。
- password 有些是明文发送,有些是加密后发送。有些网站甚至采用动态加密的,同时包括了很多其他数据的加密信息,只能通过查看JS源码获得加密算法,再去破解加密,非常困难。
- 大多数网站的登录整体流程是类似的,可能有些细节不一样,所以不能保证其他网站登录成功。
这个测试案例中,为了想让大家快速理解知识点,我们使用的人人网登录接口是人人网改版前的隐藏接口(嘘…),登录比较方便。
当然,我们也可以直接发送账号密码到登录界面模拟登录,但是当网页采用JavaScript动态技术以后,想封锁基于 HttpClient 的模拟登录就太容易了,甚至可以根据你的鼠标活动的特征准确地判断出是不是真人在操作。
所以,想做通用的模拟登录还得选别的技术,比如用内置浏览器引擎的爬虫(关键词:Selenium ,PhantomJS),这个我们将在以后会学习到。
1.10 编码故事
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。他们看到8个开关状态是好的,于是他们把这称为"字节"。
再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始变来变去。他们看到这样是好的,于是它们就这机器称为"计算机"。
开始计算机只在美国用。八位的字节一共可以组合出256(2的8次方)种不同的状态。
他们把其中的编号从0开始的32种状态分别规定了特殊的用途,一但终端、打印机遇上约定好的这些字节被传过来时,就要做一些约定的动作。遇上00x10, 终端就换行,遇上0x07, 终端就向人们嘟嘟叫,例好遇上0x1b, 打印机就打印反白的字,或者终端就用彩色显示字母。他们看到这样很好,于是就把这些0x20以下的字节状态称为"控制码"。
他们又把所有的空格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第127号,这样计算机就可以用不同字节来存储英语的文字了。大家看到这样,都感觉很好,于是大家都把这个方案叫做 ANSI 的"Ascii"编码(American Standard Code for Information Interchange,美国信息互换标准代码)。当时世界上所有的计算机都用同样的ASCII方案来保存英文文字。
后来,就像建造巴比伦塔一样,世界各地的都开始使用计算机,但是很多国家用的不是英文,他们的字母里有许多是ASCII里没有的,为了可以在计算机保存他们的文字,他们决定采用127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。从128到255这一页的字符集被称"扩展字符集"。从此之后,贪婪的人类再没有新的状态可以用了,美帝国主义可能没有想到还有第三世界国家的人们也希望可以用到计算机吧!
等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢。但是这难不倒智慧的中国人民,我们不客气地把那些127号之后的奇异符号们直接取消掉, 规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
中国人民看到这样很不错,于是就把这种汉字方案叫做 “GB2312”。GB2312 是对 ASCII 的中文扩展。
但是中国的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来,特别是某些很会麻烦别人的国家领导人。于是我们不得不继续把 GB2312 没有用到的码位找出来老实不客气地用上。
后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK 扩成了 GB18030。从此之后,中华民族的文化就可以在计算机时代中传承了。
中国的程序员们看到这一系列汉字编码的标准是好的,于是通称他们叫做 “DBCS”(Double Byte Charecter Set 双字节字符集)。在DBCS系列标准里,最大的特点是两字节长的汉字字符和一字节长的英文字符并存于同一套编码方案里,因此他们写的程序为了支持中文处理,必须要注意字串里的每一个字节的值,如果这个值是大于127的,那么就认为一个双字节字符集里的字符出现了。那时候凡是受过加持,会编程的计算机僧侣们都要每天念下面这个咒语数百遍:
“一个汉字算两个英文字符!一个汉字算两个英文字符……”
因为当时各个国家都像中国这样搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码,谁也不支持别人的编码,连大陆和台湾这样只相隔了150海里,使用着同一种语言的兄弟地区,也分别采用了不同的 DBCS 编码方案——当时的中国人想让电脑显示汉字,就必须装上一个"汉字系统",专门用来处理汉字的显示、输入的问题,但是那个台湾的愚昧封建人士写的算命程序就必须加装另一套支持 BIG5 编码的什么"倚天汉字系统"才可以用,装错了字符系统,显示就会乱了套!这怎么办?而且世界民族之林中还有那些一时用不上电脑的穷苦人民,他们的文字又怎么办?
真是计算机的巴比伦塔命题啊!
正在这时,大天使加百列及时出现了——一个叫 ISO (国际标谁化组织)的国际组织决定着手解决这个问题。他们采用的方法很简单:废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号的编码!他们打算叫它"Universal Multiple-Octet Coded Character Set",简称 UCS, 俗称 “UNICODE”。
UNICODE 开始制订时,计算机的存储器容量极大地发展了,空间再也不成为问题了。于是 ISO 就直接规定必须用两个字节,也就是16位来统一表示所有的字符,对于ascii里的那些“半角”字符,UNICODE 包持其原编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码。由于"半角"英文符号只需要用到低8位,所以其高8位永远是0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。
这时候,从旧社会里走过来的程序员开始发现一个奇怪的现象:他们的strlen函数靠不住了,一个汉字不再是相当于两个字符了,而是一个!是的,从 UNICODE 开始,无论是半角的英文字母,还是全角的汉字,它们都是统一的"一个字符"!同时,也都是统一的"两个字节",请注意"字符"和"字节"两个术语的不同,“字节”是一个8位的物理存贮单元,而“字符”则是一个文化相关的符号。在UNICODE 中,一个字符就是两个字节。一个汉字算两个英文字符的时代已经快过去了。
从前多种字符集存在时,那些做多语言软件的公司遇上过很大麻烦,他们为了在不同的国家销售同一套软件,就不得不在区域化软件时也加持那个双字节字符集咒语,不仅要处处小心不要搞错,还要把软件中的文字在不同的字符集中转来转去。UNICODE 对于他们来说是一个很好的一揽子解决方案,于是从 Windows NT 开始,MS 趁机把它们的操作系统改了一遍,把所有的核心代码都改成了用 UNICODE 方式工作的版本,从这时开始,WINDOWS 系统终于无需要加装各种本土语言系统,就可以显示全世界上所有文化的字符了。
但是,UNICODE 在制订时没有考虑与任何一种现有的编码方案保持兼容,这使得 GBK 与UNICODE 在汉字的内码编排上完全是不一样的,没有一种简单的算术方法可以把文本内容从UNICODE编码和另一种编码进行转换,这种转换必须通过查表来进行。
如前所述,UNICODE 是用两个字节来表示为一个字符,他总共可以组合出65535不同的字符,这大概已经可以覆盖世界上所有文化的符号。如果还不够也没有关系,ISO已经准备了UCS-4方案,说简单了就是四个字节来表示一个字符,这样我们就可以组合出21亿个不同的字符出来(最高位有其他用途),这大概可以用到银河联邦成立那一天吧!
UNICODE 来到时,一起到来的还有计算机网络的兴起,UNICODE 如何在网络上传输也是一个必须考虑的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF8就是每次8个位传输数据,而UTF16就是每次16个位,只不过为了传输时的可靠性,从UNICODE到UTF时并不是直接的对应,而是要过一些算法和规则来转换。
总结:
- 字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。字符集(Character set)是多个字符的集合
- 字符集包括:ASCII字符集、GB2312字符集、GB18030字符集、Unicode字符集等
- ASCII编码是1个字节,而Unicode编码通常是2个字节。
- UTF-8是Unicode的实现方式之一,UTF-8是它是一种变长的编码方式,可以是1,2,3个字节
第二章:非结构化数据和结构化数据的提取
非结构化数据和结构化数据的提取)
页面解析和数据提取
一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值。内容一般分为两部分,非结构化的数据 和 结构化的数据。
- 非结构化数据:先有数据,再有结构,(http://www.baidu.com)/)
- 结构化数据:先有结构、再有数据(http://wangyi.butterfly.mopaasapp.com/news/api?type=war&page=1&limit=10)
- 不同类型的数据,我们需要采用不同的方式来处理。
非结构化的数据处理
文本、电话号码、邮箱地址
- 正则表达式
HTML 文件
- 正则表达式
- XPath
- CSS选择器
结构化的数据处理
JSON 文件
- JSON Path
- 转化成Python类型进行操作(json类)
XML 文件
- 转化成Python类型(xmltodict)
- XPath
- CSS选择器
- 正则表达式
2.1 正则表达式RE模块
为什么要学正则表达式
实际上爬虫一共就四个主要步骤:
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 去 (去掉对我们没用处的数据)
- 处理数据(按照我们想要的方式存储和使用)
我们在昨天的案例里实际上省略了第3步,也就是"取"的步骤。因为我们down下了的数据是全部的网页,这些数据很庞大并且很混乱,大部分的东西使我们不关心的,因此我们需要将之按我们的需要过滤和匹配出来。
那么对于文本的过滤或者规则的匹配,最强大的就是正则表达式,是Python爬虫世界里必不可少的神兵利器。
什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
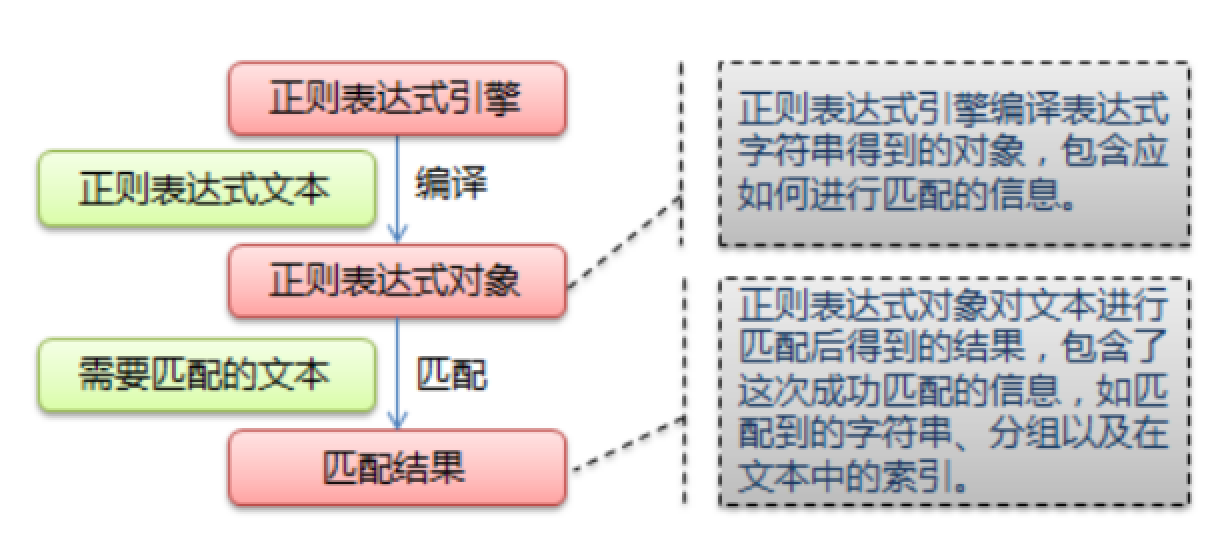
正则表达式匹配规则
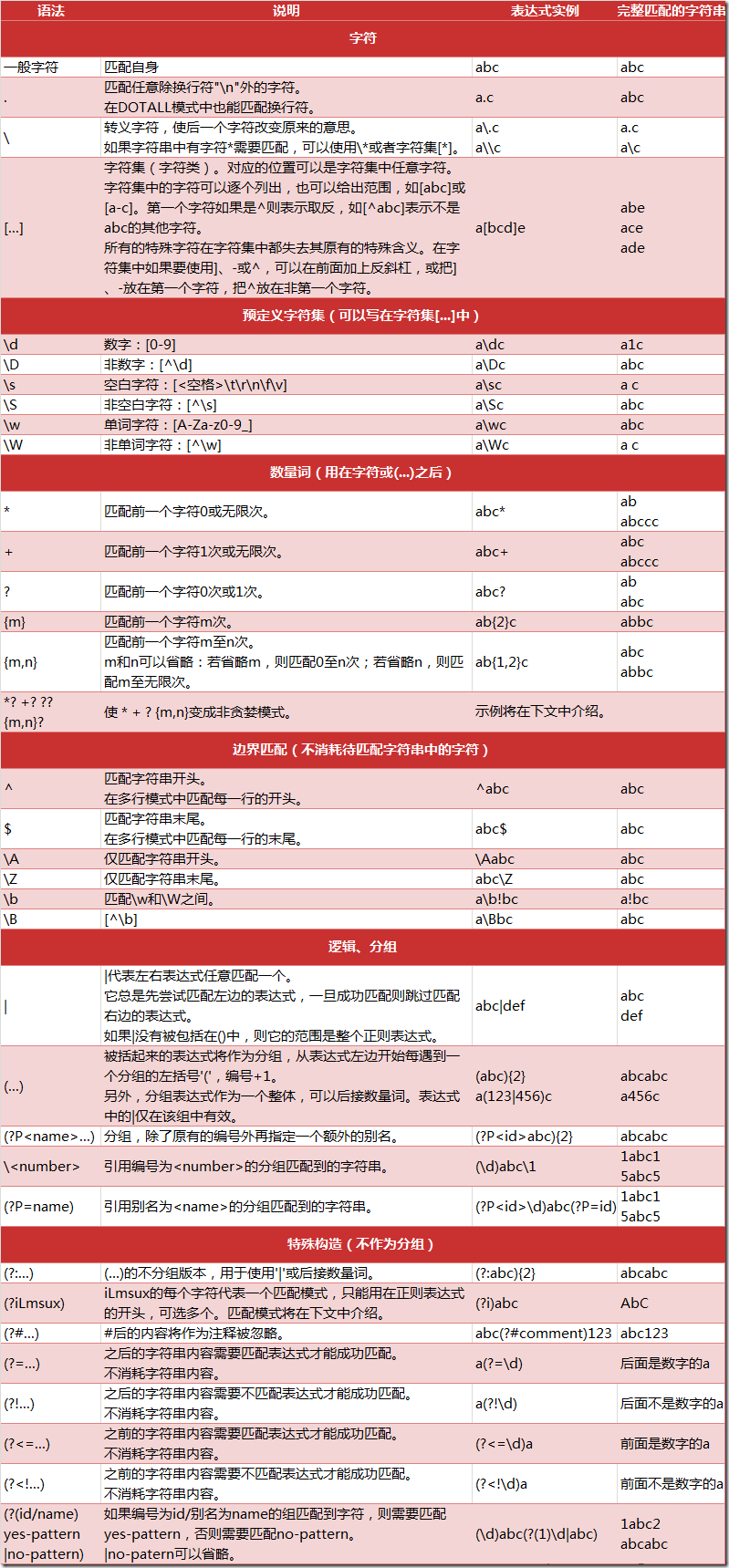
Python 的 re 模块
在 Python 中,我们可以使用内置的 re 模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用 对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀,示例:
r'chuanzhiboke\t\.\tpython'
re 模块的一般使用步骤如下:
- 使用
compile()函数将正则表达式的字符串形式编译为一个Pattern对象 - 通过
Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象。 - 最后使用
Match对象提供的属性和方法获得信息,根据需要进行其他的操作
compile 函数
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:
import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
在上面,我们已将一个正则表达式编译成 Pattern 对象,接下来,我们就可以利用 pattern 的一系列方法对文本进行匹配查找了。
Pattern 对象的一些常用方法主要有:
- match 方法:从起始位置开始查找,一次匹配
- search 方法:从任何位置开始查找,一次匹配
- findall 方法:全部匹配,返回列表
- finditer 方法:全部匹配,返回迭代器
- split 方法:分割字符串,返回列表
- sub 方法:替换
match 方法
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。它的一般使用形式如下:
match(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。因此,当你不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
>>> import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print (m)
None
>>> m = pattern.match('one12twothree34four', 2) # 从'e'的位置开始匹配,没有匹配
>>> print (m)
None
>>> m = pattern.match('one12twothree34four', 3) # 从'1'的位置开始匹配,正好匹配
>>> print (m) # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
在上面,当匹配成功时返回一个 Match 对象,其中:
- group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
- start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
- end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
- span([group]) 方法返回 (start(group), end(group))。
再看看一个例子:
>>> import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
>>> m = pattern.match('Hello World Wide Web')
>>> print (m) # 匹配成功,返回一个 Match 对象
<_sre.SRE_Match object at 0x10bea83e8>
>>> m.group(0) # 返回匹配成功的整个子串
'Hello World'
>>> m.span(0) # 返回匹配成功的整个子串的索引
(0, 11)
>>> m.group(1) # 返回第一个分组匹配成功的子串
'Hello'
>>> m.span(1) # 返回第一个分组匹配成功的子串的索引
(0, 5)
>>> m.group(2) # 返回第二个分组匹配成功的子串
'World'
>>> m.span(2) # 返回第二个分组匹配成功的子串
(6, 11)
>>> m.groups() # 等价于 (m.group(1), m.group(2), ...)
('Hello', 'World')
>>> m.group(3) # 不存在第三个分组
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
search 方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,它的一般使用形式如下:
search(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
让我们看看例子:
>>> import re
>>> pattern = re.compile('\d+')
>>> m = pattern.search('one12twothree34four') # 这里如果使用 match 方法则不匹配
>>> m
<_sre.SRE_Match object at 0x10cc03ac0>
>>> m.group()
'12'
>>> m = pattern.search('one12twothree34four', 10, 30) # 指定字符串区间
>>> m
<_sre.SRE_Match object at 0x10cc03b28>
>>> m.group()
'34'
>>> m.span()
(13, 15)
再来看一个例子:
# -*- coding: utf-8 -*-
import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
# 使用 search() 查找匹配的子串,不存在匹配的子串时将返回 None
# 这里使用 match() 无法成功匹配
m = pattern.search('hello 123456 789')
if m:
# 使用 Match 获得分组信息
print ('matching string:',m.group())
# 起始位置和结束位置
print ('position:',m.span())
执行结果:
matching string: 123456
position: (6, 12)
findall 方法
上面的 match 和 search 方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,我们需要搜索整个字符串,获得所有匹配的结果。
findall 方法的使用形式如下:
findall(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
看看例子:
import re
pattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('hello 123456 789')
result2 = pattern.findall('one1two2three3four4', 0, 10) #(表示切片[0:10])
print (result1)
print (result2)
执行结果:
['123456', '789']
['1', '2']
再先看一个栗子:
# re_test.py
import re
#re模块提供一个方法叫compile模块,提供我们输入一个匹配的规则
#然后返回一个pattern实例,我们根据这个规则去匹配字符串
pattern = re.compile(r'\d+\.\d*')
#通过partten.findall()方法就能够全部匹配到我们得到的字符串
result = pattern.findall("123.141593, 'bigcat', 232312, 3.15")
#findall 以 列表形式 返回全部能匹配的子串给result
for item in result:
print (item)
运行结果:
123.141593
3.15
finditer 方法
finditer 方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match 对象)的迭代器。
看看例子:
# -*- coding: utf-8 -*-
import re
pattern = re.compile(r'\d+')
result_iter1 = pattern.finditer('hello 123456 789')
result_iter2 = pattern.finditer('one1two2three3four4', 0, 10)
print (type(result_iter1))
print (type(result_iter2))
print 'result1...'
for m1 in result_iter1: # m1 是 Match 对象
print ('matching string: {}, position: {}'.format(m1.group(), m1.span()))
print 'result2...'
for m2 in result_iter2:
print ('matching string: {}, position: {}'.format(m2.group(), m2.span()))
执行结果:
<type 'callable-iterator'>
<type 'callable-iterator'>
result1...
matching string: 123456, position: (6, 12)
matching string: 789, position: (13, 16)
result2...
matching string: 1, position: (3, 4)
matching string: 2, position: (7, 8)
split 方法
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
split(string[, maxsplit])
其中,maxsplit 用于指定最大分割次数,不指定将全部分割。
看看例子:
import re
p = re.compile(r'[\s\,\;]+')
print (p.split('a,b;; c d'))
执行结果:
['a', 'b', 'c', 'd']
sub 方法
sub 方法用于替换。它的使用形式如下:
sub(repl, string[, count])
其中,repl 可以是字符串也可以是一个函数:
- 如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还可以使用 id 的形式来引用分组,但不能使用编号 0;
- 如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
- count 用于指定最多替换次数,不指定时全部替换。
看看例子:
import re
p = re.compile(r'(\w+) (\w+)') # \w = [A-Za-z0-9]
s = 'hello 123, hello 456'
print (p.sub(r'hello world', s)) # 使用 'hello world' 替换 'hello 123' 和 'hello 456'
print (p.sub(r'\2 \1', s)) # 引用分组
def func(m):
print(m)
return 'hi' + ' ' + m.group(2) #group(0) 表示本身,group(1)表示hello,group(2) 表示后面的数字
print (p.sub(func, s)) #多次sub,每次sub的结果传递给func
print (p.sub(func, s, 1)) # 最多替换一次
执行结果:
hello world, hello world
123 hello, 456 hello
hi 123, hi 456
hi 123, hello 456
匹配中文
在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码范围 主要在 [u4e00-u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
假设现在想把字符串 title = u’你好,hello,世界’ 中的中文提取出来,可以这么做:
import re
title = '你好,hello,世界'
pattern = re.compile(r'[\u4e00-\u9fa5]+')
result = pattern.findall(title)
print (result)
注意到,我们在正则表达式前面加上了两个前缀 ur,其中 r 表示使用原始字符串,u 表示是 unicode 字符串。
执行结果:
['你好', '世界']
注意:贪婪模式与非贪婪模式
- 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配 ( * );
- 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配 ( ? );
- Python里数量词默认是贪婪的。
示例一 : 源字符串:abbbc
-
使用贪婪的数量词的正则表达式
ab*,匹配结果: abbb。*决定了尽可能多匹配 b,所以a后面所有的 b 都出现了。 -
使用非贪婪的数量词的正则表达式
ab*?,匹配结果: a。即使前面有
*,但是?决定了尽可能少匹配 b,所以没有 b。
示例二 : 源字符串:aa<div>test1</div>bb<div>test2</div>cc
- 使用贪婪的数量词的正则表达式:
<div>.*</div> - 匹配结果:
<div>test1</div>bb<div>test2</div>
这里采用的是贪婪模式。在匹配到第一个"
</div>“时已经可以使整个表达式匹配成功,但是由于采用的是贪婪模式,所以仍然要向右尝试匹配,查看是否还有更长的可以成功匹配的子串。匹配到第二个”</div>“后,向右再没有可以成功匹配的子串,匹配结束,匹配结果为”<div>test1</div>bb<div>test2</div>"
- 使用非贪婪的数量词的正则表达式:
<div>.*?</div> - 匹配结果:
<div>test1</div>
正则表达式二采用的是非贪婪模式,在匹配到第一个"
</div>“时使整个表达式匹配成功,由于采用的是非贪婪模式,所以结束匹配,不再向右尝试,匹配结果为”<div>test1</div>"。
2.2 案例:使用正则表达式的爬虫
现在拥有了正则表达式这把神兵利器,我们就可以进行对爬取到的全部网页源代码进行筛选了。
2.3 Xpath与lxml库
有同学说,我正则用的不好,处理HTML文档很累,有没有其他的方法?
有!那就是XPath,我们可以先将 HTML文件 转换成 XML文档,然后用 XPath 查找 HTML 节点或元素。
什么是XML
- XML 指可扩展标记语言(EXtensible Markup Language)
- XML 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
- XML 的标签需要我们自行定义。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准
W3School官方文档:http://www.w3school.com.cn/xml/index.asp
XML 和 HTML 的区别
| 数据格式 | 描述 | 设计目标 |
|---|---|---|
| XML | Extensible Markup Language (可扩展标记语言) |
被设计为传输和存储数据,其焦点是数据的内容。 |
| HTML | HyperText Markup Language (超文本标记语言) |
显示数据以及如何更好显示数据。 |
| HTML DOM | Document Object Model for HTML (文档对象模型) |
通过 HTML DOM,可以访问所有的 HTML 元素,连同它们所包含的文本和属性。可以对其中的内容进行修改和删除,同时也可以创建新的元素。 |
XML文档示例
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
HTML DOM 模型示例
HTML DOM 定义了访问和操作 HTML 文档的标准方法,以树结构方式表达 HTML 文档。
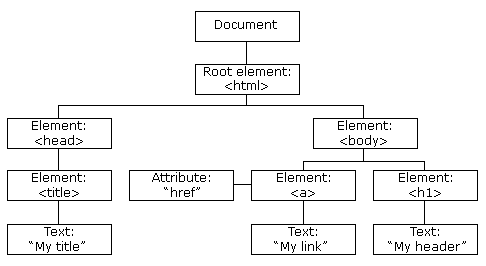
XML的节点关系
1. 父(Parent)
每个元素以及属性都有一个父。
下面是一个简单的XML例子中,book 元素是 title、author、year 以及 price 元素的父:
<?xml version="1.0" encoding="utf-8"?>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
2. 子(Children)
元素节点可有零个、一个或多个子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
<?xml version="1.0" encoding="utf-8"?>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
3. 同胞(Sibling)
拥有相同的父的节点
在下面的例子中,title、author、year 以及 price 元素都是同胞:
<?xml version="1.0" encoding="utf-8"?>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
4. 先辈(Ancestor)
某节点的父、父的父,等等。
在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素:
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
5. 后代(Descendant)
某个节点的子,子的子,等等。
在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素:
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
什么是XPath?
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
XPath 开发工具
- 开源的XPath表达式编辑工具:XMLQuire(XML格式文件可用
- Chrome插件 XPath Helper
- Firefox插件 XPath Checker
选取节点
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
下面列出了最常用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 | |
|---|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 | |
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! | |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 | |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 | |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 | |
| //@lang | 选取名为 lang 的所有属性。 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()❤️] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| html/node()/meta/@* | 选择html下面任意节点下的meta节点的所有属性 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
XPath的运算符
下面列出了可用在 XPath 表达式中的运算符:
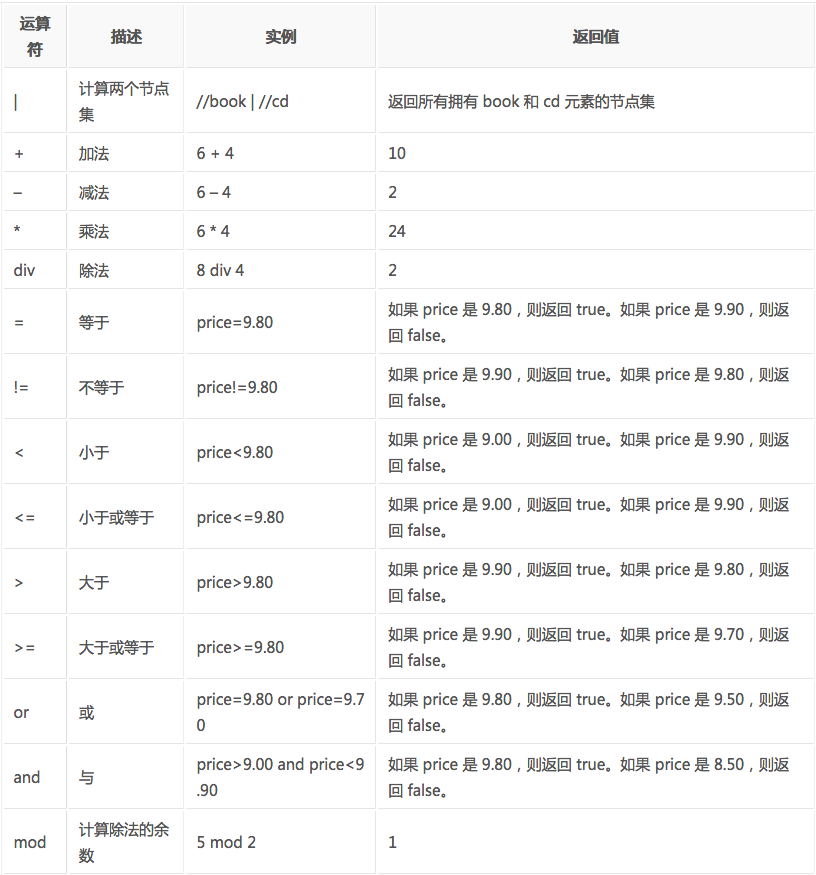
这些就是XPath的语法内容,在运用到Python抓取时要先转换为xml。
lxml库
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
lxml python 官方文档:http://lxml.de/index.html
需要安装C语言库,可使用 pip 安装:
pip install lxml(或通过wheel方式安装)
初步使用
我们利用它来解析 HTML 代码,简单示例:
# lxml_test.py
# 使用 lxml 的 etree 库
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a> # 注意,此处缺少一个 </li> 闭合标签
</ul>
</div>
'''
#利用etree.HTML,将字符串解析为HTML文档
html = etree.HTML(text)
# 按字符串序列化HTML文档
result = etree.tostring(html)
print(result)
输出结果:
<html><body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</body></html>
lxml 可以自动修正 html 代码,例子里不仅补全了 li 标签,还添加了 body,html 标签。
文件读取:
除了直接读取字符串,lxml还支持从文件里读取内容。我们新建一个hello.html文件:
<!-- hello.html -->
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
再利用 etree.parse() 方法来读取文件。
# lxml_parse.py
from lxml import etree
# 读取外部文件 hello.html
html = etree.parse('./hello.html')
result = etree.tostring(html, pretty_print=True)
print(result)
输出结果与之前相同:
<html><body>
<div>
<ul>
<li class="item-0">
<a href="link1.html">first item</a>
</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</body></html>
XPath实例测试
- 获取所有的
<li>标签
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
print type(html) # 显示etree.parse() 返回类型
result = html.xpath('//li')
print result # 打印<li>标签的元素集合
print len(result)
print type(result)
print type(result[0])
输出结果:
<type 'lxml.etree._ElementTree'>
[<Element li at 0x1014e0e18>, <Element li at 0x1014e0ef0>, <Element li at 0x1014e0f38>, <Element li at 0x1014e0f80>, <Element li at 0x1014e0fc8>]
5
<type 'list'>
<type 'lxml.etree._Element'>
- 继续获取
<li>标签的所有class属性
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/@class')
print result
运行结果
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
- 继续获取
<li>标签下hre为link1.html的<a>标签
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/a[@href="link1.html"]')
print result
运行结果
[<Element a at 0x10ffaae18>]
- 获取
<li>标签下的所有<span>标签
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
#result = html.xpath('//li/span')
#注意这么写是不对的:
#因为 / 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠
result = html.xpath('//li//span')
print result
运行结果
[]
- 获取
<li>标签下的<a>标签里的所有 href
from lxml import etree
html = etree.parse('data/hello.html')
#result = html.xpath('//li/span')
#注意这么写是不对的:
#因为 / 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠
result = html.xpath('//li/a/@href')
print (result)
运行结果
['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
- 获取最后一个
<li>的<a>的 href
# xpath_li.py
from lxml import etree
html = etree.parse('data/hello.html')
result = html.xpath('//li[last()]/a/@href')
# 谓语 [last()] 可以找到最后一个元素
print (result)
运行结果
['link5.html']
- 获取倒数第二个元素的内容
# xpath_li.py
from lxml import etree
html = etree.parse('data/hello.html')
result = html.xpath('//li[last()-1]/a')
# text 方法可以获取元素内容
print (result[0].text)
运行结果
fourth item
2.4 案例:使用XPath的爬虫
现在我们用XPath来做一个简单的爬虫,我们尝试爬取某个贴吧里的所有帖子,并且将该这个帖子里每个楼层的信息打印出来。
from urllib import request,parse
from lxml import etree
global i
i = 0
def loadPage(url) :
#headers = {'User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'}
#req = request.Request(url,headers=headers) #构建请求体
response = request.urlopen(url) #发送请求-得到响应对象
html = response.read() #读取响应内容
return html
def writePage(html,filename):
html = html.decode('utf-8')
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
print('正在下载%s·····'%filename)
def teibaSpider(url):
name = input('请输入贴吧名字:')
beginPage = int(input('请输入起始页:'))
endPage = int(input('请输入结束页:'))
kw = {'kw':name}
ret = parse.urlencode(kw)
print(ret)
url = url + ret + '&pn='
for page in range(beginPage,endPage+1):
pn = (page-1) * 50
fullurl = url + str(pn)
print(fullurl)
html = loadPage(fullurl)
filename = name+'吧第%s页.html'%page
#tiebaInfo = name+'吧第%s页.html'%page + 'Info'
writePage(html, filename)
tiebaInfo(html)
def writeInfo(info,filename):
with open(filename, 'a', encoding='utf-8') as f:
f.write(info)
def loadImage(url):
'''匹配图片url'''
html = loadPage(url) #发送请求得到响应内容
content = etree.HTML(html) #解析html文档
imgUrl_list = content.xpath("//img[@class='BDE_Image']/@src")
for imgUrl in imgUrl_list:
print(imgUrl)
writeImage(imgUrl)
def writeImage(url):
'''将图片写入到本地'''
img = loadPage(url)
#filename = url[-15:]
global i
i += 1
filename = str(i) + '.jpg'
with open('G:\\pythonProject\\pc\\爬虫\\data\%s'%filename,'wb') as f:
f.write(img)
print('正在下载%s图片'%filename)
def tiebaInfo(html):
# 解析HTML文档
content = etree.HTML(html)
print(content)
# 通过xpath规则匹配对应的数据信息
title_list = content.xpath("//div[@class='t_con cleafix']/div/div/div/a/text()")
link_list = content.xpath("//div[@class='t_con cleafix']/div/div/div/a/@href")
replies_list = content.xpath("//div[@class='t_con cleafix']/div/span/text()")
writer_list = content.xpath("//div[@class='t_con cleafix']/div[2]/div[1]/div[2]/span[1]/@title")
introduce_list = content.xpath("//div[@class='t_con cleafix']/div[2]/div[2]/div/div/text()")
lastResponer_list = content.xpath("//div[@class='t_con cleafix']/div[2]/div[2]/div[2]/span[1]/@title")
lastResponTime_list = content.xpath("//div[@class='t_con cleafix']/div[2]/div[2]/div[2]/span[2]/text()")
#print(type(lastResponTime_list))
for title, link ,replies,writer,introduce,lastResponer,lastResponTime in zip(title_list, link_list, replies_list,writer_list,introduce_list,lastResponer_list,lastResponTime_list):
fulllink = 'https://tieba.baidu.com'+link
info = ' 标题:%s\n 链接:%s\n 回复数:%s\n 楼主名:%s\n %s\n 最后回复时间:%s\n 简介:%s\n '%(title, fulllink ,replies,writer,lastResponer,lastResponTime,introduce)
print(info)
loadImage(fulllink)
filename = 'tiebaInfo'
writeInfo(info, filename)
if __name__ == '__main__':
url = 'https://tieba.baidu.com/f?'
teibaSpider(url)
2.5 数据提取之JSON与JsonPATH
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
JSON和XML的比较可谓不相上下。
Python 2.7中自带了JSON模块,直接import json就可以使用了。
官方文档:http://docs.python.org/library/json.html
Json在线解析网站:http://www.json.cn/#
JSON
json简单说就是javascript中的对象和数组,所以这两种结构就是对象和数组两种结构,通过这两种结构可以表示各种复杂的结构
- 对象:对象在js中表示为
{ }括起来的内容,数据结构为{ key:value, key:value, ... }的键值对的结构,在面向对象的语言中,key为对象的属性,value为对应的属性值,所以很容易理解,取值方法为 对象.key 获取属性值,这个属性值的类型可以是数字、字符串、数组、对象这几种。- 数组:数组在js中是中括号
[ ]括起来的内容,数据结构为["Python", "javascript", "C++", ...],取值方式和所有语言中一样,使用索引获取,字段值的类型可以是 数字、字符串、数组、对象几种。
import json
json模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换。
- json.loads()
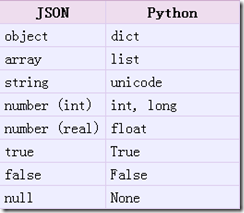
把Json格式字符串解码转换成Python对象 从json到python的类型转化对照如下:
# json_loads.py
import json
strList = '[1, 2, 3, 4]'
strDict = '{"city": "北京", "name": "大猫"}'
json.loads(strList)
# [1, 2, 3, 4]
json.loads(strDict) # json数据自动按Unicode存储
# {u'city': u'\u5317\u4eac', u'name': u'\u5927\u732b'}
- json.dumps()
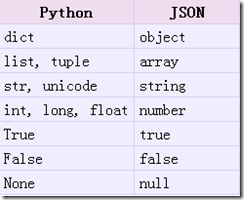
实现python类型转化为json字符串,返回一个str对象 把一个Python对象编码转换成Json字符串
从python原始类型向json类型的转化对照如下:
# json_dumps.py
import json
import chardet
listStr = [1, 2, 3, 4]
tupleStr = (1, 2, 3, 4)
dictStr = {"city": "北京", "name": "大猫"}
json.dumps(listStr)
# '[1, 2, 3, 4]'
json.dumps(tupleStr)
# '[1, 2, 3, 4]'
# 注意:json.dumps() 序列化时默认使用的ascii编码
# 添加参数 ensure_ascii=False 禁用ascii编码,按utf-8编码
# chardet.detect()返回字典, 其中confidence是检测精确度
json.dumps(dictStr)
# '{"city": "\\u5317\\u4eac", "name": "\\u5927\\u5218"}'
chardet.detect(json.dumps(dictStr))
# {'confidence': 1.0, 'encoding': 'ascii'}
print(json.dumps(dictStr, ensure_ascii=False))
# {"city": "北京", "name": "大刘"}
chardet.detect(json.dumps(dictStr, ensure_ascii=False))
# {'confidence': 0.99, 'encoding': 'utf-8'}
*chardet是一个非常优秀的编码识别模块,可通过pip安装*
- json.dump()
将Python内置类型序列化为json对象后写入文件
# json_dump.py
import json
listStr = [{"city": "北京"}, {"name": "大刘"}]
json.dump(listStr, open("listStr.json","w"), ensure_ascii=False)
dictStr = {"city": "北京", "name": "大刘"}
json.dump(dictStr, open("dictStr.json","w"), ensure_ascii=False)
- json.load()
读取文件中json形式的字符串元素 转化成python类型
# json_load.py
import json
strList = json.load(open("listStr.json"))
print(strList)
# [{u'city': u'\u5317\u4eac'}, {u'name': u'\u5927\u5218'}]
strDict = json.load(open("dictStr.json"))
print (strDict)
# {u'city': u'\u5317\u4eac', u'name': u'\u5927\u5218'}
JsonPath(了解)
JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java。
JsonPath 对于 JSON 来说,相当于 XPATH 对于 XML。
下载地址:https://pypi.python.org/pypi/jsonpath
安装方法:点击
Download URL链接下载jsonpath,解压之后执行python setup.py install
JsonPath与XPath语法对比:
Json结构清晰,可读性高,复杂度低,非常容易匹配,下表中对应了XPath的用法。
| XPath | JSONPath | 描述 |
|---|---|---|
/ |
$ |
根节点 |
. |
@ |
现行节点 |
/ |
.or[] |
取子节点 |
.. |
n/a | 取父节点,Jsonpath未支持 |
// |
.. |
就是不管位置,选择所有符合条件的条件 |
* |
* |
匹配所有元素节点 |
@ |
n/a | 根据属性访问,Json不支持,因为Json是个Key-value递归结构,不需要。 |
[] |
[] |
迭代器标示(可以在里边做简单的迭代操作,如数组下标,根据内容选值等) |
| | | [,] |
支持迭代器中做多选。 |
[] |
?() |
支持过滤操作. |
| n/a | () |
支持表达式计算 |
() |
n/a | 分组,JsonPath不支持 |
示例:
我们以拉勾网城市JSON文件 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,获取所有城市。
import requests
import jsonpath
import json
import chardet
url = 'http://www.lagou.com/lbs/getAllCitySearchLabels.json'
header={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36"}
response = requests.get(url,header)
html = response.text
# 把json格式字符串转换成python对象
jsonobj = json.loads(html)
print(jsonobj)
# 从根节点开始,匹配name节点
citylist = jsonpath.jsonpath(jsonobj,'$..name')
print(citylist)
print(type(citylist))
fp = open('data/city.json','w')
content = json.dumps(citylist, ensure_ascii=False)
print(content)
fp.write(content)
fp.close()
2.6 糗事百科实例:
爬取糗事百科段子,假设页面的URL是 http://www.qiushibaike.com/8hr/page/1
要求:
- 使用requests获取页面信息,用XPath / re 做数据提取
- 获取每个帖子里的
用户头像链接、用户姓名、段子内容、点赞次数和评论次数 - 保存到 json 文件内
参考代码
__author__ = 'Administrator'
#爬取糗事百科段子
#目标网址:https://www.qiushibaike.com/
#第二页:https://www.qiushibaike.com/8hr/page/2/
#第三页:https://www.qiushibaike.com/8hr/page/3/
#第一步:通过构造url爬取前三页的页面
import requests
from lxml import etree
headers={'User-Agent':'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
#循环构造url
for i in range(1,4):
url='https://www.qiushibaike.com/8hr/page/'+str(i)+'/'
response=requests.get(url,headers=headers).text
# print(response)
html=etree.HTML(response)
#xpath解析出段子的链接
result1=html.xpath('//div[@class="recommend-article"]//li/a/@href')
print(result1)
#https://www.qiushibaike.com/article/121207893
#通过构造拼接具体段子的链接并爬取
for site in result1:
url2='https://www.qiushibaike.com'+site
response2=requests.get(url2,headers=headers).text
html2=etree.HTML(response2)
result2=html2.xpath('//div[@class="content"]')
print(result2[0].text)
演示效果
2.7 多线程糗事百科案例
案例要求参考上一个糗事百科单进程案例
Queue(队列对象)
Queue是python中的标准库,可以直接import Queue引用;队列是线程间最常用的交换数据的形式
python下多线程的思考
对于资源,加锁是个重要的环节。因为python原生的list,dict等,都是not thread safe的。而Queue,是线程安全的,因此在满足使用条件下,建议使用队列
- 初始化: class Queue.Queue(maxsize) FIFO 先进先出
- 包中的常用方法:
- Queue.qsize() 返回队列的大小
- Queue.empty() 如果队列为空,返回True,反之False
- Queue.full() 如果队列满了,返回True,反之False
- Queue.full 与 maxsize 大小对应
- Queue.get([block[, timeout]])获取队列,timeout等待时间
- 创建一个“队列”对象
- import Queue
- myqueue = Queue.Queue(maxsize = 10)
- 将一个值放入队列中
- myqueue.put(10)
- 将一个值从队列中取出
- myqueue.get()
多线程爬虫示意图
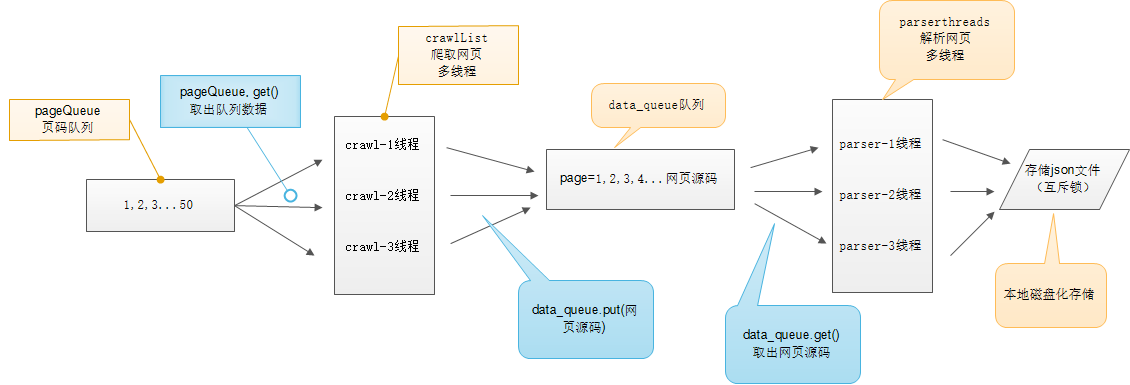
# !/usr/bin/python3
# -*- coding: utf-8 -*-
# 1. 导入线程池模块
# 线程池
import gevent.monkey
gevent.monkey.patch_all()
from gevent.pool import Pool
from queue import Queue
import requests
from lxml import etree
class QiushiSpider():
def __init__(self, max_page):
self.max_page = max_page
# 2. 创建线程池,初始化线程数量
self.pool = Pool(5)
self.base_url = "http://www.qiushibaike.com/8hr/page/{}/"
self.headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
}
# 专门存放 url 容器
self.url_queue = Queue()
pass
def get_url_list(self):
'''
获取 url 列表放入到 url 容器中
:return:
'''
for page in range(1, self.max_page, 1):
url = self.base_url.format(page)
self.url_queue.put(url)
# 3. 实现执行任务
def exec_task(self):
# 1> 获取url
url = self.url_queue.get()
# 2> 发送请求获取 html
response = requests.get(url, headers=self.headers)
html = response.text
# 3> 解析 html 提取数据
# 可以用来解析字符串格式的HTML文档对象,
# 将传进去的字符串转变成_Element对象。
# 作为_Element对象,可以方便的使用getparent()、remove()、xpath()
# 等方法。
# etree.HTML()
eroot = etree.HTML(html)
# xpath获取html源码中的内容
titles = eroot.xpath('//a[@class="recmd-content"]/text()')
for title in titles:
item = {}
item["title"] = title
# 4> 保存数据
print(item)
self.url_queue.task_done()
# 4. 实现执行任务完成后的操作,必须至少有一个参数
# result 任务执行的最终结果的返回值
def exec_task_finished(self, result):
print("result:", result)
print("执行任务完成")
self.pool.apply_async(self.exec_task, callback=self.exec_task_finished)
def run(self):
self.get_url_list()
# 5. 让任务使用线程池中的线程执行并且设置执行后的回调操作
# callback 表示执行完成后的回调
for i in range(5):
self.pool.apply_async(self.exec_task, callback=self.exec_task_finished)
self.url_queue.join()
pass
if __name__ == '__main__':
max_page = input("请输入您需要多少页内容:")
spider = QiushiSpider(int(max_page))
spider.run()

2.8 BeautifulSoup4
和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
Beautiful Soup 3 目前已经停止开发,推荐现在的项目使用Beautiful Soup 4。使用 pip 安装即可:
pip install beautifulsoup4
| 抓取工具 | 速度 | 使用难度 | 安装难度 |
|---|---|---|---|
| 正则 | 最快 | 困难 | 无(内置) |
| BeautifulSoup | 慢 | 最简单 | 简单 |
| lxml | 快 | 简单 | 一般 |
示例:
首先必须要导入 bs4 库
# beautifulsoup4_test.py
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#创建 Beautiful Soup 对象
soup = BeautifulSoup(html)
#打开本地 HTML 文件的方式来创建对象
#soup = BeautifulSoup(open('index.html'))
#格式化输出 soup 对象的内容
print soup.prettify()
运行结果:
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title" name="dromouse">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
<!-- Elsie -->
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>
- 如果我们在 IPython2 下执行,会看到这样一段警告:
- 意思是,如果我们没有显式地指定解析器,所以默认使用这个系统的最佳可用HTML解析器(“lxml”)。如果你在另一个系统中运行这段代码,或者在不同的虚拟环境中,使用不同的解析器造成行为不同。
- 但是我们可以通过
soup = BeautifulSoup(html,“lxml”)方式指定lxml解析器。
四大对象种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
- Tag
- NavigableString
- BeautifulSoup
- Comment
- Tag
Tag 通俗点讲就是 HTML 中的一个个标签,例如:
<head><title>The Dormouse's story</title></head>
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
上面的 title head a p等等 HTML 标签加上里面包括的内容就是 Tag,那么试着使用 Beautiful Soup 来获取 Tags:
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#创建 Beautiful Soup 对象
soup = BeautifulSoup(html)
print soup.title
# <title>The Dormouse's story</title>
print soup.head
# <head><title>The Dormouse's story</title></head>
print soup.a
# <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
print soup.p
# <p class="title" name="dromouse"><b>The Dormouse's story</b></p>
print type(soup.p)
# <class 'bs4.element.Tag'>
我们可以利用 soup 加标签名轻松地获取这些标签的内容,这些对象的类型是bs4.element.Tag。但是注意,它查找的是在所有内容中的第一个符合要求的标签。如果要查询所有的标签,后面会进行介绍。
对于 Tag,它有两个重要的属性,是 name 和 attrs
print soup.name
# [document] #soup 对象本身比较特殊,它的 name 即为 [document]
print soup.head.name
# head #对于其他内部标签,输出的值便为标签本身的名称
print soup.p.attrs
# {'class': ['title'], 'name': 'dromouse'}
# 在这里,我们把 p 标签的所有属性打印输出了出来,得到的类型是一个字典。
print soup.p['class'] # soup.p.get('class')
# ['title'] #还可以利用get方法,传入属性的名称,二者是等价的
soup.p['class'] = "newClass"
print soup.p # 可以对这些属性和内容等等进行修改
# <p class="newClass" name="dromouse"><b>The Dormouse's story</b></p>
del soup.p['class'] # 还可以对这个属性进行删除
print soup.p
# <p name="dromouse"><b>The Dormouse's story</b></p>
- NavigableString
既然我们已经得到了标签的内容,那么问题来了,我们要想获取标签内部的文字怎么办呢?很简单,用 .string 即可,例如
print soup.p.string
# The Dormouse's story
print type(soup.p.string)
# In [13]: <class 'bs4.element.NavigableString'>
- BeautifulSoup
BeautifulSoup 对象表示的是一个文档的内容。大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性来感受一下
print type(soup.name)
# <type 'unicode'>
print soup.name
# [document]
print soup.attrs # 文档本身的属性为空
# {}
- Comment
Comment 对象是一个特殊类型的 NavigableString 对象,其输出的内容不包括注释符号。
print soup.a
# <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
print soup.a.string
# Elsie
print type(soup.a.string)
# <class 'bs4.element.Comment'>
a 标签里的内容实际上是注释,但是如果我们利用 .string 来输出它的内容时,注释符号已经去掉了。
遍历文档树
1. 直接子节点 :.contents .children 属性
.content
tag 的 .content 属性可以将tag的子节点以列表的方式输出
print soup.head.contents
#[<title>The Dormouse's story</title>]
输出方式为列表,我们可以用列表索引来获取它的某一个元素
print soup.head.contents[0]
#<title>The Dormouse's story</title>
.children
它返回的不是一个 list,不过我们可以通过遍历获取所有子节点。
我们打印输出 .children 看一下,可以发现它是一个 list 生成器对象
print soup.head.children
#<listiterator object at 0x7f71457f5710>
for child in soup.body.children:
print child
结果:
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
2. 所有子孙节点: .descendants 属性
.contents 和 .children 属性仅包含tag的直接子节点,.descendants 属性可以对所有tag的子孙节点进行递归循环,和 children类似,我们也需要遍历获取其中的内容。
for child in soup.descendants:
print child
运行结果:
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
<head><title>The Dormouse's story</title></head>
<title>The Dormouse's story</title>
The Dormouse's story
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<b>The Dormouse's story</b>
The Dormouse's story
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
Elsie
,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
Lacie
and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
Tillie
;
and they lived at the bottom of a well.
<p class="story">...</p>
...
3. 节点内容: .string 属性
如果tag只有一个 NavigableString 类型子节点,那么这个tag可以使用 .string 得到子节点。如果一个tag仅有一个子节点,那么这个tag也可以使用 .string 方法,输出结果与当前唯一子节点的 .string 结果相同。
通俗点说就是:如果一个标签里面没有标签了,那么 .string 就会返回标签里面的内容。如果标签里面只有唯一的一个标签了,那么 .string 也会返回最里面的内容。例如:
print soup.head.string
#The Dormouse's story
print soup.title.string
#The Dormouse's story
搜索文档树
1. find_all()函数
find_all(name, attrs, recursive, text, **kwargs)
1)name 参数
name 参数可以查找所有名字为 name 的tag,字符串对象会被自动忽略掉
A.传字符串
最简单的过滤器是字符串.在搜索方法中传入一个字符串参数,Beautiful Soup会查找与字符串完整匹配的内容,下面的例子用于查找文档中所有的<b>标签:
soup.find_all('b')
# [<b>The Dormouse's story</b>]
print soup.find_all('a')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
B.传正则表达式
如果传入正则表达式作为参数,Beautiful Soup会通过正则表达式的 match() 来匹配内容.下面例子中找出所有以b开头的标签,这表示<body>和<b>标签都应该被找到
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
# body
# b
C.传列表
如果传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回.下面代码找到文档中所有<a>标签和<b>标签:
soup.find_all(["a", "b"])
# [<b>The Dormouse's story</b>,
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
2)keyword 参数
soup.find_all(id='link2')
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
3)text 参数
通过 text 参数可以搜搜文档中的字符串内容,与 name 参数的可选值一样, text 参数接受 字符串 , 正则表达式 , 列表
soup.find_all(text="Elsie")
# [u'Elsie']
soup.find_all(text=["Tillie", "Elsie", "Lacie"])
# [u'Elsie', u'Lacie', u'Tillie']
soup.find_all(text=re.compile("Dormouse"))
[u"The Dormouse's story", u"The Dormouse's story"]
2. CSS选择器
这就是另一种与 find_all 方法有异曲同工之妙的查找方法.
- 写 CSS 时,标签名不加任何修饰,类名前加
.,id名前加# - 在这里我们也可以利用类似的方法来筛选元素,用到的方法是
soup.select(),返回类型是list
(1)通过标签名查找
print soup.select('title')
#[<title>The Dormouse's story</title>]
print soup.select('a')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
print soup.select('b')
#[<b>The Dormouse's story</b>]
(2)通过类名查找
print soup.select('.sister')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
(3)通过 id 名查找
print soup.select('#link1')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
(4)组合查找
组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,二者需要用空格分开
print soup.select('p #link1')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
直接子标签查找,则使用 > 分隔
print soup.select("head > title")
#[<title>The Dormouse's story</title>]
(5)属性查找
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。
print soup.select('a[class="sister"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
print soup.select('a[href="http://example.com/elsie"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
同样,属性仍然可以与上述查找方式组合,不在同一节点的空格隔开,同一节点的不加空格
print soup.select('p a[href="http://example.com/elsie"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
(6) 获取内容
以上的 select 方法返回的结果都是列表形式,可以遍历形式输出,然后用 get_text() 方法来获取它的内容。
soup = BeautifulSoup(html, 'lxml')
print type(soup.select('title'))
print soup.select('title')[0].get_text()
for title in soup.select('title'):
print title.get_text()
2.9 案例:使用BeautifuSoup4的爬虫
我们以当当网的python书籍为爬取对象
使用BeautifuSoup4解析器,将网页上的书名,价格,描述存储出来。
import requests
from bs4 import BeautifulSoup
url='http://search.dangdang.com/?key=python&act=input'
header={'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; …) Gecko/20100101 Firefox/70.0'}
# print(soup)
# for t in range(1,10):
# totalurl = url + '&page_index=' + str(t)
r = requests.get(url, header)
r.encoding = r.apparent_encoding
html = r.text
soup = BeautifulSoup(html, 'lxml')
a = soup.find('ul', {'class': 'bigimg'}).find_all('li')
for li in a:
total = []
title = li.find('a', {'name': 'itemlist-title'}).get_text(strip=True)
now_sprice = li.find('span', class_="search_now_price").get_text(strip=True)
search_pre_price = li.find('span', class_="search_pre_price").get_text(strip=True)
detail = li.find('p', class_="detail").get_text(strip=True)
total.append([title, now_sprice, search_pre_price, detail])
with open(r'G:\pythonProject\pc\爬虫\data\当当book.txt', 'a', encoding='utf-8')as data:
for m in range(len(total)):
print(str(total[m]) + ';', file=data)
print(total)

第三章:动态HTML处理和机器图像识别
3.1 动态HTML介绍
JavaScript
JavaScript 是网络上最常用也是支持者最多的客户端脚本语言。它可以收集 用户的跟踪数据,不需要重载页面直接提交表单,在页面嵌入多媒体文件,甚至运行网页游戏。
我们可以在网页源代码的<scripy>标签里看到,比如:
<script type="text/javascript" src="https://statics.huxiu.com/w/mini/static_2015/js/sea.js?v=201601150944"></script>
jQuery
jQuery 是一个十分常见的库,70% 最流行的网站(约 200 万)和约 30% 的其他网站(约 2 亿)都在使用。一个网站使用 jQuery 的特征,就是源代码里包含了 jQuery 入口,比如:
<script type="text/javascript" src="https://statics.huxiu.com/w/mini/static_2015/js/jquery-1.11.1.min.js?v=201512181512"></script>
如果你在一个网站上看到了 jQuery,那么采集这个网站数据的时候要格外小心。jQuery 可 以动态地创建 HTML 内容,只有在 JavaScript 代码执行之后才会显示。如果你用传统的方法采集页面内容,就只能获得 JavaScript 代码执行之前页面上的内容。
Ajax
我们与网站服务器通信的唯一方式,就是发出 HTTP 请求获取新页面。如果提交表单之后,或从服务器获取信息之后,网站的页面不需要重新刷新,那么你访问的网站就在用Ajax 技术。
Ajax 其实并不是一门语言,而是用来完成网络任务(可以认为 它与网络数据采集差不多)的一系列技术。Ajax 全称是 Asynchronous JavaScript and XML(异步 JavaScript 和 XML),网站不需要使用单独的页面请求就可以和网络服务器进行交互 (收发信息)。
DHTML
Ajax 一样,动态 HTML(Dynamic HTML, DHTML)也是一系列用于解决网络问题的 技术集合。DHTML 是用客户端语言改变页面的 HTML 元素(HTML、CSS,或者二者皆 被改变)。比如页面上的按钮只有当用户移动鼠标之后才出现,背景色可能每次点击都会改变,或者用一个 Ajax 请求触发页面加载一段新内容,网页是否属于DHTML,关键要看有没有用 JavaScript 控制 HTML 和 CSS 元素。
那么,如何搞定?
那些使用了 Ajax 或 DHTML 技术改变 / 加载内容的页面,可能有一些采集手段。但是用 Python 解决这个问题只有两种途径:
- 直接从 JavaScript 代码里采集内容(费时费力)
- 用 Python 的 第三方库运行 JavaScript,直接采集你在浏览器里看到的页面(这个可以有)。
3.2 Selenium与Phantomjs
Selenium
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。
可以从 PyPI 网站下载 Selenium库https://pypi.python.org/simple/selenium ,也可以用 第三方管理器 pip用命令安装:
sudo pip install seleniumSelenium 官方参考文档:http://selenium-python.readthedocs.io/index.html
PhantomJS
PhantomJS 是一个基于Webkit的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的 JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器要高效。
如果我们把 Selenium 和 PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,这个爬虫可以处理 JavaScrip、Cookie、headers,以及任何我们真实用户需要做的事情。
PhantomJS 是一个功能完善(虽然无界面)的浏览器而非一个 Python 库,所以它不需要像 Python 的其他库一样安装,但我们可以通过Selenium调用PhantomJS来直接使用。
在Ubuntu16.04中可以使用命令安装:
sudo apt-get install phantomjs如果其他系统无法安装,可以从它的官方网站http://phantomjs.org/download.html) 下载。
PhantomJS 官方参考文档:http://phantomjs.org/documentation
快速入门
Selenium 库里有个叫 WebDriver 的 API。WebDriver 有点儿像可以加载网站的浏览器,但是它也可以像 BeautifulSoup 或者其他 Selector 对象一样用来查找页面元素,与页面上的元素进行交互 (发送文本、点击等),以及执行其他动作来运行网络爬虫。
# 导入 webdriver
from selenium import webdriver
# 调用键盘按键操作时需要引入的Keys包
from selenium.webdriver.common.keys import Keys
# 调用环境变量指定的PhantomJS浏览器创建浏览器对象
driver = webdriver.PhantomJS(executable_path=r'G:\phantomjs-2.1.1-windows\phantomjs-2.1.1-windows\bin\phantomjs.exe',service_args=['--ignore-ssl-errors=true','--ssl-protocol=TLSv1'])
# 如果没有在环境变量指定PhantomJS位置
# driver = webdriver.PhantomJS(executable_path="./phantomjs"))
# get方法会一直等到页面被完全加载,然后才会继续程序,通常测试会在这里选择 time.sleep(2)
driver.get("http://www.baidu.com/")
# 获取页面名为 wrapper的id标签的文本内容
data = driver.find_element_by_id("wrapper").text
# 打印数据内容
print(data)
# 打印页面标题 "百度一下,你就知道"
print(driver.title)
# 生成当前页面快照并保存
driver.save_screenshot("baidu.png")
# id="kw"是百度搜索输入框,输入字符串"长城"
driver.find_element_by_id("kw").send_keys("长城")
# id="su"是百度搜索按钮,click() 是模拟点击
driver.find_element_by_id("su").click()
# 获取新的页面快照
driver.save_screenshot("长城.png")
# 打印网页渲染后的源代码
print(driver.page_source)
# 获取当前页面Cookie
print(driver.get_cookies())
# ctrl+a 全选输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'a')
# ctrl+x 剪切输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'x')
# 输入框重新输入内容
driver.find_element_by_id("kw").send_keys("itcast")
# 模拟Enter回车键
driver.find_element_by_id("su").send_keys(Keys.RETURN)
# 清除输入框内容
driver.find_element_by_id("kw").clear()
# 生成新的页面快照
driver.save_screenshot("itcast.png")
# 获取当前url
print(driver.current_url)
# 关闭当前页面,如果只有一个页面,会关闭浏览器
# driver.close()
# 关闭浏览器
driver.quit()
baidu.png
长城.png
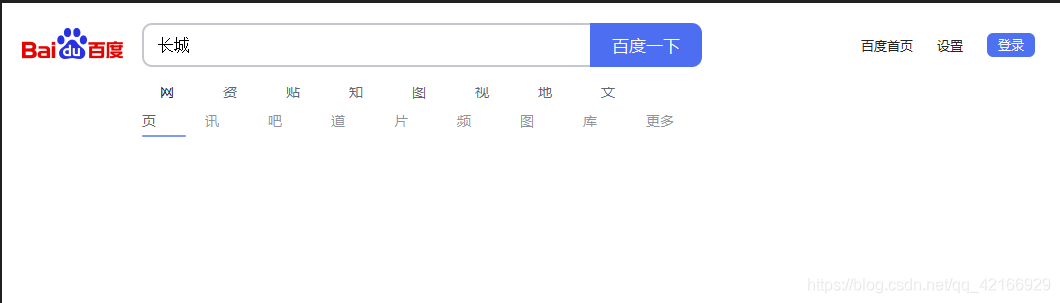
itcast.png
页面操作
Selenium 的 WebDriver提供了各种方法来寻找元素,假设下面有一个表单输入框:
<input type="text" name="user-name" id="passwd-id" />
那么:
# 获取id标签值
element = driver.find_element_by_id("passwd-id")
# 获取name标签值
element = driver.find_element_by_name("user-name")
# 获取标签名值
element = driver.find_elements_by_tag_name("input")
# 也可以通过XPath来匹配
element = driver.find_element_by_xpath("//input[@id='passwd-id']")
定位UI元素 (WebElements)
关于元素的选取,有如下的API 单个元素选取
find_element_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
-
By ID
<div id="coolestWidgetEvah">...</div>-
实现
element = driver.find_element_by_id("coolestWidgetEvah") ------------------------ or ------------------------- from selenium.webdriver.common.by import By element = driver.find_element(by=By.ID, value="coolestWidgetEvah")
-
-
By Class Name
<div class="cheese"><span>Cheddar</span></div><div class="cheese"><span>Gouda</span></div>-
实现
cheeses = driver.find_elements_by_class_name("cheese") ------------------------ or ------------------------- from selenium.webdriver.common.by import By cheeses = driver.find_elements(By.CLASS_NAME, "cheese")
-
-
By Tag Name
<iframe src="..."></iframe>-
实现
frame = driver.find_element_by_tag_name("iframe") ------------------------ or ------------------------- from selenium.webdriver.common.by import By frame = driver.find_element(By.TAG_NAME, "iframe")
-
-
By Name
<input name="cheese" type="text"/>-
实现
cheese = driver.find_element_by_name("cheese") ------------------------ or ------------------------- from selenium.webdriver.common.by import By cheese = driver.find_element(By.NAME, "cheese")
-
-
By Link Text
<a href="http://www.google.com/search?q=cheese">cheese</a>-
实现
cheese = driver.find_element_by_link_text("cheese") ------------------------ or ------------------------- from selenium.webdriver.common.by import By cheese = driver.find_element(By.LINK_TEXT, "cheese")
-
-
By Partial Link Text
<a href="http://www.google.com/search?q=cheese">search for cheese</a>>-
实现
cheese = driver.find_element_by_partial_link_text("cheese") ------------------------ or ------------------------- from selenium.webdriver.common.by import By cheese = driver.find_element(By.PARTIAL_LINK_TEXT, "cheese")
-
-
By CSS
<div id="food"><span class="dairy">milk</span><span class="dairy aged">cheese</span></div>-
实现
cheese = driver.find_element_by_css_selector("#food span.dairy.aged") ------------------------ or ------------------------- from selenium.webdriver.common.by import By cheese = driver.find_element(By.CSS_SELECTOR, "#food span.dairy.aged")
-
-
By XPath
<input type="text" name="example" /> <INPUT type="text" name="other" />-
实现
inputs = driver.find_elements_by_xpath("//input") ------------------------ or ------------------------- from selenium.webdriver.common.by import By inputs = driver.find_elements(By.XPATH, "//input")
-
鼠标动作链
有些时候,我们需要再页面上模拟一些鼠标操作,比如双击、右击、拖拽甚至按住不动等,我们可以通过导入 ActionChains 类来做到:
示例:
#导入 ActionChains 类
from selenium.webdriver import ActionChains
# 鼠标移动到 ac 位置
ac = driver.find_element_by_xpath('element')
ActionChains(driver).move_to_element(ac).perform()
# 在 ac 位置单击
ac = driver.find_element_by_xpath("elementA")
ActionChains(driver).move_to_element(ac).click(ac).perform()
# 在 ac 位置双击
ac = driver.find_element_by_xpath("elementB")
ActionChains(driver).move_to_element(ac).double_click(ac).perform()
# 在 ac 位置右击
ac = driver.find_element_by_xpath("elementC")
ActionChains(driver).move_to_element(ac).context_click(ac).perform()
# 在 ac 位置左键单击hold住
ac = driver.find_element_by_xpath('elementF')
ActionChains(driver).move_to_element(ac).click_and_hold(ac).perform()
# 将 ac1 拖拽到 ac2 位置
ac1 = driver.find_element_by_xpath('elementD')
ac2 = driver.find_element_by_xpath('elementE')
ActionChains(driver).drag_and_drop(ac1, ac2).perform()
填充表单
我们已经知道了怎样向文本框中输入文字,但是有时候我们会碰到<select> </select>标签的下拉框。直接点击下拉框中的选项不一定可行。
<select id="status" class="form-control valid" onchange="" name="status">
<option value=""></option>
<option value="0">未审核</option>
<option value="1">初审通过</option>
<option value="2">复审通过</option>
<option value="3">审核不通过</option>
</select>
Selenium专门提供了Select类来处理下拉框。 其实 WebDriver 中提供了一个叫 Select 的方法,可以帮助我们完成这些事情:
# 导入 Select 类
from selenium.webdriver.support.ui import Select
# 找到 name 的选项卡
select = Select(driver.find_element_by_name('status'))
#
select.select_by_index(1)
select.select_by_value("0")
select.select_by_visible_text(u"未审核")
以上是三种选择下拉框的方式,它可以根据索引来选择,可以根据值来选择,可以根据文字来选择。注意:
- index 索引从 0 开始
- value是option标签的一个属性值,并不是显示在下拉框中的值
- visible_text是在option标签文本的值,是显示在下拉框的值
全部取消选择怎么办呢?很简单:
select.deselect_all()
弹窗处理
当你触发了某个事件之后,页面出现了弹窗提示,处理这个提示或者获取提示信息方法如下:
alert = driver.switch_to_alert()
页面切换
一个浏览器肯定会有很多窗口,所以我们肯定要有方法来实现窗口的切换。切换窗口的方法如下:
driver.switch_to.window("this is window name")
也可以使用 window_handles 方法来获取每个窗口的操作对象。例如:
for handle in driver.window_handles:
driver.switch_to_window(handle)
页面前进和后退
操作页面的前进和后退功能:
driver.forward() #前进
driver.back() # 后退
Cookies
获取页面每个Cookies值,用法如下
for cookie in driver.get_cookies():
print "%s -> %s" % (cookie['name'], cookie['value'])
删除Cookies,用法如下
# By name
driver.delete_cookie("CookieName")
# all
driver.delete_all_cookies()
页面等待
注意:这是非常重要的一部分!!
现在的网页越来越多采用了 Ajax 技术,这样程序便不能确定何时某个元素完全加载出来了。如果实际页面等待时间过长导致某个dom元素还没出来,但是你的代码直接使用了这个WebElement,那么就会抛出NullPointer的异常。
为了避免这种元素定位困难而且会提高产生 ElementNotVisibleException 的概率。所以 Selenium 提供了两种等待方式,一种是隐式等待,一种是显式等待。
隐式等待是等待特定的时间,显式等待是指定某一条件直到这个条件成立时继续执行。
显式等待
显式等待指定某个条件,然后设置最长等待时间。如果在这个时间还没有找到元素,那么便会抛出异常了。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("http://www.xxxxx.com/loading")
try:
# 页面一直循环,直到 id="myDynamicElement" 出现
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写参数,程序默认会 0.5s 调用一次来查看元素是否已经生成,如果本来元素就是存在的,那么会立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不用自己写某些等待条件了。
title_is
title_contains
presence_of_element_located
visibility_of_element_located
visibility_of
presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – it is Displayed and Enabled.
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隐式等待
隐式等待比较简单,就是简单地设置一个等待时间,单位为秒。
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然如果不设置,默认等待时间为0。
3.3 selenium+phantomjs案例
案例一:模拟豆瓣网站登录
from selenium import webdriver
import time
from lxml import etree
# 动态页面获取之二
driver = webdriver.PhantomJS()
driver.get("https://www.douban.com/")
# 获取源码
html = driver.page_source
root = etree.HTML(html)
iframes = root.xpath('//*[@id="anony-reg-new"]/div/div[1]/iframe/@src')[0]
# 因为登录是iframe引入的 所以重新再开一个
driver.get("https:" + iframes)
# 模拟点击 切换到密码登录
driver.save_screenshot('douban1.png')
driver.find_element_by_class_name("account-tab-account").click()
time.sleep(1)
# 输入账号和密码
driver.find_element_by_id("username").send_keys("18317696865")
driver.find_element_by_id("password").send_keys("overdose1")
# 点击登录
driver.find_element_by_class_name("btn-account").click()
time.sleep(4)
# 快照保存
driver.save_screenshot('douban_denglu.png')
# 退出
driver.quit()
由于豆瓣网的登录页面引入了其他的连接,因此不能直接通过driver.find_element_by_class_name(“account-tab-account”),这样是找不到元素的
所以通过提取登陆页面的src的xpath,是一个连接,然后重新在提取就可以了,查看运行结果
douban1.png
douban_denglu.png
案例二:动态页面模拟点击
爬取斗鱼直播平台的所有房间信息:
from selenium import webdriver
from bs4 import BeautifulSoup
import time
if __name__ == '__main__':
driver = webdriver.PhantomJS()
driver.get("https://www.douyu.com/directory/all")
count = 0 # 总页数
total = 0 # 房间数
time.sleep(5)
while True:
# 判断是否到达尾页,如果是true,则推出循环
attr = driver.find_element_by_css_selector(".dy-Pagination-next").get_attribute("aria-disabled")
if "true" in attr:
break
try:
page_count = 0 # 记录每页多少条数据
# 解析html
soup = BeautifulSoup(driver.page_source, "lxml")
names = soup.find_all("h2", attrs={"class": "DyListCover-user"})
looks = soup.find_all("span", attrs={"class": "DyListCover-hot"})
for name, look in zip(names, looks):
print("房间:" + name.get_text() + "\t人数:" + look.get_text())
total += 1
page_count += 1
count += 1
print("==================第%s页,每页%s条数据==================" % (str(count), str(page_count)))
# 保存每一页的图片
driver.save_screenshot("douyu_%s.png" % str(count))
# 点击下一页
driver.find_element_by_xpath('//*[@id="listAll"]/section[2]/div[2]/div/ul/li[9]/span').click()
# 等待数据加载完毕
time.sleep(3)
except RuntimeError as e:
print(e)
print("总页数:" + str(count))
print("总房间数:" + str(total))
查看结果
运行结果
3.4 机器视觉
从 Google 的无人驾驶汽车到可以识别假钞的自动售卖机,机器视觉一直都是一个应用广 泛且具有深远的影响和雄伟的愿景的领域。
我们将重点介绍机器视觉的一个分支:文字识别,介绍如何用一些 Python库来识别和使用在线图片中的文字。
我们可以很轻松的阅读图片里的文字,但是机器阅读这些图片就会非常困难,利用这种人类用户可以正常读取但是大多数机器人都没法读取的图片,验证码 (CAPTCHA)就出现了。验证码读取的难易程度也大不相同,有些验证码比其他的更加难读。
将图像翻译成文字一般被称为光学文字识别(Optical Character Recognition, OCR)。可以实现OCR的底层库并不多,目前很多库都是使用共同的几个底层 OCR 库,或者是在上面 进行定制。
ORC库概述
在读取和处理图像、图像相关的机器学习以及创建图像等任务中,Python 一直都是非常出色的语言。虽然有很多库可以进行图像处理,但在这里我们只重点介绍:Tesseract
Tesseract
Tesseract 是一个 OCR 库,目前由 Google 赞助(Google 也是一家以 OCR 和机器学习技术闻名于世的公司)。Tesseract 是目前公认最优秀、最精确的开源 OCR 系统,除了极高的精确度,Tesseract 也具有很高的灵活性。它可以通过训练识别出任何字体,也可以识别出任何 Unicode 字符。
安装Tesseract
Windows 系统
下载可执行安装文件https://code.google.com/p/tesseract-ocr/downloads/list安装。
Linux 系统
可以通过 apt-get 安装: $sudo apt-get tesseract-ocr
Mac OS X系统
用 Homebrew(http://brew.sh/)等第三方库可以很方便地安装 brew install tesseract
安装pytesseract
Tesseract 是一个 Python 的命令行工具,不是通过 import 语句导入的库。安装之后,要用 tesseract 命令在 Python 的外面运行,但我们可以通过 pip 安装支持Python 版本的 Tesseract库:
pip install pytesseract
3.5 处理给规范的文字
处理的大多数文字最好都是比较干净、格式规范的。格式规范的文字通常可以满足一些需求,通常格式规范的文字具有以下特点:
- 使用一个标准字体(不包含手写体、草书,或者十分“花哨的”字体)
- 即使被复印或拍照,字体还是很清晰,没有多余的痕迹或污点
- 排列整齐,没有歪歪斜斜的字
- 没有超出图片范围,也没有残缺不全,或紧紧贴在图片的边缘
文字的一些格式问题在图片预处理时可以进行解决。例如,可以把图片转换成灰度图,调整亮度和对比度,还可以根据需要进行裁剪和旋转(详情需要了解图像与信号处理)等。
格式规范文字的理想示例

通过下面的命令运行 Tesseract,读取文件并把结果写到一个文本文件中: tesseract test.jpg text
cat text.txt 即可显示结果。
识别结果很准确,不过符号^和*分别被表示成了双引号和单引号。大体上可以让你很舒服地阅读。
通过Python代码实现
import pytesseract
from PIL import Image
image = Image.open('test.jpg')
text = pytesseract.image_to_string(image)
print(text)
运行结果:
This is some text, written in Arial, that will be read by
Tesseract. Here are some symbols: !@#$%"&*()
对图片进行阈值过滤和降噪处理(了解即可)
很多时候我们在网上会看到这样的图片:

Tesseract 不能完整处理这个图片,主要是因为图片背景色是渐变的,最终结果是这样:
随着背景色从左到右不断加深,文字变得越来越难以识别,Tesseract 识别出的 每一行的最后几个字符都是错的。
遇到这类问题,可以先用 Python 脚本对图片进行清理。利用 PIL 库,我们可以创建一个阈值过滤器来去掉渐变的背景色,只把文字留下来,从而让图片更加清晰,便于 Tesseract 读取:
from PIL import Image
import subprocess
def cleanFile(filePath, newFilePath):
image = Image.open(filePath)
# 对图片进行阈值过滤(低于143的置为黑色,否则为白色)
image = image.point(lambda x: 0 if x < 143 else 255)
# 重新保存图片
image.save(newFilePath)
# 调用系统的tesseract命令对图片进行OCR识别
subprocess.call(["tesseract", newFilePath, "output"])
# 打开文件读取结果
with open("output.txt", 'r') as f:
print(f.read())
if __name__ == "__main__":
cleanFile("text2.png", "text2clean.png")
通过一个阈值对前面的“模糊”图片进行过滤的结果

除了一些标点符号不太清晰或丢失了,大部分文字都被读出来了。Tesseract 给出了最好的 结果:
从网站图片中抓取文字
用 Tesseract 读取硬盘里图片上的文字,可能不怎么令人兴奋,但当我们把它和网络爬虫组合使用时,就能成为一个强大的工具。
网站上的图片可能并不是故意把文字做得很花哨 (就像餐馆菜单的 JPG 图片上的艺术字),但它们上面的文字对网络爬虫来说就是隐藏起来 了,举个例子:
- 虽然亚马逊的 robots.txt 文件允许抓取网站的产品页面,但是图书的预览页通常不让网络机 器人采集。
- 图书的预览页是通过用户触发 Ajax 脚本进行加载的,预览图片隐藏在 div 节点 下面;其实,普通的访问者会觉得它们看起来更像是一个 Flash 动画,而不是一个图片文 件。当然,即使我们能获得图片,要把它们读成文字也没那么简单。
- 下面的程序就解决了这个问题:首先导航到托尔斯泰的《战争与和平》的大字号印刷版 1, 打开阅读器,收集图片的 URL 链接,然后下载图片,识别图片,最后打印每个图片的文 字。因为这个程序很复杂,利用了前面几章的多个程序片段,所以我增加了一些注释以让 每段代码的目的更加清晰:
import time
from urllib.request import urlretrieve
import subprocess
from selenium import webdriver
#创建新的Selenium driver
driver = webdriver.PhantomJS()
# 用Selenium试试Firefox浏览器:
# driver = webdriver.Firefox()
driver.get("http://www.amazon.com/War-Peace-Leo-Nikolayevich-Tolstoy/dp/1427030200")
# 单击图书预览按钮 driver.find_element_by_id("sitbLogoImg").click() imageList = set()
# 等待页面加载完成
time.sleep(5)
imageList=set()
# 当向右箭头可以点击时,开始翻页
while "pointer" in driver.find_element_by_id("sitbReaderRightPageTurner").get_attribute("style"):
driver.find_element_by_id("sitbReaderRightPageTurner").click()
time.sleep(2)
# 获取已加载的新页面(一次可以加载多个页面,但是重复的页面不能加载到集合中)
pages = driver.find_elements_by_xpath("//div[@class='pageImage']/div/img")
for page in pages:
image = page.get_attribute("src")
imageList.add(image)
driver.quit()
# 用Tesseract处理我们收集的图片URL链接
for image in sorted(imageList):
# 保存图片
urlretrieve(image, "page.jpg")
p = subprocess.Popen(["tesseract", "page.jpg", "page"], stdout=subprocess.PIPE,stderr=subprocess.PIPE)
f = open("page.txt", "r")
p.wait() print(f.read())
和我们前面使用 Tesseract 读取的效果一样,这个程序也会完美地打印书中很多长长的段落,第六页的预览如下所示:
6
"A word of friendly advice, mon
cher. Be off as soon as you can,
that's all I have to tell you. Happy
he who has ears to hear. Good-by,
my dear fellow. Oh, by the by!" he
shouted through the doorway after
Pierre, "is it true that the countess
has fallen into the clutches of the
holy fathers of the Society of je-
sus?"
Pierre did not answer and left Ros-
topchin's room more sullen and an-
gry than he had ever before shown
himself.
但是当文字出现在彩色封面上时,结果就不那么完美了:
WEI' nrrd Peace
Len Nlkelayevldu Iolfluy
Readmg shmdd be ax
wlnvame asnossxble Wenfler
an mm m our cram: Llhvary
- Leo Tmsloy was a Russian rwovelwst
I and moval phflmopher med lur
A ms Ideas 01 nonviolenx reswslance m 5 We range 0, "and"
如果想把文字加工成普通人可以看懂的效果,还需要花很多时间去处理。
比如,通过给 Tesseract 提供大量已知的文字与图片映射集,经过训练 Tesseract 就可以“学会”识别同一种字体,而且可以达到极高的精确率和准确率,甚至可以忽略图片中文字的背景色和相对位置等问题。
3.6 尝试对知乎网验证码进行机器识别处理:
许多流行的内容管理系统即使加了验证码模块,其众所周知的注册页面也经常会遭到网络 机器人的垃圾注册。
那么,这些网络机器人究,竟是怎么做的呢?既然我们已经,可以成功地识别出保存在电脑上 的验证码了,那么如何才能实现一个全能的网络机器人呢?
大多数网站生成的验证码图片都具有以下属性。
- 它们是服务器端的程序动态生成的图片。验证码图片的 src 属性可能和普通图片不太一 样,比如
<img src="WebForm.aspx?id=8AP85CQKE9TJ">,但是可以和其他图片一样进行 下载和处理。 - 图片的答案存储在服务器端的数据库里。
- 很多验证码都有时间限制,如果你太长时间没解决就会失效。
- 常用的处理方法就是,首先把验证码图片下载到硬盘里,清理干净,然后用 Tesseract 处理 图片,最后返回符合网站要求的识别结果。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import time
import pytesseract
from PIL import Image
from bs4 import BeautifulSoup
def captcha(data):
with open('captcha.jpg','wb') as fp:
fp.write(data)
time.sleep(1)
image = Image.open("captcha.jpg")
text = pytesseract.image_to_string(image)
print "机器识别后的验证码为:" + text
command = raw_input("请输入Y表示同意使用,按其他键自行重新输入:")
if (command == "Y" or command == "y"):
return text
else:
return raw_input('输入验证码:')
def zhihuLogin(username,password):
# 构建一个保存Cookie值的session对象
sessiona = requests.Session()
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0'}
# 先获取页面信息,找到需要POST的数据(并且已记录当前页面的Cookie)
html = sessiona.get('https://www.zhihu.com/#signin', headers=headers).content
# 找到 name 属性值为 _xsrf 的input标签,取出value里的值
_xsrf = BeautifulSoup(html ,'lxml').find('input', attrs={'name':'_xsrf'}).get('value')
# 取出验证码,r后面的值是Unix时间戳,time.time()
captcha_url = 'https://www.zhihu.com/captcha.gif?r=%d&type=login' % (time.time() * 1000)
response = sessiona.get(captcha_url, headers = headers)
data = {
"_xsrf":_xsrf,
"email":username,
"password":password,
"remember_me":True,
"captcha": captcha(response.content)
}
response = sessiona.post('https://www.zhihu.com/login/email', data = data, headers=headers)
print response.text
response = sessiona.get('https://www.zhihu.com/people/maozhaojun/activities', headers=headers)
print response.text
if __name__ == "__main__":
zhihuLogin('xxxx@qq.com','ALAxxxxIME')
尝试处理中文字符
如果手头上有中文的训练数据,也可以尝试对中文进行识别。
命令:tesseract --list-langs可以查看当前支持的语言,chi_sim表示支持简体中文。
那么在使用时候,可以指定某个语言来进行识别,如:
tesseract -l chi_sim paixu.png paixu
表现在程序里,则可以这么写:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from PIL import Image
import subprocess
def cleanFile(filePath)
image = Image.open(filePath)
# 调用系统的tesseract命令, 对图片进行OCR中文识别
subprocess.call(["tesseract", "-l", "chi_sim", filePath, "paixu"])
# 打开文件读取结果
with open("paixu.txt", 'r') as f:
print(f.read())
if __name__ == "__main__":
cleanFile("paixu.png")
结果如下:
第四章:Scrapy框架推荐阅读:
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
- Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构图(绿线是数据流向):
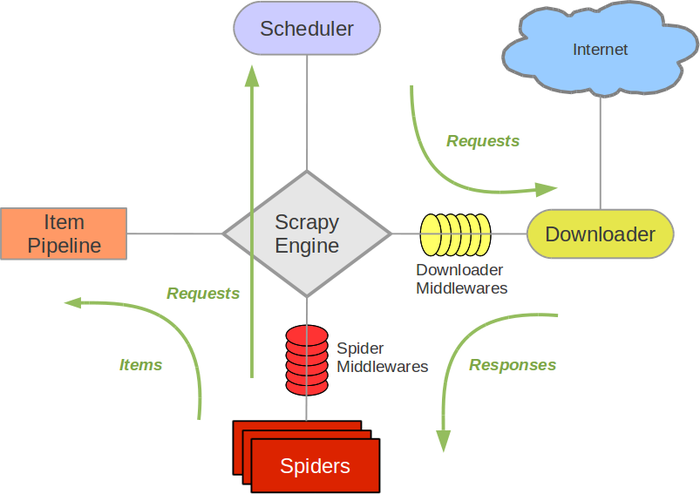
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy的运作流程
代码写好,程序开始运行…
引擎:Hi!Spider, 你要处理哪一个网站?Spider:老大要我处理xxxx.com。引擎:你把第一个需要处理的URL给我吧。Spider:给你,第一个URL是xxxxxxx.com。引擎:Hi!调度器,我这有request请求你帮我排序入队一下。调度器:好的,正在处理你等一下。引擎:Hi!调度器,把你处理好的request请求给我。调度器:给你,这是我处理好的request引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。引擎:Hi !管道我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。管道``调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
4.1 Scrapy的安装介绍
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
Windows 安装方式
- Python 2 / 3
- 升级pip版本:
pip install --upgrade pip - 通过pip 安装 Scrapy 框架
pip install Scrapy
Ubuntu 需要9.10或以上版本安装方式
- Python 2 / 3
- 安装非Python的依赖
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev - 通过pip 安装 Scrapy 框架
sudo pip install scrapy
安装后,只要在命令终端输入 scrapy,提示类似以下结果,代表已经安装成功
具体Scrapy安装流程参考:http://doc.scrapy.org/en/latest/intro/install.html#intro-install-platform-notes 里面有各个平台的安装方法
4.2 入门案例
学习目标
- 创建一个Scrapy项目
- 定义提取的结构化数据(Item)
- 编写爬取网站的 Spider 并提取出结构化数据(Item)
- 编写 Item Pipelines 来存储提取到的Item(即结构化数据)
一. 新建项目(scrapy startproject)
- 在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject mySpider
- 其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录结构大致如下:
下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的Python模块,将会从这里引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录
二、明确目标(mySpider/items.py)
我们打算抓取:http://www.itcast.cn/channel/teacher.shtml 网站里的所有讲师的姓名、职称和个人信息。
- 打开mySpider目录下的items.py
- Item 定义结构化数据字段,用来保存爬取到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误。
- 可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item。
- 接下来,创建一个ItcastItem 类,和构建item模型(model)。
import scrapy
class ItcastItem(scrapy.Item):
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
三、制作爬虫 (spiders/itcastSpider.py)
爬虫功能要分两步:
- 爬数据
- 在当前目录下输入命令,将在
mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
- 打开 mySpider/spider目录里的 itcast.py,默认增加了下列代码:
import scrapy
class ItcastSpider(scrapy.Spider):
name = "itcast"
allowed_domains = ["itcast.cn"]
start_urls = (
'http://www.itcast.cn/',
)
def parse(self, response):
pass
其实也可以由我们自行创建itcast.py并编写上面的代码,只不过使用命令可以免去编写固定代码的麻烦
要建立一个Spider, 你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性 和 一个方法。
name = "":这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。allow_domains = []是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。start_urls = ():爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。parse(self, response):解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:- 负责解析返回的网页数据(response.body),提取结构化数据(生成item)
- 生成需要下一页的URL请求。
将start_urls的值修改为需要爬取的第一个url
start_urls = ("http://www.itcast.cn/channel/teacher.shtml",)
修改parse()方法
def parse(self, response):
with open("teacher.html", "w") as f:
f.write(response.text)
然后运行一下看看,在mySpider目录下执行:
scrapy crawl itcast
是的,就是 itcast,看上面代码,它是 ItcastSpider 类的 name 属性,也就是使用 scrapy genspider命令的爬虫名。
一个Scrapy爬虫项目里,可以存在多个爬虫。各个爬虫在执行时,就是按照 name 属性来区分。
运行之后,如果打印的日志出现 [scrapy] INFO: Spider closed (finished),代表执行完成。 之后当前文件夹中就出现了一个 teacher.html 文件,里面就是我们刚刚要爬取的网页的全部源代码信息。
- 取数据
- 爬取整个网页完毕,接下来的就是的取过程了,首先观察页面源码:
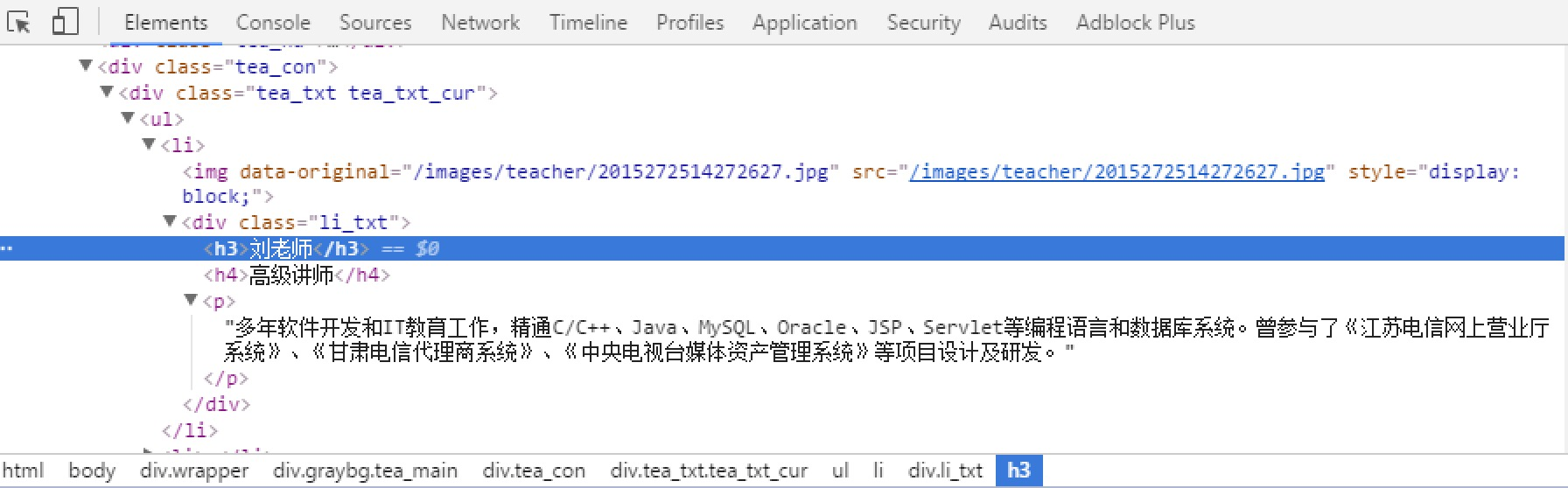
<div class="li_txt">
<h3> xxx </h3>
<h4> xxxxx </h4>
<p> xxxxxxxx </p>
是不是一目了然?直接上XPath开始提取数据吧。
- 我们之前在mySpider/items.py 里定义了一个ItcastItem类。 这里引入进来
from mySpider.items import ItcastItem
- 然后将我们得到的数据封装到一个
ItcastItem对象中,可以保存每个老师的属性:
from mySpider.items import ItcastItem
def parse(self, response):
#open("teacher.html","wb").write(response.body).close()
# 存放老师信息的集合
items = []
for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = ItcastItem()
#extract()方法返回的都是字符串
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
#xpath返回的是包含一个元素的列表
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
# 直接返回最后数据
return items
- 我们暂时先不处理管道,后面会详细介绍。
3.保存数据
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,,命令如下:
# json格式,默认为Unicode编码
scrapy crawl itcast -o teachers.json
# json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
# csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
# xml格式
scrapy crawl itcast -o teachers.xml
在命令行中输入我们想要保存的数据格式,这里比如说csv

运行完之后查看我们的teachers.csv
4.3 Scrapy Shell
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据。
如果安装了 IPython ,Scrapy终端将使用 IPython (替代标准Python终端)。 IPython 终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。(推荐安装IPython)
启动Scrapy Shell
进入项目的根目录,执行下列命令来启动shell:
scrapy shell "http://www.itcast.cn/channel/teacher.shtml"
Scrapy Shell根据下载的页面会自动创建一些方便使用的对象,例如 Response 对象,以及 Selector 对象 (对HTML及XML内容)。
- 当shell载入后,将得到一个包含response数据的本地 response 变量,输入
response.body将输出response的包体,输出response.headers可以看到response的包头。 - 输入
response.selector时, 将获取到一个response 初始化的类 Selector 的对象,此时可以通过使用response.selector.xpath()或response.selector.css()来对 response 进行查询。 - Scrapy也提供了一些快捷方式, 例如
response.xpath()或response.css()同样可以生效(如之前的案例)。
Selectors选择器
Scrapy Selectors 内置 XPath 和 CSS Selector 表达式机制
Selector有四个基本的方法,最常用的还是xpath:
- xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表
- extract(): 序列化该节点为字符串并返回list
- css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表,语法同 BeautifulSoup4
- re(): 根据传入的正则表达式对数据进行提取,返回字符串list列表
XPath表达式的例子及对应的含义:
/html/head/title: 选择<HTML>文档中 <head> 标签内的 <title> 元素
/html/head/title/text(): 选择上面提到的 <title> 元素的文字
//td: 选择所有的 <td> 元素
//div[@class="mine"]: 选择所有具有 class="mine" 属性的 div 元素
尝试Selector
我们用腾讯社招的网站http://hr.tencent.com/position.php?&start=0#a举例:
# 启动
scrapy shell "http://hr.tencent.com/position.php?&start=0#a"
# 返回 xpath选择器对象列表
response.xpath('//title')
[<Selector xpath='//title' data='<title>职位搜索 | 社会招聘 | Tencent 腾讯招聘</title'>]
# 使用 extract()方法返回字符串列表
response.xpath('//title').extract()
['<title>职位搜索 | 社会招聘 | Tencent 腾讯招聘</title>']
# 打印列表第一个元素,没有则返回None
print response.xpath('//title').extract_first()
<title>职位搜索 | 社会招聘 | Tencent 腾讯招聘</title>
#contains的用法,or的用法,last()的含义
In [6]: response.xpath('//*[contains(@class,"odd") or contains(@class,"even")]/td[last()]/text()').extract()
Out[6]:
['2017-06-02',
'2017-06-02',
'2017-06-02',
'2017-06-02',
'2017-06-02',
'2017-06-02',
'2017-06-02',
'2017-06-02',
'2017-06-02',
'2017-06-02']
In [4]: response.xpath('//a[contains(@href,"position_detail.php?")]/text()').extract()
Out[4]:
['19407-移动游戏平台合作(上海)',
'19407-手游商业化与本地化策划(上海)',
'OMG236-腾讯视频平台高级产品经理(深圳)',
'OMG096-科技频道记者(北京)',
'18402-项目管理',
'IEG-招聘经理(深圳)',
'OMG097-视觉设计师(北京)',
'OMG097-策略产品经理/产品运营(北京)',
'OMG097-策略产品经理/产品运营(北京)',
'OMG097-数据产品经理(北京)']
In [5]: response.xpath('//*[contains(@class,"odd") or contains(@class,"even")]/td[last()-1]/text()').extract()
Out[5]: ['上海', '上海', '深圳', '北京', '深圳', '深圳', '北京', '北京', '北京', '北京']
以后做数据提取的时候,可以把现在Scrapy Shell中测试,测试通过后再应用到代码中。
当然Scrapy Shell作用不仅仅如此,但是不属于我们课程重点,不做详细介绍。
官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/shell.html
4.4 Item Pipeline
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item。
每个Item Pipeline都是实现了简单方法的Python类,比如决定此Item是丢弃而存储。以下是item pipeline的一些典型应用:
- 验证爬取的数据(检查item包含某些字段,比如说name字段)
- 查重(并丢弃)
- 将爬取结果保存到文件或者数据库中
编写item pipeline
编写item pipeline很简单,item pipiline组件是一个独立的Python类,其中process_item()方法必须实现:
import something
class SomethingPipeline(object):
def __init__(self):
# 可选实现,做参数初始化等
# doing something
def process_item(self, item, spider):
# item (Item 对象) – 被爬取的item
# spider (Spider 对象) – 爬取该item的spider
# 这个方法必须实现,每个item pipeline组件都需要调用该方法,
# 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
return item
def open_spider(self, spider):
# spider (Spider 对象) – 被开启的spider
# 可选实现,当spider被开启时,这个方法被调用。
def close_spider(self, spider):
# spider (Spider 对象) – 被关闭的spider
# 可选实现,当spider被关闭时,这个方法被调用
完善之前的案例:
item写入JSON文件
以下pipeline将所有(从所有’spider’中)爬取到的item,存储到一个独立地items.json 文件,每行包含一个序列化为’JSON’格式的’item’。
打开 pipelines.py 文件,写入下面代码:
# pipelines.py
import json
class ItcastJsonPipeline(object):
def __init__(self):
self.file = open('teacher.json', 'wb')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(content)
return item
def close_spider(self, spider):
self.file.close()
启用一个Item Pipeline组件
为了启用Item Pipeline组件,必须将它的类添加到 settings.py文件ITEM_PIPELINES 配置,就像下面这个例子:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
#'mySpider.pipelines.SomePipeline': 300,
"mySpider.pipelines.ItcastJsonPipeline":300
}
分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内(0-1000随意设置,数值越低,组件的优先级越高)
重新启动爬虫
将parse()方法改为的如下代码
思考如果将代码改成下面形式,结果完全一样。请思考 yield 在这里的作用:
import scrapy
from mySpider.items import ItcastItem
class ItcastSpider(scrapy.Spider):
name = 'itcast'
allowed_domains = ['itcast.cn']
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
def parse(self, response):
# open("teacher.html","wb").write(response.body).close()
# 存放老师信息的集合
items = []
for each in response.xpath("//div[@class='li_txt']"):
# 将我们得到的数据封装到一个 `ItcastItem` 对象
item = ItcastItem()
# extract()方法返回的都是字符串
name = each.xpath("h3/text()").extract_first()
title = each.xpath("h4/text()").extract_first()
info = each.xpath("p/text()").extract_first()
item['name'] = name
item['title'] = title
item['info'] = info
# 将获取的数据交给pipelines
yield item
# 返回数据,不经过pipeline
# return items
然后执行下面的命令:
scrapy crawl itcast
查看当前目录是否生成teacher.json
查看json数据的内容
4.5 Spider
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
class scrapy.Spider是最基本的类,所有编写的爬虫必须继承这个类。
主要用到的函数及调用顺序为:
__init__() : 初始化爬虫名字和start_urls列表
start_requests() 调用make_requests_from url():生成Requests对象交给Scrapy下载并返回response
parse() : 解析response,并返回Item或Requests(需指定回调函数)。Item传给Item pipline持久化 , 而Requests交由Scrapy下载,并由指定的回调函数处理(默认parse()),一直进行循环,直到处理完所有的数据为止。
源码参考
#所有爬虫的基类,用户定义的爬虫必须从这个类继承
class Spider(object_ref):
#定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。
#name是spider最重要的属性,而且是必须的。
#一般做法是以该网站(domain)(加或不加 后缀 )来命名spider。 例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
name = None
#初始化,提取爬虫名字,start_ruls
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
# 如果爬虫没有名字,中断后续操作则报错
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
# python 对象或类型通过内置成员__dict__来存储成员信息
self.__dict__.update(kwargs)
#URL列表。当没有指定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
if not hasattr(self, 'start_urls'):
self.start_urls = []
# 打印Scrapy执行后的log信息
def log(self, message, level=log.DEBUG, **kw):
log.msg(message, spider=self, level=level, **kw)
# 判断对象object的属性是否存在,不存在做断言处理
def set_crawler(self, crawler):
assert not hasattr(self, '_crawler'), "Spider already bounded to %s" % crawler
self._crawler = crawler
@property
def crawler(self):
assert hasattr(self, '_crawler'), "Spider not bounded to any crawler"
return self._crawler
@property
def settings(self):
return self.crawler.settings
#该方法将读取start_urls内的地址,并为每一个地址生成一个Request对象,交给Scrapy下载并返回Response
#该方法仅调用一次
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
#start_requests()中调用,实际生成Request的函数。
#Request对象默认的回调函数为parse(),提交的方式为get
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
#默认的Request对象回调函数,处理返回的response。
#生成Item或者Request对象。用户必须实现这个类
def parse(self, response):
raise NotImplementedError
@classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls)
def __str__(self):
return "<%s %r at 0x%0x>" % (type(self).__name__, self.name, id(self))
__repr__ = __str__
主要属性和方法
-
name
定义spider名字的字符串。
例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite
-
allowed_domains
包含了spider允许爬取的域名(domain)的列表,可选。
-
start_urls
初始URL元祖/列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。
-
start_requests(self)
该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取(默认实现是使用 start_urls 的url)的第一个Request。
当spider启动爬取并且未指定start_urls时,该方法被调用。
-
parse(self, response)
当请求url返回网页没有指定回调函数时,默认的Request对象回调函数。用来处理网页返回的response,以及生成Item或者Request对象。
-
log(self, message[, level, component])
使用 scrapy.log.msg() 方法记录(log)message。 更多数据请参见 logging
案例:链家网自动翻页采集
- 创建一个新的爬虫:
scrapy genspider tencent "lianjia.com"
# -*- coding: utf-8 -*-
import scrapy
import copy
import math
import uuid
class ErshoufangSpider(scrapy.Spider):
name = 'ershoufang'
allowed_domains = ['lianjia.com']
start_urls = ['https://www.lianjia.com/city/']
# 提取所有城市的链接
def parse(self, response):
province_list = response.xpath("//div[@class='city_province']")
for province in province_list:
province_name = province.xpath("./div/text()").get()
city_list = province.xpath("./ul/li/a")
for city in city_list:
item = {}
city_name = city.xpath("./text()").get()
city_url = city.xpath("./@href").get()
# 链接分为两类:没有二手房的链接和有二手房的链接
if "fang" in city_url:
continue
# print(province_name, city_name, city_url)
# 将所有城市的链接转化为二手房的链接
city_esf_url = city_url + "ershoufang/co32/"
item["province"] = province_name
item["city"] = city_name
yield scrapy.Request(url=city_esf_url, callback=self.parse_city, meta={"item": copy.deepcopy(item)})
def parse_city(self, response):
city_url = response.url
info = response.meta.get("item")
all_count = int(response.xpath("//h2[contains(@class, 'total')]/span/text()").get())
max_page = 100 if all_count > 30 * 100 else math.floor(all_count/30)
template_url_list = city_url.split("/")
template_url_list[-2] = "pg{}co32"
template_url = "/".join(template_url_list)
for page in range(1, max_page + 1):
per_page_url = template_url.format(page)
yield scrapy.Request(url=per_page_url, callback=self.parse_per_page, meta={"item": copy.deepcopy(info)})
def parse_per_page(self, response):
info = response.meta.get("item")
houses = response.xpath("//ul[@class='sellListContent']/li")
for house in houses:
house_url = house.xpath("./a/@href").get()
info["url"] = house_url
yield scrapy.Request(url=house_url, callback=self.parse_house_detail, meta={"item": copy.deepcopy(info)})
def parse_house_detail(self, response):
item = response.meta.get("item")
# 描述
try:
item["desc"] = response.xpath("//h1[@class='main']/text()").get()
except:
item["desc"] = ""
# 总价
try:
item["totalPrice"] = response.xpath("//span[@class='total']/text()").get()
except:
item["totalPrice"] = ""
# 单价
try:
item["unitPrice"] = response.xpath("//span[@class='unitPriceValue']/text()").get()
except:
item["unitPrice"] = ""
# 面积
try:
item["area"] = response.xpath("//div[@class='area']/div[@class='mainInfo']/text()").get()
except:
item["area"] = ""
# 类型
try:
item["type"] = response.xpath("//div[@class='area']/div[@class='subInfo']/text()").get()
except:
item["type"] = ""
# 朝向
try:
item["aspect"] = response.xpath("//div[@class='type']/div[@class='mainInfo']/text()").get()
except:
item["aspect"] = ""
# 房间
try:
item["room"] = response.xpath("//div[@class='room']/div[@class='mainInfo']/text()").get()
except:
item["room"] = ""
# 楼层
try:
item["floor"] = response.xpath("//div[@class='room']/div[@class='subInfo']/text()").get()
except:
item["floor"] = ""
# 所在区
try:
item["region"] = response.xpath("//div[@class='areaName']/span[@class='info']/a[1]/text()").get()
except:
item["region"] = ""
# 具体地址
try:
item["around"] = response.xpath("//div[@class='communityName']/a[contains(@class,'info')]/text()").get()
except:
item["around"] = ""
address = item["province"] + item["city"] + item["region"] + item["around"]
item["address"] = address
item["_id"] = uuid.uuid1().hex
item = copy.deepcopy(item)
return item
- 编写pipeline.py文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.exceptions import DropItem
import pymongo
import pymysql
class SavePipeline:
def __init__(self):
self.client = pymongo.MongoClient(host="127.0.0.1", port=27017)
self.database = self.client["spider"]
self.col = self.database["LianjiaData"]
def process_item(self, item, spider):
try:
self.col.insert_one(item)
except Exception as e:
spider.logger.warning(e)
return item
- 在 setting.py 里设置ITEM_PIPELINES
# -*- coding: utf-8 -*-
BOT_NAME = 'lianjia'
SPIDER_MODULES = ['lianjia.spiders']
NEWSPIDER_MODULE = 'lianjia.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 2
DOWNLOADER_MIDDLEWARES = {
'lianjia.middlewares.RandomUADownloaderMiddleware': 100,
}
ITEM_PIPELINES = {
'lianjia.pipelines.SavePipeline': 1000,
}
LOG_FILE = "lianjia.log"
LOG_LEVEL = "WARNING"
- 执行爬虫:`scrapy crawl ershoufang
思考
请思考 parse()方法的工作机制:
1. 如果使用的yield,而不是return。parse函数将会被当做一个生成器使用。scrapy会逐一获取parse方法中生成的结果,并判断该结果是一个什么样的类型;
2. 如果是request则加入爬取队列,如果是item类型则使用pipeline处理,其他类型则返回错误信息。
3. scrapy取到第一部分的request不会立马就去发送这个request,只是把这个request放到队列里,然后接着从生成器里获取;
4. 取尽第一部分的request,然后再获取第二部分的item,取到item了,就会放到对应的pipeline里处理;
5. parse()方法作为回调函数(callback)赋值给了Request,指定parse()方法来处理这些请求 scrapy.Request(url, callback=self.parse)
6. Request对象经过调度,执行生成 scrapy.http.response()的响应对象,并送回给parse()方法,直到调度器中没有Request(递归的思路)
7. 取尽之后,parse()工作结束,引擎再根据队列和pipelines中的内容去执行相应的操作;
8. 程序在取得各个页面的items前,会先处理完之前所有的request队列里的请求,然后再提取items。
7. 这一切的一切,Scrapy引擎和调度器将负责到底。
常见bug
[scrapy.spidermiddlewares.offsite] DEBUG: Filtered offsite request to ‘hr.tencent.com’:
解决方式:
domain错误 修改domain为:hr.tencent.com
4.6 CrawlSpiders
通过下面的命令可以快速创建 CrawlSpider模板 的代码:
scrapy genspider -t crawl tencent tencent.com
上一个案例中,我们通过正则表达式,制作了新的url作为Request请求参数,现在我们可以换个花样…
class scrapy.spiders.CrawlSpider
它是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类定义了一些规则(rule)来提供跟进link的方便的机制,从爬取的网页中获取link并继续爬取的工作更适合。
源码参考
class CrawlSpider(Spider):
rules = ()
def __init__(self, *a, **kw):
super(CrawlSpider, self).__init__(*a, **kw)
self._compile_rules()
#首先调用parse()来处理start_urls中返回的response对象
#parse()则将这些response对象传递给了_parse_response()函数处理,并设置回调函数为parse_start_url()
#设置了跟进标志位True
#parse将返回item和跟进了的Request对象
def parse(self, response):
return self._parse_response(response, self.parse_start_url, cb_kwargs={}, follow=True)
#处理start_url中返回的response,需要重写
def parse_start_url(self, response):
return []
def process_results(self, response, results):
return results
#从response中抽取符合任一用户定义'规则'的链接,并构造成Resquest对象返回
def _requests_to_follow(self, response):
if not isinstance(response, HtmlResponse):
return
seen = set()
#抽取之内的所有链接,只要通过任意一个'规则',即表示合法
for n, rule in enumerate(self._rules):
links = [l for l in rule.link_extractor.extract_links(response) if l not in seen]
#使用用户指定的process_links处理每个连接
if links and rule.process_links:
links = rule.process_links(links)
#将链接加入seen集合,为每个链接生成Request对象,并设置回调函数为_repsonse_downloaded()
for link in links:
seen.add(link)
#构造Request对象,并将Rule规则中定义的回调函数作为这个Request对象的回调函数
r = Request(url=link.url, callback=self._response_downloaded)
r.meta.update(rule=n, link_text=link.text)
#对每个Request调用process_request()函数。该函数默认为indentify,即不做任何处理,直接返回该Request.
yield rule.process_request(r)
#处理通过rule提取出的连接,并返回item以及request
def _response_downloaded(self, response):
rule = self._rules[response.meta['rule']]
return self._parse_response(response, rule.callback, rule.cb_kwargs, rule.follow)
#解析response对象,会用callback解析处理他,并返回request或Item对象
def _parse_response(self, response, callback, cb_kwargs, follow=True):
#首先判断是否设置了回调函数。(该回调函数可能是rule中的解析函数,也可能是 parse_start_url函数)
#如果设置了回调函数(parse_start_url()),那么首先用parse_start_url()处理response对象,
#然后再交给process_results处理。返回cb_res的一个列表
if callback:
#如果是parse调用的,则会解析成Request对象
#如果是rule callback,则会解析成Item
cb_res = callback(response, **cb_kwargs) or ()
cb_res = self.process_results(response, cb_res)
for requests_or_item in iterate_spider_output(cb_res):
yield requests_or_item
#如果需要跟进,那么使用定义的Rule规则提取并返回这些Request对象
if follow and self._follow_links:
#返回每个Request对象
for request_or_item in self._requests_to_follow(response):
yield request_or_item
def _compile_rules(self):
def get_method(method):
if callable(method):
return method
elif isinstance(method, basestring):
return getattr(self, method, None)
self._rules = [copy.copy(r) for r in self.rules]
for rule in self._rules:
rule.callback = get_method(rule.callback)
rule.process_links = get_method(rule.process_links)
rule.process_request = get_method(rule.process_request)
def set_crawler(self, crawler):
super(CrawlSpider, self).set_crawler(crawler)
self._follow_links = crawler.settings.getbool('CRAWLSPIDER_FOLLOW_LINKS', True)
CrawlSpider继承于Spider类,除了继承过来的属性外(name、allow_domains),还提供了新的属性和方法:
rules
CrawlSpider使用rules来决定爬虫的爬取规则,并将匹配后的url请求提交给引擎。所以在正常情况下,CrawlSpider不需要单独手动返回请求了。
在rules中包含一个或多个Rule对象,每个Rule对爬取网站的动作定义了某种特定操作,比如提取当前相应内容里的特定链接,是否对提取的链接跟进爬取,对提交的请求设置回调函数等。
如果多个rule匹配了相同的链接,则根据规则在本集合中被定义的顺序,第一个会被使用。
class scrapy.spiders.Rule(
link_extractor,
callback = None,
cb_kwargs = None,
follow = None,
process_links = None,
process_request = None
)
-
link_extractor:是一个Link Extractor对象,用于定义需要提取的链接。 -
callback: 从link_extractor中每获取到链接时,参数所指定的值作为回调函数,该回调函数接受一个response作为其第一个参数。注意:当编写爬虫规则时,避免使用parse作为回调函数。由于CrawlSpider使用parse方法来实现其逻辑,如果覆盖了 parse方法,crawl spider将会运行失败。
-
follow:是一个布尔(boolean)值,指定了根据该规则从response提取的链接是否需要跟进。 如果callback为None,follow 默认设置为True ,否则默认为False。 -
process_links:指定该spider中哪个的函数将会被调用,从link_extractor中获取到链接列表时将会调用该函数。该方法主要用来过滤。 -
process_request:指定该spider中哪个的函数将会被调用, 该规则提取到每个request时都会调用该函数。 (用来过滤request)
LinkExtractors
class scrapy.linkextractors.LinkExtractor
Link Extractors 的目的很简单: 提取链接。
每个LinkExtractor有唯一的公共方法是 extract_links(),它接收一个 Response 对象,并返回一个 scrapy.link.Link 对象。
Link Extractors要实例化一次,并且 extract_links 方法会根据不同的 response 调用多次提取链接。
class scrapy.linkextractors.LinkExtractor(
allow = (),
deny = (),
allow_domains = (),
deny_domains = (),
deny_extensions = None,
restrict_xpaths = (),
tags = ('a','area'),
attrs = ('href'),
canonicalize = True,
unique = True,
process_value = None
)
主要参数:
allow:满足括号中“正则表达式”的URL会被提取,如果为空,则全部匹配。deny:满足括号中“正则表达式”的URL一定不提取(优先级高于allow)。allow_domains:会被提取的链接的domains。deny_domains:一定不会被提取链接的domains。restrict_xpaths:使用xpath表达式,和allow共同作用过滤链接。
爬取规则(Crawling rules)
继续用腾讯招聘为例,给出配合rule使用CrawlSpider的例子:
-
首先运行
scrapy shell "http://hr.tencent.com/position.php?&start=0#a" -
导入LinkExtractor,创建LinkExtractor实例对象。:
from scrapy.linkextractors import LinkExtractor page_lx = LinkExtractor(allow=('position.php?&start=\d+'))allow : LinkExtractor对象最重要的参数之一,这是一个正则表达式,必须要匹配这个正则表达式(或正则表达式列表)的URL才会被提取,如果没有给出(或为空), 它会匹配所有的链接。
deny : 用法同allow,只不过与这个正则表达式匹配的URL不会被提取)。它的优先级高于 allow 的参数,如果没有给出(或None), 将不排除任何链接。
-
调用LinkExtractor实例的extract_links()方法查询匹配结果:
page_lx.extract_links(response) -
没有查到:
[] -
注意转义字符的问题,继续重新匹配:
page_lx = LinkExtractor(allow=('position\.php\?&start=\d+')) # page_lx = LinkExtractor(allow = ('start=\d+')) page_lx.extract_links(response)
CrawlSpider 版本
那么,scrapy shell测试完成之后,修改以下代码
#提取匹配 'http://hr.tencent.com/position.php?&start=\d+'的链接
page_lx = LinkExtractor(allow = ('start=\d+'))
rules = [
#提取匹配,并使用spider的parse方法进行分析;并跟进链接(没有callback意味着follow默认为True)
Rule(page_lx, callback = 'parse', follow = True)
]
这么写对吗?
不对!千万记住 callback 千万不能写 parse,再次强调:由于CrawlSpider使用parse方法来实现其逻辑,如果覆盖了 parse方法,crawl spider将会运行失败。
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class TecentSpider(CrawlSpider):
name = 'tecent'
allowed_domains = ['hr.tencent.com']
start_urls = ['http://hr.tencent.com/position.php?&start=0']
page_lx = LinkExtractor(allow=r'start=\d+')
#position.php?&start=10#a
rules = (
Rule(page_lx, callback='parse_item', follow=True),
)
def parse_item(self, response):
items = response.xpath('//*[contains(@class,"odd") or contains(@class,"even")]')
for item in items:
temp = dict(
position=item.xpath("./td[1]/a/text()").extract()[0],
detailLink="http://hr.tencent.com/" + item.xpath("./td[1]/a/@href").extract()[0],
type=item.xpath('./td[2]/text()').extract()[0] if len(
item.xpath('./td[2]/text()').extract()) > 0 else None,
need_num=item.xpath('./td[3]/text()').extract()[0],
location=item.xpath('./td[4]/text()').extract()[0],
publish_time=item.xpath('./td[5]/text()').extract()[0]
)
print(temp)
yield temp
# parse() 方法不需要重写
# def parse(self, response):
# pass
运行: scrapy crawl tencent
Logging
Scrapy提供了log功能,可以通过 logging 模块使用。
可以修改配置文件settings.py,任意位置添加下面两行,效果会清爽很多。
LOG_FILE = "TencentSpider.log"
LOG_LEVEL = "INFO"
Log levels
- Scrapy提供5层logging级别:
- CRITICAL - 严重错误(critical)
- ERROR - 一般错误(regular errors)
- WARNING - 警告信息(warning messages)
- INFO - 一般信息(informational messages)
- DEBUG - 调试信息(debugging messages)
logging设置
通过在setting.py中进行以下设置可以被用来配置logging:
LOG_ENABLED默认: True,启用loggingLOG_ENCODING默认: ‘utf-8’,logging使用的编码LOG_FILE默认: None,在当前目录里创建logging输出文件的文件名LOG_LEVEL默认: ‘DEBUG’,log的最低级别LOG_STDOUT默认: False 如果为 True,进程所有的标准输出(及错误)将会被重定向到log中。例如,执行 print “hello” ,其将会在Scrapy log中显示。
4.7 Request和Response
Request
Request 部分源码:
# 部分代码
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None):
self._encoding = encoding # this one has to be set first
self.method = str(method).upper()
self._set_url(url)
self._set_body(body)
assert isinstance(priority, int), "Request priority not an integer: %r" % priority
self.priority = priority
assert callback or not errback, "Cannot use errback without a callback"
self.callback = callback
self.errback = errback
self.cookies = cookies or {}
self.headers = Headers(headers or {}, encoding=encoding)
self.dont_filter = dont_filter
self._meta = dict(meta) if meta else None
@property
def meta(self):
if self._meta is None:
self._meta = {}
return self._meta
其中,比较常用的参数:
url: 就是需要请求,并进行下一步处理的url
callback: 指定该请求返回的Response,由那个函数来处理。
method: 请求一般不需要指定,默认GET方法,可设置为"GET", "POST", "PUT"等,且保证字符串大写
headers: 请求时,包含的头文件。一般不需要。内容一般如下:
# 自己写过爬虫的肯定知道
Host: media.readthedocs.org
User-Agent: Mozilla/5.0 (Windows NT 6.2; WOW64; rv:33.0) Gecko/20100101 Firefox/33.0
Accept: text/css,*/*;q=0.1
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Referer: http://scrapy-chs.readthedocs.org/zh_CN/0.24/
Cookie: _ga=GA1.2.1612165614.1415584110;
Connection: keep-alive
If-Modified-Since: Mon, 25 Aug 2014 21:59:35 GMT
Cache-Control: max-age=0
meta: 比较常用,在不同的请求之间传递数据使用的。字典dict型
request_with_cookies = Request(
url="http://www.example.com",
cookies={'currency': 'USD', 'country': 'UY'},
meta={'dont_merge_cookies': True}
)
encoding: 使用默认的 'utf-8' 就行。
dont_filter: 表明该请求不由调度器过滤。这是当你想使用多次执行相同的请求,忽略重复的过滤器。默认为False。
errback: 指定错误处理函数
Response
# 部分代码
class Response(object_ref):
def __init__(self, url, status=200, headers=None, body='', flags=None, request=None):
self.headers = Headers(headers or {})
self.status = int(status)
self._set_body(body)
self._set_url(url)
self.request = request
self.flags = [] if flags is None else list(flags)
@property
def meta(self):
try:
return self.request.meta
except AttributeError:
raise AttributeError("Response.meta not available, this response " \
"is not tied to any request")
大部分参数和上面的差不多:
status: 响应码
_set_body(body): 响应体
_set_url(url):响应url
self.request = request
发送POST请求
- 可以使用
yield scrapy.FormRequest(url, formdata, callback)方法发送POST请求。 - 如果希望程序执行一开始就发送POST请求,可以重写Spider类的
start_requests(self)方法,并且不再调用start_urls里的url。
class mySpider(scrapy.Spider):
# start_urls = ["http://www.example.com/"]
def start_requests(self):
url = 'http://www.renren.com/PLogin.do'
# FormRequest 是Scrapy发送POST请求的方法
yield scrapy.FormRequest(
url = url,
formdata = {"email" : "mr_mao_hacker@163.com", "password" : "axxxxxxxe"},
callback = self.parse_page
)
def parse_page(self, response):
# do something
模拟登陆
使用FormRequest.from_response()方法模拟用户登录
通常网站通过 实现对某些表单字段(如数据或是登录界面中的认证令牌等)的预填充。
使用Scrapy抓取网页时,如果想要预填充或重写像用户名、用户密码这些表单字段, 可以使用 FormRequest.from_response() 方法实现。
下面是使用这种方法的爬虫例子:
import scrapy
class LoginSpider(scrapy.Spider):
name = 'example.com'
start_urls = ['http://www.example.com/users/login.php']
def parse(self, response):
return scrapy.FormRequest.from_response(
response,
formdata={'username': 'john', 'password': 'secret'},
callback=self.after_login
)
def after_login(self, response):
# check login succeed before going on
if "authentication failed" in response.body:
self.log("Login failed", level=log.ERROR)
return
# continue scraping with authenticated session...
知乎爬虫案例参考:
zhihuSpider.py爬虫代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from scrapy.spiders import CrawlSpider, Rule
from scrapy.selector import Selector
from scrapy.linkextractors import LinkExtractor
from scrapy import Request, FormRequest
from zhihu.items import ZhihuItem
class ZhihuSipder(CrawlSpider) :
name = "zhihu"
allowed_domains = ["www.zhihu.com"]
start_urls = [
"http://www.zhihu.com"
]
rules = (
Rule(LinkExtractor(allow = ('/question/\d+#.*?', )), callback = 'parse_page', follow = True),
Rule(LinkExtractor(allow = ('/question/\d+', )), callback = 'parse_page', follow = True),
)
headers = {
"Accept": "*/*",
"Accept-Language": "en-US,en;q=0.8,zh-TW;q=0.6,zh;q=0.4",
"Connection": "keep-alive",
"Content-Type":" application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2125.111 Safari/537.36",
"Referer": "http://www.zhihu.com/"
}
#重写了爬虫类的方法, 实现了自定义请求, 运行成功后会调用callback回调函数
def start_requests(self):
return [Request("https://www.zhihu.com/login", meta = {'cookiejar' : 1}, callback = self.post_login)]
def post_login(self, response):
print 'Preparing login'
#下面这句话用于抓取请求网页后返回网页中的_xsrf字段的文字, 用于成功提交表单
xsrf = response.xpath('//input[@name="_xsrf"]/@value').extract()[0]
print xsrf
#FormRequeset.from_response是Scrapy提供的一个函数, 用于post表单
#登陆成功后, 会调用after_login回调函数
return [FormRequest.from_response(response, #"http://www.zhihu.com/login",
meta = {'cookiejar' : response.meta['cookiejar']},
headers = self.headers, #注意此处的headers
formdata = {
'_xsrf': xsrf,
'email': '123456@qq.com',
'password': '123456'
},
callback = self.after_login,
dont_filter = True
)]
def after_login(self, response) :
for url in self.start_urls :
yield self.make_requests_from_url(url)
def parse_page(self, response):
problem = Selector(response)
item = ZhihuItem()
item['url'] = response.url
item['name'] = problem.xpath('//span[@class="name"]/text()').extract()
print item['name']
item['title'] = problem.xpath('//h2[@class="zm-item-title zm-editable-content"]/text()').extract()
item['description'] = problem.xpath('//div[@class="zm-editable-content"]/text()').extract()
item['answer']= problem.xpath('//div[@class=" zm-editable-content clearfix"]/text()').extract()
return item
Item类设置
from scrapy.item import Item, Field
class ZhihuItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = Field() #保存抓取问题的url
title = Field() #抓取问题的标题
description = Field() #抓取问题的描述
answer = Field() #抓取问题的答案
name = Field() #个人用户的名称
setting.py 设置抓取间隔
BOT_NAME = 'zhihu'
SPIDER_MODULES = ['zhihu.spiders']
NEWSPIDER_MODULE = 'zhihu.spiders'
DOWNLOAD_DELAY = 0.25 #设置下载间隔为250ms
4.8 download middlewares
反反爬虫相关机制
Some websites implement certain measures to prevent bots from crawling them, with varying degrees of sophistication. Getting around those measures can be difficult and tricky, and may sometimes require special infrastructure. Please consider contacting commercial support if in doubt.
(有些些网站使用特定的不同程度的复杂性规则防止爬虫访问,绕过这些规则是困难和复杂的,有时可能需要特殊的基础设施,如果有疑问,请联系商业支持。)
来自于Scrapy官方文档描述:http://doc.scrapy.org/en/master/topics/practices.html#avoiding-getting-banned
通常防止爬虫被反主要有以下几个策略:
-
动态设置User-Agent(随机切换User-Agent,模拟不同用户的浏览器信息)
-
禁用Cookies(也就是不启用cookies middleware,不向Server发送cookies,有些网站通过cookie的使用发现爬虫行为)
- 可以通过
COOKIES_ENABLED控制 CookiesMiddleware 开启或关闭
- 可以通过
-
设置延迟下载(防止访问过于频繁,设置为 2秒 或更高)
-
Google Cache 和 Baidu Cache:如果可能的话,使用谷歌/百度等搜索引擎服务器页面缓存获取页面数据。
-
使用IP地址池:VPN和代理IP,现在大部分网站都是根据IP来ban的。
-
使用 Crawlera(专用于爬虫的代理组件),正确配置和设置下载中间件后,项目所有的request都是通过crawlera发出。
DOWNLOADER_MIDDLEWARES = { 'scrapy_crawlera.CrawleraMiddleware': 600 } CRAWLERA_ENABLED = True CRAWLERA_USER = '注册/购买的UserKey' CRAWLERA_PASS = '注册/购买的Password'
设置下载中间件(Downloader Middlewares)
下载中间件是处于引擎(crawler.engine)和下载器(crawler.engine.download())之间的一层组件,可以有多个下载中间件被加载运行。
- 当引擎传递请求给下载器的过程中,下载中间件可以对请求进行处理 (例如增加http header信息,增加proxy信息等);
- 在下载器完成http请求,传递响应给引擎的过程中, 下载中间件可以对响应进行处理(例如进行gzip的解压等)
要激活下载器中间件组件,将其加入到 DOWNLOADER_MIDDLEWARES 设置中。 该设置是一个字典(dict),键为中间件类的路径,值为其中间件的顺序(order)。
这里是一个例子:
DOWNLOADER_MIDDLEWARES = {
'mySpider.middlewares.MyDownloaderMiddleware': 543,
}
编写下载器中间件十分简单。每个中间件组件是一个定义了以下一个或多个方法的Python类:
class scrapy.contrib.downloadermiddleware.DownloaderMiddleware
process_request(self, request, spider)
- 当每个request通过下载中间件时,该方法被调用。
- process_request() 必须返回以下其中之一:一个 None 、一个 Response 对象、一个 Request 对象或 raise IgnoreRequest:
- 如果其返回 None ,Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用, 该request被执行(其response被下载)。
- 如果其返回 Response 对象,Scrapy将不会调用 任何 其他的 process_request() 或 process_exception() 方法,或相应地下载函数; 其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
- 如果其返回 Request 对象,Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。
- 如果其raise一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)。
- 参数:
request (Request 对象)– 处理的requestspider (Spider 对象)– 该request对应的spider
process_response(self, request, response, spider)
当下载器完成http请求,传递响应给引擎的时候调用
- process_request() 必须返回以下其中之一: 返回一个 Response 对象、 返回一个 Request 对象或raise一个 IgnoreRequest 异常。
- 如果其返回一个 Response (可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理。
- 如果其返回一个 Request 对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于 process_request() 返回request所做的那样。
- 如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
- 参数:
request (Request 对象)– response所对应的requestresponse (Response 对象)– 被处理的responsespider (Spider 对象)– response所对应的spider
使用案例:
- 创建
middlewares.py文件。
Scrapy代理IP、Uesr-Agent的切换都是通过DOWNLOADER_MIDDLEWARES进行控制,我们在settings.py同级目录下创建middlewares.py文件,包装所有请求。
# middlewares.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import random
import base64
from settings import USER_AGENTS
from settings import PROXIES
# 随机的User-Agent
class RandomUserAgent(object):
def process_request(self, request, spider):
useragent = random.choice(USER_AGENTS)
request.headers.setdefault("User-Agent", useragent)
class RandomProxy(object):
def process_request(self, request, spider):
proxy = random.choice(PROXIES)
if proxy['user_passwd'] is None:
# 没有代理账户验证的代理使用方式
request.meta['proxy'] = "http://" + proxy['ip_port']
else:
# 对账户密码进行base64编码转换
base64_userpasswd = base64.b64encode(proxy['user_passwd'])
# 对应到代理服务器的信令格式里
request.headers['Proxy-Authorization'] = 'Basic ' + base64_userpasswd
request.meta['proxy'] = "http://" + proxy['ip_port']
为什么HTTP代理要使用base64编码:
HTTP代理的原理很简单,就是通过HTTP协议与代理服务器建立连接,协议信令中包含要连接到的远程主机的IP和端口号,如果有需要身份验证的话还需要加上授权信息,服务器收到信令后首先进行身份验证,通过后便与远程主机建立连接,连接成功之后会返回给客户端200,表示验证通过,就这么简单,下面是具体的信令格式:
CONNECT 59.64.128.198:21 HTTP/1.1
Host: 59.64.128.198:21
Proxy-Authorization: Basic bGV2I1TU5OTIz
User-Agent: OpenFetion
其中
Proxy-Authorization是身份验证信息,Basic后面的字符串是用户名和密码组合后进行base64编码的结果,也就是对username:password进行base64编码。
HTTP/1.0 200 Connection established
OK,客户端收到收面的信令后表示成功建立连接,接下来要发送给远程主机的数据就可以发送给代理服务器了,代理服务器建立连接后会在根据IP地址和端口号对应的连接放入缓存,收到信令后再根据IP地址和端口号从缓存中找到对应的连接,将数据通过该连接转发出去。
- 修改settings.py配置USER_AGENTS和PROXIES
- 添加USER_AGENTS:
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
-
添加代理IP设置PROXIES:
免费代理IP可以网上搜索,或者付费购买一批可用的私密代理IP:
PROXIES = [
{'ip_port': '111.8.60.9:8123', 'user_passwd': 'user1:pass1'},
{'ip_port': '101.71.27.120:80', 'user_passwd': 'user2:pass2'},
{'ip_port': '122.96.59.104:80', 'user_passwd': 'user3:pass3'},
{'ip_port': '122.224.249.122:8088', 'user_passwd': 'user4:pass4'},
]
- 除非特殊需要,禁用cookies,防止某些网站根据Cookie来封锁爬虫。
COOKIES_ENABLED = False
- 设置下载延迟
DOWNLOAD_DELAY = 3
- 最后设置setting.py里的DOWNLOADER_MIDDLEWARES,添加自己编写的下载中间件类。
DOWNLOADER_MIDDLEWARES = {
#'mySpider.middlewares.MyCustomDownloaderMiddleware': 543,
'mySpider.middlewares.RandomUserAgent': 1,
'mySpider.middlewares.ProxyMiddleware': 100
}
4.9 Settings
Scrapy设置(settings)提供了定制Scrapy组件的方法。可以控制包括核心(core),插件(extension),pipeline及spider组件。比如 设置Json Pipeliine、LOG_LEVEL等。
参考文档:http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/settings.html#topics-settings-ref
内置设置参考手册
-
BOT_NAME- 默认: ‘scrapybot’
- 当您使用 startproject 命令创建项目时其也被自动赋值。
-
CONCURRENT_ITEMS- 默认: 100
- Item Processor(即 Item Pipeline) 同时处理(每个response的)item的最大值。
-
CONCURRENT_REQUESTS- 默认: 16
- Scrapy downloader 并发请求(concurrent requests)的最大值。
-
DEFAULT_REQUEST_HEADERS-
默认: 如下
{ 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', }Scrapy HTTP Request使用的默认header。
-
-
DEPTH_LIMIT- 默认: 0
- 爬取网站最大允许的深度(depth)值。如果为0,则没有限制。
-
DOWNLOAD_DELAY- 默认: 0
- 下载器在下载同一个网站下一个页面前需要等待的时间。该选项可以用来限制爬取速度, 减轻服务器压力。同时也支持小数:
DOWNLOAD_DELAY = 0.25 # 250 ms of delay- 默认情况下,Scrapy在两个请求间不等待一个固定的值, 而是使用0.5到1.5之间的一个随机值 * DOWNLOAD_DELAY 的结果作为等待间隔。
-
DOWNLOAD_TIMEOUT- 默认: 180
- 下载器超时时间(单位: 秒)。
-
ITEM_PIPELINES-
默认: {}
-
保存项目中启用的pipeline及其顺序的字典。该字典默认为空,值(value)任意,不过值(value)习惯设置在0-1000范围内,值越小优先级越高。
ITEM_PIPELINES = { 'mySpider.pipelines.SomethingPipeline': 300, 'mySpider.pipelines.ItcastJsonPipeline': 800, }
-
-
LOG_ENABLED- 默认: True
- 是否启用logging。
-
LOG_ENCODING- 默认: ‘utf-8’
- logging使用的编码。
-
LOG_LEVEL- 默认: ‘DEBUG’
- log的最低级别。可选的级别有: CRITICAL、 ERROR、WARNING、INFO、DEBUG 。
-
USER_AGENT- 默认: “Scrapy/VERSION (+http://scrapy.org)”
- 爬取的默认User-Agent,除非被覆盖。
-
PROXIES: 代理设置-
示例:
PROXIES = [ {'ip_port': '111.11.228.75:80', 'password': ''}, {'ip_port': '120.198.243.22:80', 'password': ''}, {'ip_port': '111.8.60.9:8123', 'password': ''}, {'ip_port': '101.71.27.120:80', 'password': ''}, {'ip_port': '122.96.59.104:80', 'password': ''}, {'ip_port': '122.224.249.122:8088', 'password':''}, ]
-
-
COOKIES_ENABLED = False- 禁用Cookies
- 禁用Cookies