第一章:数据清洗常用工具
1.numpy常用数据结构
常用清洗工具:
- 目前在Python中, numpy和pandas是最主流的工具
- Numpy中的向量化运算使得数据处理变得高效
- Pandas提供了大量数据清洗的高效方法
- 在Python中,尽可能多的使用numpy和pandas中的 函数,提高数据清洗的效率
numpy常用数据结构:
- Numpy中常用的数据结构是ndarray格式
- 使用array函数创建,语法格式为array(列表或元组)
- 可以使用其他函数例如arange、linspace、zeros等创建
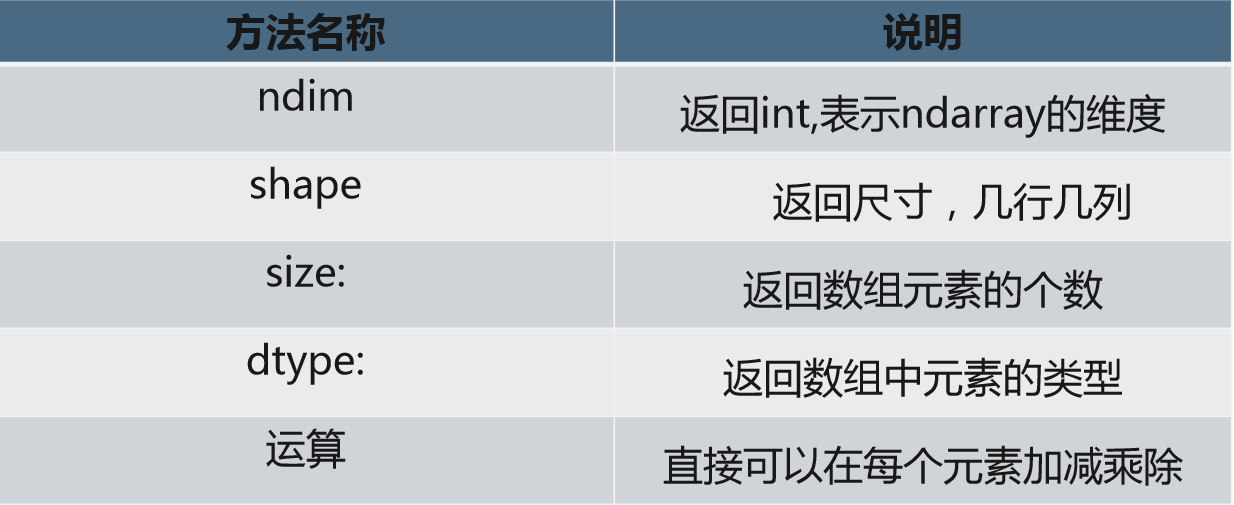
Numpy常用方法
数组访问方法
练习(jupyter)代码下面是结果
1 Numpy常用数据结构
1. 数组创建
import numpy as np
#一维数组
arr1=np.array([-9,7,4,3])
type(arr1)
numpy.ndarray
arr1
array([-9, 7, 4, 3])
int
arr1=np.array([-9,7,4,3],dtype='int')
arr1
array([-9, 7, 4, 3])
#二维数组
arr3 = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
arr3
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
np.arange(1,10,2)
array([1, 3, 5, 7, 9])
True
np.linspace(1,10,20,endpoint=True)
array([ 1. , 1.47368421, 1.94736842, 2.42105263, 2.89473684,
3.36842105, 3.84210526, 4.31578947, 4.78947368, 5.26315789,
5.73684211, 6.21052632, 6.68421053, 7.15789474, 7.63157895,
8.10526316, 8.57894737, 9.05263158, 9.52631579, 10. ])
9/19
0.47368421052631576
np.zeros(4)
array([0., 0., 0., 0.])
np.ones([2,3])
array([[1., 1., 1.],
[1., 1., 1.]])
arr3+1.5
array([[ 2.5, 3.5, 4.5, 5.5],
[ 6.5, 7.5, 8.5, 9.5],
[10.5, 11.5, 12.5, 13.5]])
1.2 数组方法
arr1.ndim
1
arr1.shape#逗号后面无数字说明一维数组
(4,)
arr3.shape
(3, 4)
arr3.size
12
arr3.dtype
dtype('int32')
data2 = ((8.5,6,4.1,2,0.7),(1.5,3,5.4,7.3,9),(3.2,4.5,6,3,9),(11.2,13.4,15.6,17.8,19))
arr2 = np.array(data2)
arr2
arr2
array([[ 8.5, 6. , 4.1, 2. , 0.7],
[ 1.5, 3. , 5.4, 7.3, 9. ],
[ 3.2, 4.5, 6. , 3. , 9. ],
[11.2, 13.4, 15.6, 17.8, 19. ]])
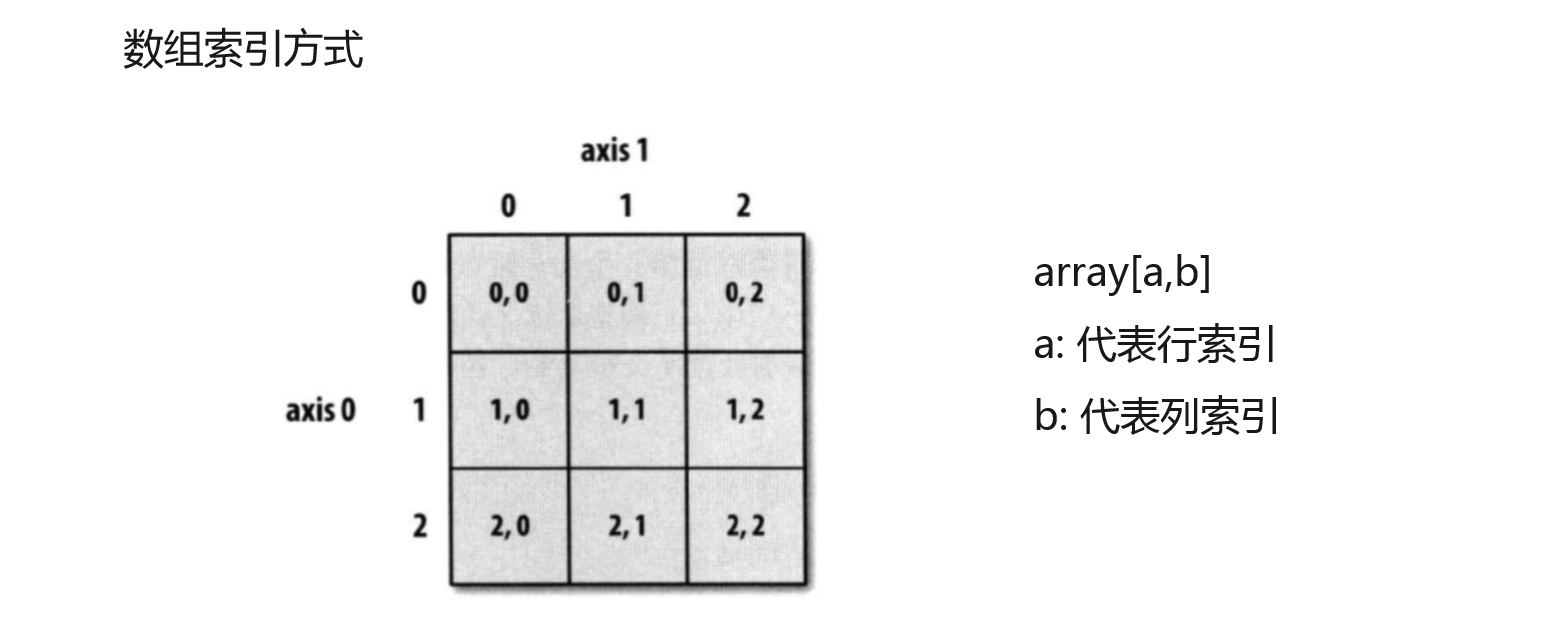
arr2[0:3]#第一行到第三行
array([[8.5, 6. , 4.1, 2. , 0.7],
[1.5, 3. , 5.4, 7.3, 9. ],
[3.2, 4.5, 6. , 3. , 9. ]])
arr2[1,2]#区第二行第三列数据 “,”左边是行操作,右边是列操作
5.4
arr2[:,3]#去第三列数据,如果不加:取的是行数
array([11.2, 13.4, 15.6, 17.8, 19. ])
arr2[:,1:3]#区第二列和第三列数据
array([[ 6. , 4.1],
[ 3. , 5.4],
[ 4.5, 6. ],
[13.4, 15.6]])
2.Numpy常用数据清洗函数
数据的排序

数据的搜索

练习(jupyter)代码下面是结果
1.3 Numpy常用数据清洗函数
排序 降序建议用sorted函数
s = np.array([1,2,3,4,3,1,2,2,4,6,7,2,4,8,4,5])
np.sort(s)
array([1, 1, 2, 2, 2, 2, 3, 3, 4, 4, 4, 4, 5, 6, 7, 8])
sorted(s,reverse =True)#降序
[8, 7, 6, 5, 4, 4, 4, 4, 3, 3, 2, 2, 2, 2, 1, 1]
arr1 = np.array([[0,1,3],[4,2,9],[4,5,9],[1,-3,4]])
arr1
array([[ 0, 1, 3],
[ 4, 2, 9],
[ 4, 5, 9],
[ 1, -3, 4]])
np.sort(arr1)
array([[ 0, 1, 3],
[ 2, 4, 9],
[ 4, 5, 9],
[-3, 1, 4]])
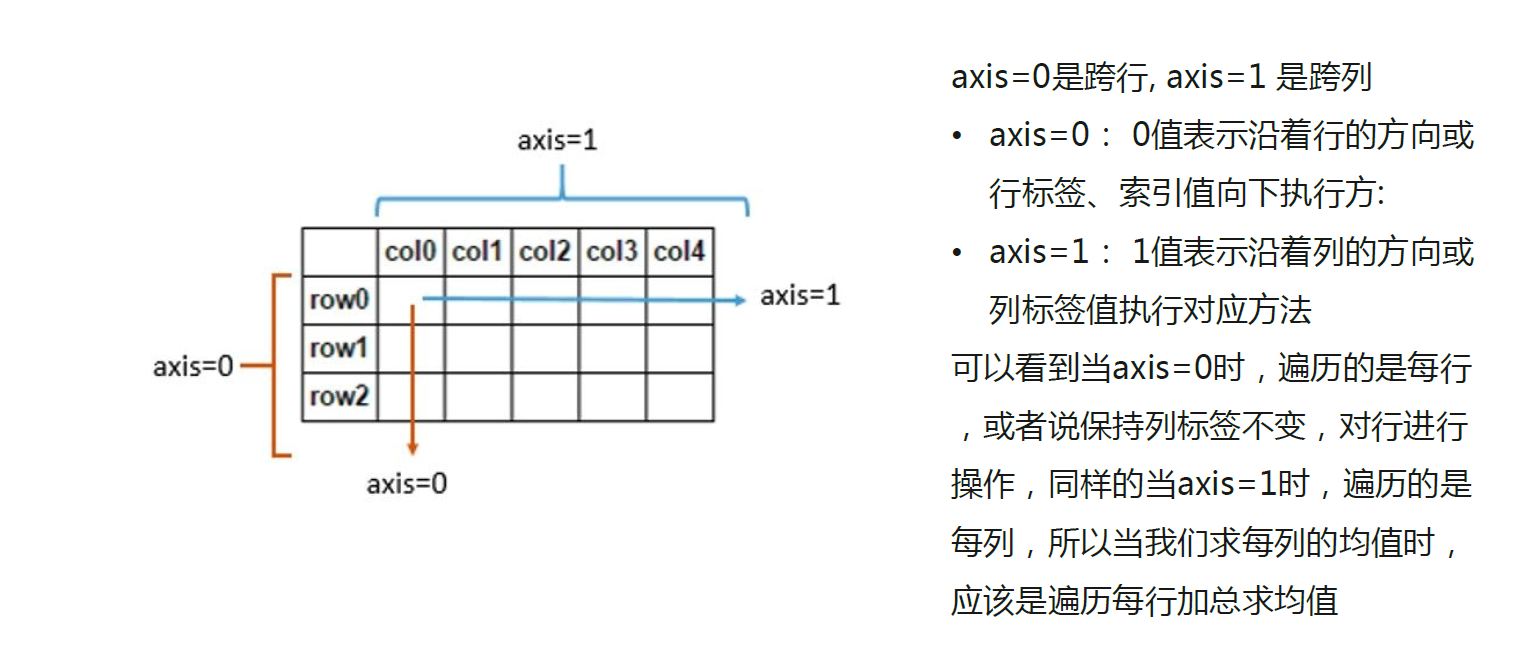
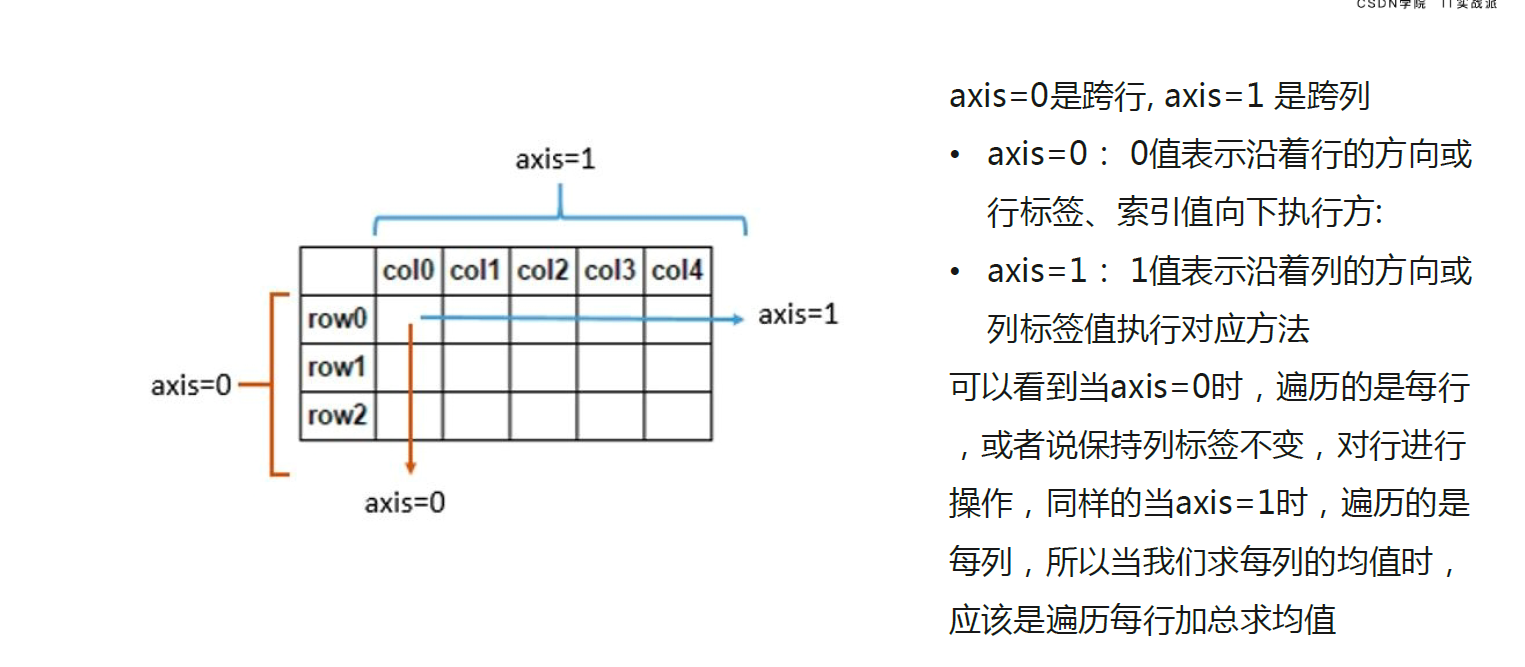
np.sort(arr1,axis = 0) # 0代表沿着行的方向, 1代表沿着列的方向 不加axis参输默认按照1的方式排序
array([[ 0, -3, 3],
[ 1, 1, 4],
[ 4, 2, 9],
[ 4, 5, 9]])
np.sort(arr1,axis = 1)
array([[ 0, 1, 3],
[ 2, 4, 9],
[ 4, 5, 9],
[-3, 1, 4]])
-argsort返回的是排完序以后,在原数据中的索引位置
-返回的是数据中,从小到大的索引值
s = np.array([1,2,3,4,3,1,2,2,4,6,7,2,4,8,4,5])
np.argsort(s)
array([ 0, 5, 1, 6, 7, 11, 2, 4, 3, 8, 12, 14, 15, 9, 10, 13],
dtype=int64)
#np.where和np.extract
np.where(s>3,1,-1)# 满足条件的,赋值为3,不满足的赋值为-1,返回的数据长度和s一样
array([-1, -1, -1, 1, -1, -1, -1, -1, 1, 1, 1, -1, 1, 1, 1, 1])
np.extract(s>3,s)# 只输出满足条件的数据
array([4, 4, 6, 7, 4, 8, 4, 5])
3.Pandas常用数据结构series和dataframe
series

dataframe

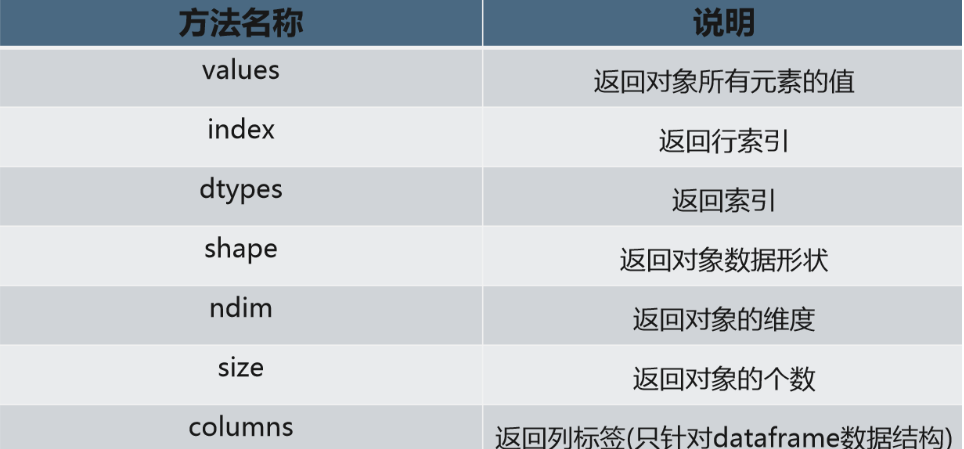
常用方法
练习(jupyter)代码下面是结果
# 构造数据框
#数据框其实就是一个二维表结构,是数据分析中,最常用的数据结构
list1 = [['张三',23,'男'],['李四',27,'女'],['王二',26,'女']]#使用嵌套列表
df1 = pd.DataFrame(list1,columns=['姓名','年龄','性别'])
type(df1)
pandas.core.frame.DataFrame
df2 = pd.DataFrame({'姓名':['张三','李四','王二'],'年龄':[23,27,26],'性别':['男','女','女']}) #使用字典,字典的键被当成列名
df2
df2
姓名 年龄 性别
0 张三 23 男
1 李四 27 女
2 王二 26 女
array1 = np.array([['张三',23,'男'],['李四',27,'女'],['王二', 26,'女']]) #使用numpy
df3 = pd.DataFrame(array1,columns=['姓名','年龄','性别'],index = ['a','b','c'] )
df3
姓名 年龄 性别
a 张三 23 男
b 李四 27 女
c 王二 26 女
#dataframe方法
df2.values
array([['张三', 23, '男'],
['李四', 27, '女'],
['王二', 26, '女']], dtype=object)
df2.index
RangeIndex(start=0, stop=3, step=1)
df2.columns
df2.columns
Index(['姓名', '年龄', '性别'], dtype='object')
df2.dtypes
姓名 object
年龄 int64
性别 object
dtype: object
df2.ndim
2
df2.size
9
第二章:数据清洗之文件读取
这是一个关于淘宝母婴产品的用户消费行为的数据集,然后基于这个数据集,做数据清洗
数据集地址:https://pan.baidu.com/s/1kMH1AhE8RUyaT73rvJsVPQ
提取码:aai6
csv文件读写

import pandas as pd
import numpy as np
import os
# 更改文件路劲
os.chdir(r'G:\pythonProject\pc\Python数据清洗\data')
#设置最大显示列数
pd.set_option('display.max_columns', 20)
#设置最大显示行数
pd.set_option('display.max_rows', 100)
# 婴儿信息表
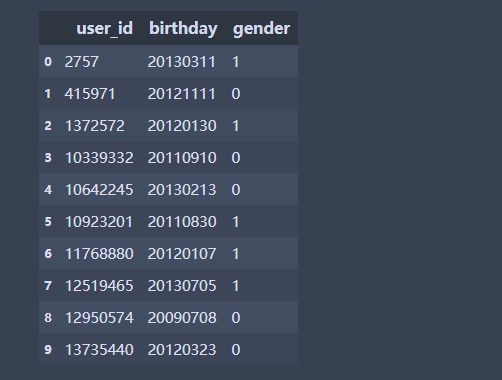
baby = pd.read_csv('sam_tianchi_mum_baby.csv', encoding='utf-8')#默认将第一行作为表头,一般用utf-8编码
baby.head(10)
# 编码为gbk中文编码
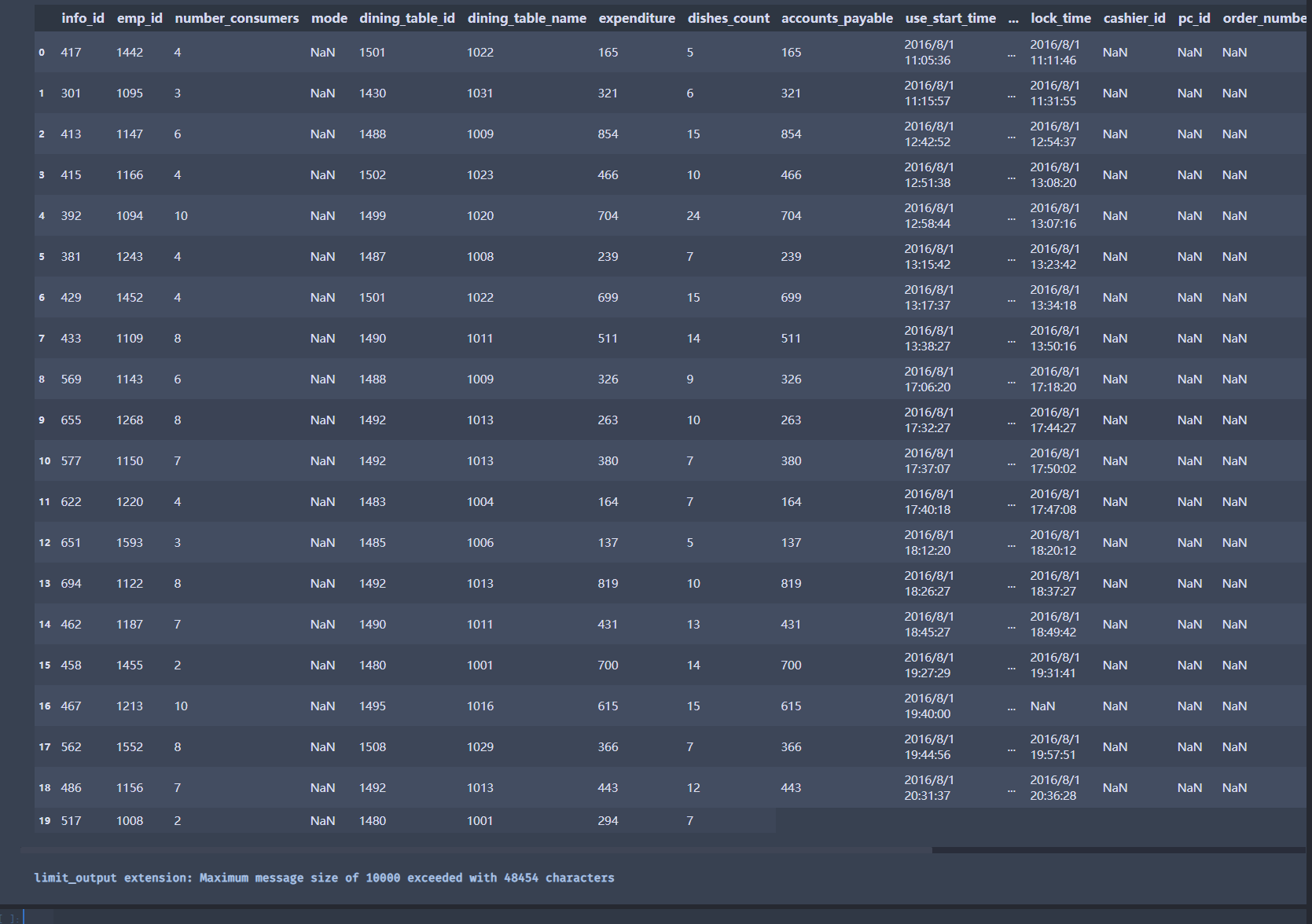
# 订单数据
order = pd.read_csv('meal_order_info.csv',encoding = 'gbk', dtype = {'info_id':str,'emp_id':str})
#这里转换字段类型方便统一处理
order
excel文件读写

# 订单数据
df1 = pd.read_excel('meal_order_detail.xlsx',encoding = 'utf-8',sheet_name = 'meal_order_detail1')# 读取excel需要注明具体哪一个工作簿,否则就是第一个工作簿
df1.head(5)

df2 = pd.read_excel('meal_order_detail.xlsx',encoding = 'utf-8',sheet_name = 0)# sheet_name可以为数字,代表第几个工作簿
df2.head(5)

#保存数据
df1.to_excel('a1.xlsx',sheet_name='one',index=False)
数据库文件读写

#导入相关库
import pymysql
from sqlalchemy import create_engine
按实际情况依次填写MySQL的用户名、密码、IP地址、端口、数据库名 create_engine(‘mysql+pymysql://user:passward@IP:3306/test01’)
root 用户名
passward --密码
IP : 服务区IP
3306: 端口号
test01 :数据库名称
# 建立连接
conn = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
# 读取数据
sql = 'select * from meal_order_info' #选择数据库中表名称
df1 = pd.read_sql(sql,conn)
#df1 是个dataframe格式

# # # 函数
def query(table):
host = 'localhost'
user = 'root'
password = '123456'
database = 'test'
port = 3306
conn = create_engine("mysql+pymysql://{}:{}@{}:{}/{}".format(user, password, host, port, database))
#SQL语句,可以定制,实现灵活查询
sql = 'select * from ' + table #选择数据库中表名称
# 使用pandas 的read_sql函数,可以直接将数据存放在dataframe中
results = pd.read_sql(sql,conn)
return results
df2 = query('dim_color')
df2

数据保存
df.to_sql(name,con=engine,if_exists=‘replace/append/fail’,index=False)
name是表名
con是连接
if_exists:表如果存在怎么处理 – append:追加 – replace:删除原表,建立新表再添加 – fail:什么都不干
index=False:不插入索引index
import os
os.chdir(r'G:\pythonProject\pc\Python数据清洗\data')
df = pd.read_csv('baby_trade_history.csv')
try:
df.to_sql('dim_color',con = conn, index= False,if_exists= 'replace')
print(df.head(5))
except:
print('error')
#Python是否能将数据写入数据库,很多时候取决于数据库的权限
第三章:数据清洗之数据表处理
数据筛选

练习
import pandas as pd
import numpy as np
import os
# 更改文件路劲
os.chdir(r'G:\pythonProject\pc\Python数据清洗\data')
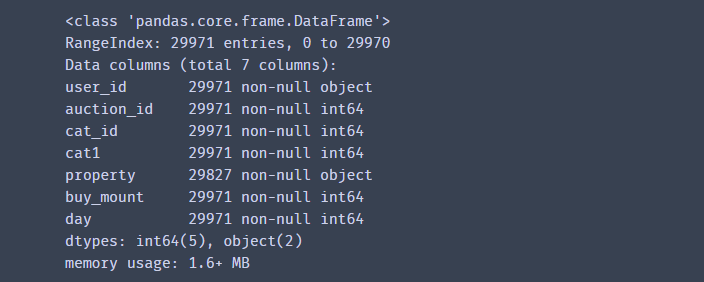
df = pd.read_csv('baby_trade_history.csv', encoding='utf-8',dtype={'user_id':str})
#数据筛选
#查看数据
df.info()
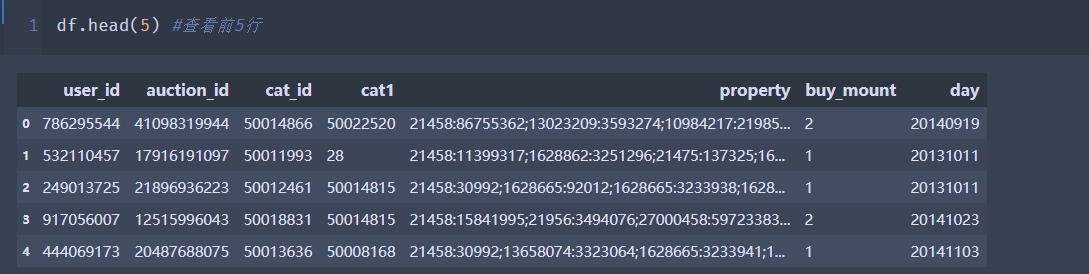
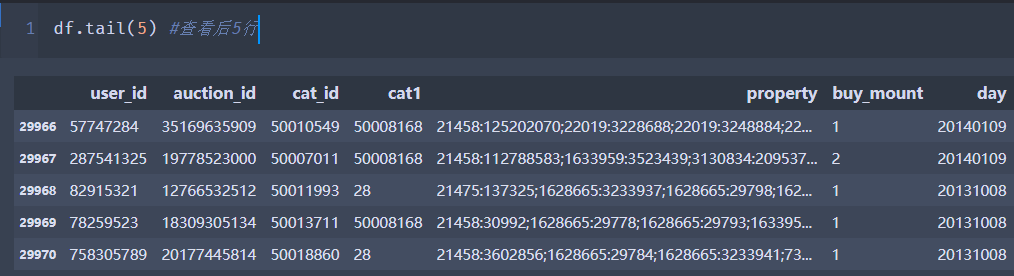

简单索引
df['user_id']
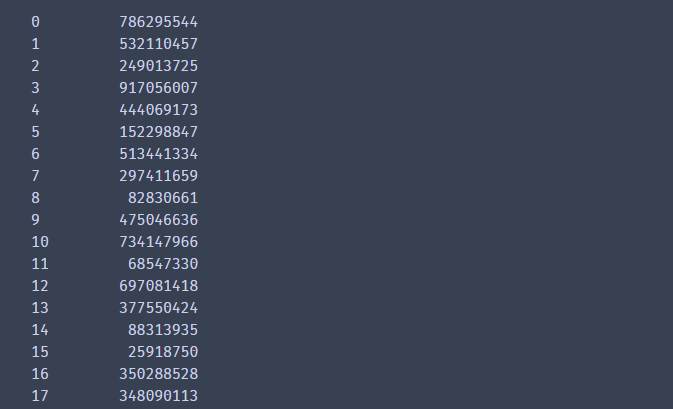
df['user_id'][1:5]# 第二行到第五行(左开右闭)
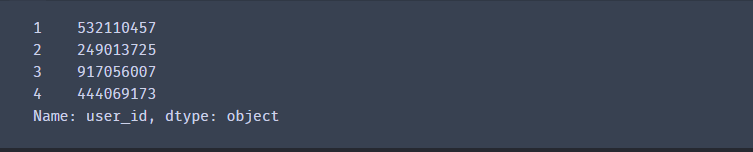
# 多个变量选择
df[:5][['user_id','buy_mount','day']]
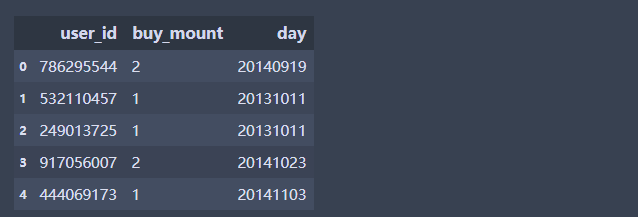
# loc和iloc 的使用
df.loc[3:4]# 选择行索引标签

df.loc[:,['user_id','buy_mount']]#选择某两列
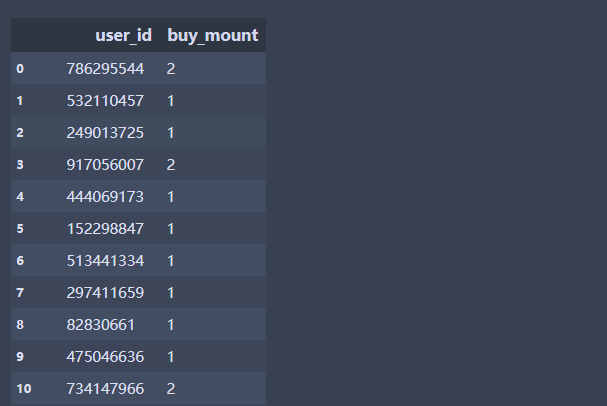
df.loc[1:3,['user_id','buy_mount']] #loc在这里选择的是行索引标签

df.loc[df.user_id =='786295544',['user_id','buy_mount','day']]

df.loc[(df.user_id =='786295544') | (df.user_id =='444069173'),['user_id','buy_mount','day']]# 多个条件选择

#注意iloc是位置
df.iloc[:,1:4] #按照位置来选择第二列到第四列(左开右闭和df的选择一样)
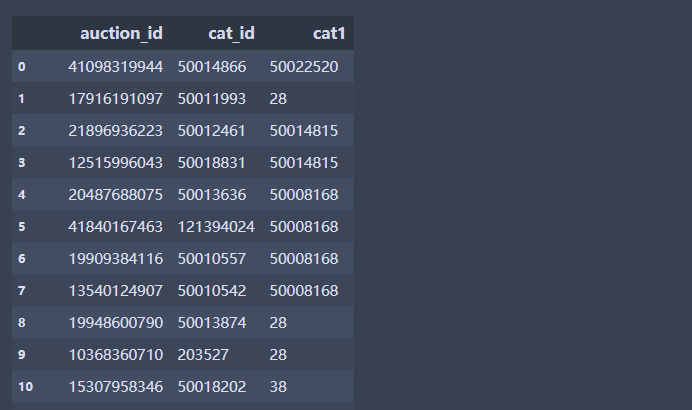
df.iloc[:,[0,2]] # 按照位置来选择第1列和第3列,这和上面不一样,左开右开,如果加了[]中间用,号
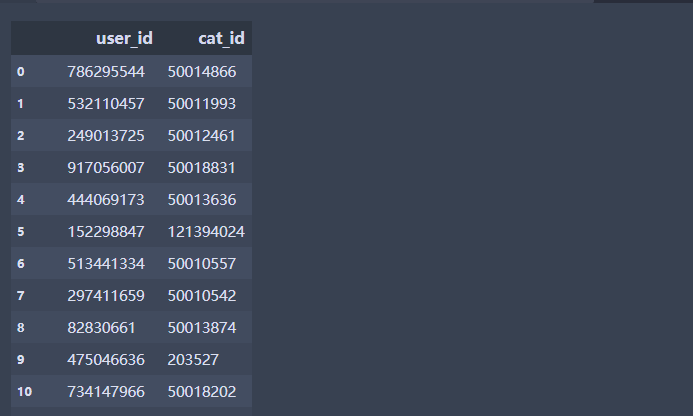
df.iloc[3,[1,2]] #选择第4行,第2列和第3列数据, 这里的3代表的不是索引标签而是位置

df.iloc[2:7,[1,2]] #选择第3行到第7行,第2列和第3列数据
- 注意loc和iloc的区别
df.loc[1:5]#索引,就是1行到5行
df.iloc[1:5]#位置,第二行到第五行(左开右闭)

数据增加和删除

练习
#增加一列,购买量,购买量超过3的为高,低于3的为底
df['购买量'] = np.where(df['buy_mount'] >3,'高','低')
df
# 增加行在dataframe中不常用,后面会用其他方法实现
# 可以使用append方法在 dataframe末尾实现
- 可以使用insert方法
- df.insert(位置,变量名称,值)
- 将auction_id取出来,放在一列
# 先将这一列取出来,赋值给对象auction_id,然后在数据中删除这一列,再将其添加进去
auction_id = df['auction_id']
del df['auction_id']
df.insert(0, 'auction_id', auction_id)
df.head(5)
- 删除
# 删除这两列,加inplace代表是否在原数据上操作,1代表沿着列的方向
# 同时删除多个变量,需要以列表的形式
# 注意inplace =True,代表是否对原数据操作, 否则返回的是视图,并没有对原数据进行操作
# labels表示删除的数据, axis表示作用轴,inplace=True表示是否对原数据生效,
# axis=0按行操作, axis=1按列操作
df.drop(labels = ['property', '购买量'],axis = 1,inplace=True) #删除这两列,加inplace代表是否在原数据上操作, 1代表沿着列的方向
df.head(5)
# 按行删除法
df.drop(labels = [3,4],inplace = True,axis= 0) # 删除索引标签3和4对应的行
df.drop(labels= range(6,11),axis=0,inplace=True) #删除索引名称1到10,注意range迭代器产生的是1到100
df.head(10)
数据的修改和查找

练习
df1 = pd.read_csv('sam_tianchi_mum_baby.csv',encoding = 'utf-8',dtype =str)
df1.head(5)
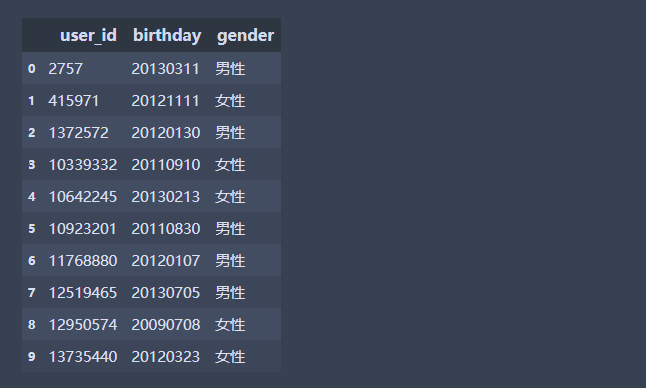
# 将gender为0的改为女性,1改为男性,2改为未知
df1.loc[df1['gender'] =='0','gender'] ="女性"
df1.loc[df1['gender'] =='1','gender'] ='男性'
df1.loc[df1['gender'] =='2','gender'] ='未知'
df1.head(10)
- 修改列名称
- basic.rename(columns={},index={})
# 修改列标签和行索引名称
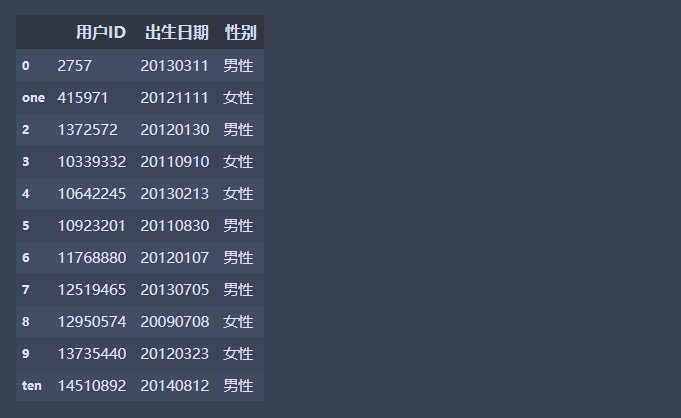
df1.rename(columns = {'user_id':'用户ID','birthday':'出生日期','gender':'性别'},inplace = True)
df1.rename(index = {1:'one',10:'ten' },inplace = True) #修改行索引名称
df1.head(11)
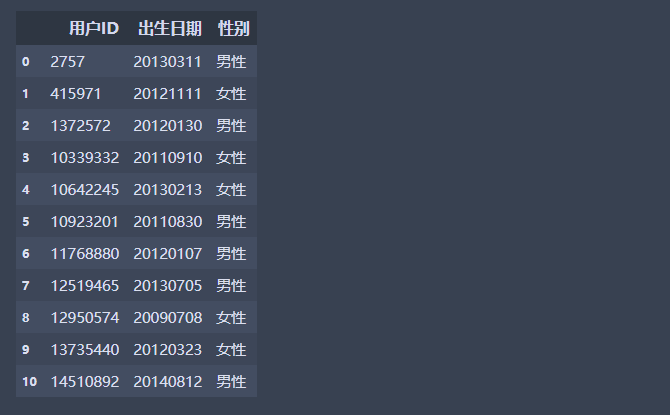
df1.reset_index(drop=True,inplace=True)# 重置索引
df1.head(11)
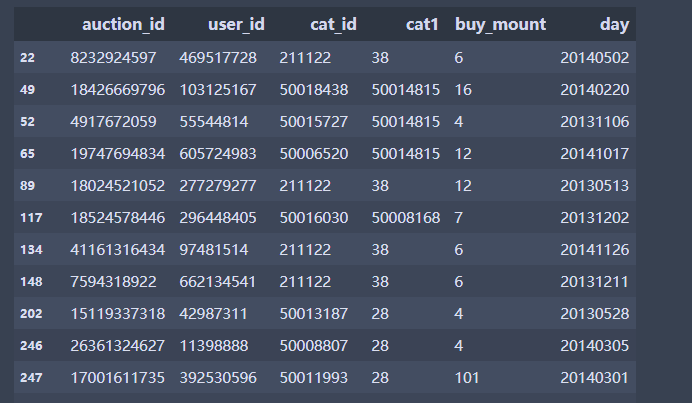
- 查询
# 条件查询
df[df.buy_mount > 3] #性别等于未知
df[~(df.buy_mount > 3)] # ~代表非
df[ (df.buy_mount > 3) & (df.day > 20140101)] # 多条件查询
#使用between,inclusive=True代表包含
df[ df['buy_mount'].between(4,10,inclusive=True)]
# 使用pd.isin()方法
# 包含
df[df['auction_id'].isin([41098319944, 17916191097,21896936223])]
数据整理
横向堆叠在数据清洗中不常用,纵向堆叠可以理解为把不同的表,字段名称一样整合在一起


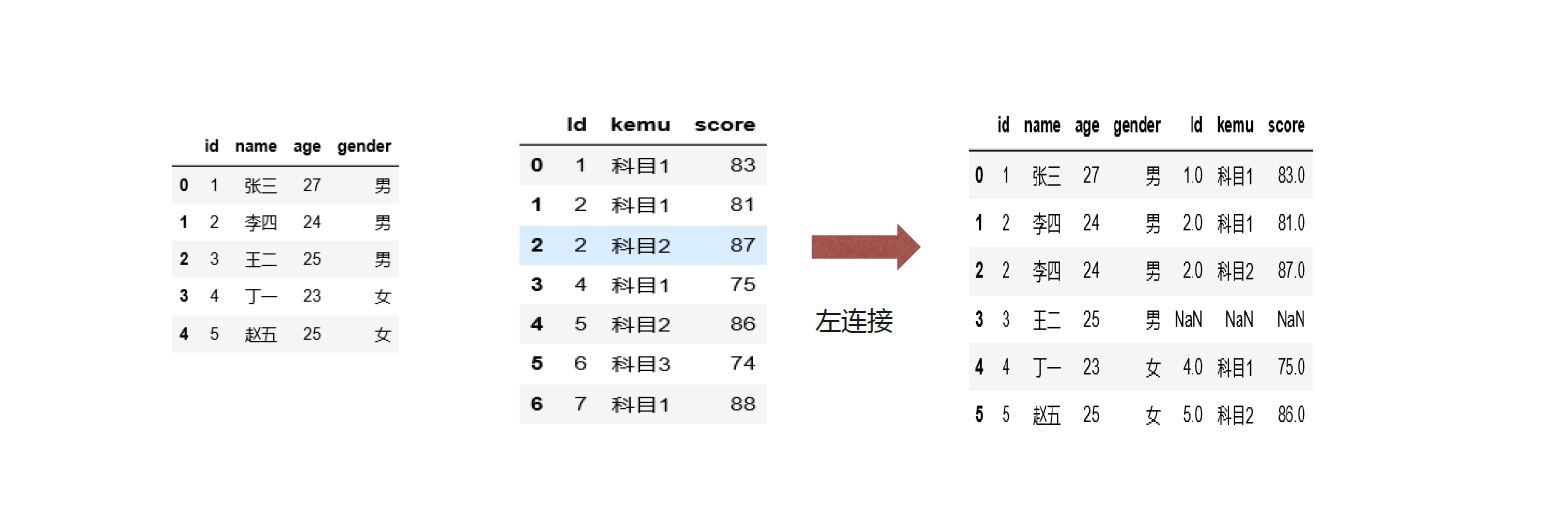

练习
import xlrd
workbook = xlrd.open_workbook('meal_order_detail.xlsx')
sheet_name = workbook.sheet_names() #返回所有sheet的列表
sheet_name

order1 = pd.read_excel('meal_order_detail.xlsx',sheet_name ='meal_order_detail1')
order2 = pd.read_excel('meal_order_detail.xlsx',sheet_name ='meal_order_detail2')
order3 = pd.read_excel('meal_order_detail.xlsx',sheet_name ='meal_order_detail3')
order = pd.concat([order1,order2,order3],axis=0,ignore_index=False)# 忽略原来的索引
print(order1.shape)
print(order2.shape)
print(order3.shape)
print(order.shape)

# 通过循环方式进行合并
basic = pd.DataFrame()
for i in sheet_name:
basic_i = pd.read_excel('meal_order_detail.xlsx', header = 0,sheet_name=i,encoding='utf-8')
basic = pd.concat([basic,basic_i],axis=0)
basic.shape

- 关联
- 关联字段必须类型一致
df3 = pd.read_csv('baby_trade_history.csv', encoding='utf-8',dtype={'user_id':str})# 交易数据
df4 = pd.read_csv('sam_tianchi_mum_baby.csv',encoding = 'utf-8',dtype =str)#婴儿信息
df5 = pd.merge(left = df3, right=df4, how='inner', left_on='user_id', right_on = 'user_id')# 内连接
df5.head(10)
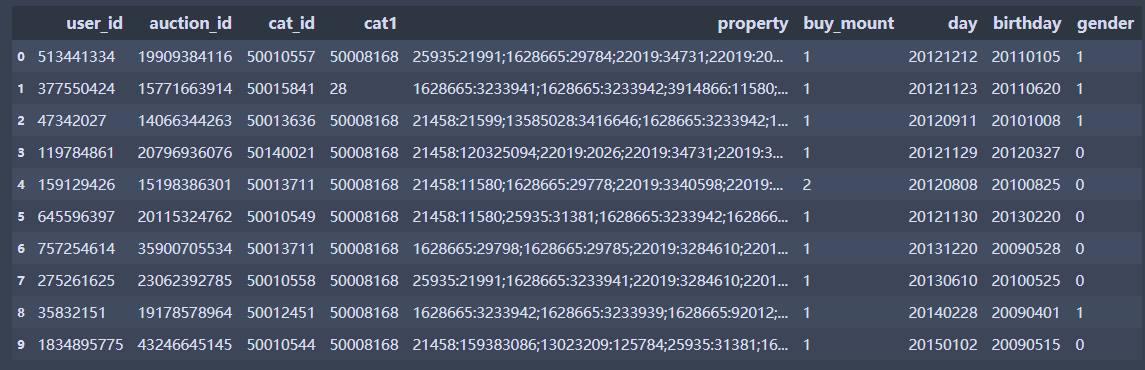
层次化索引
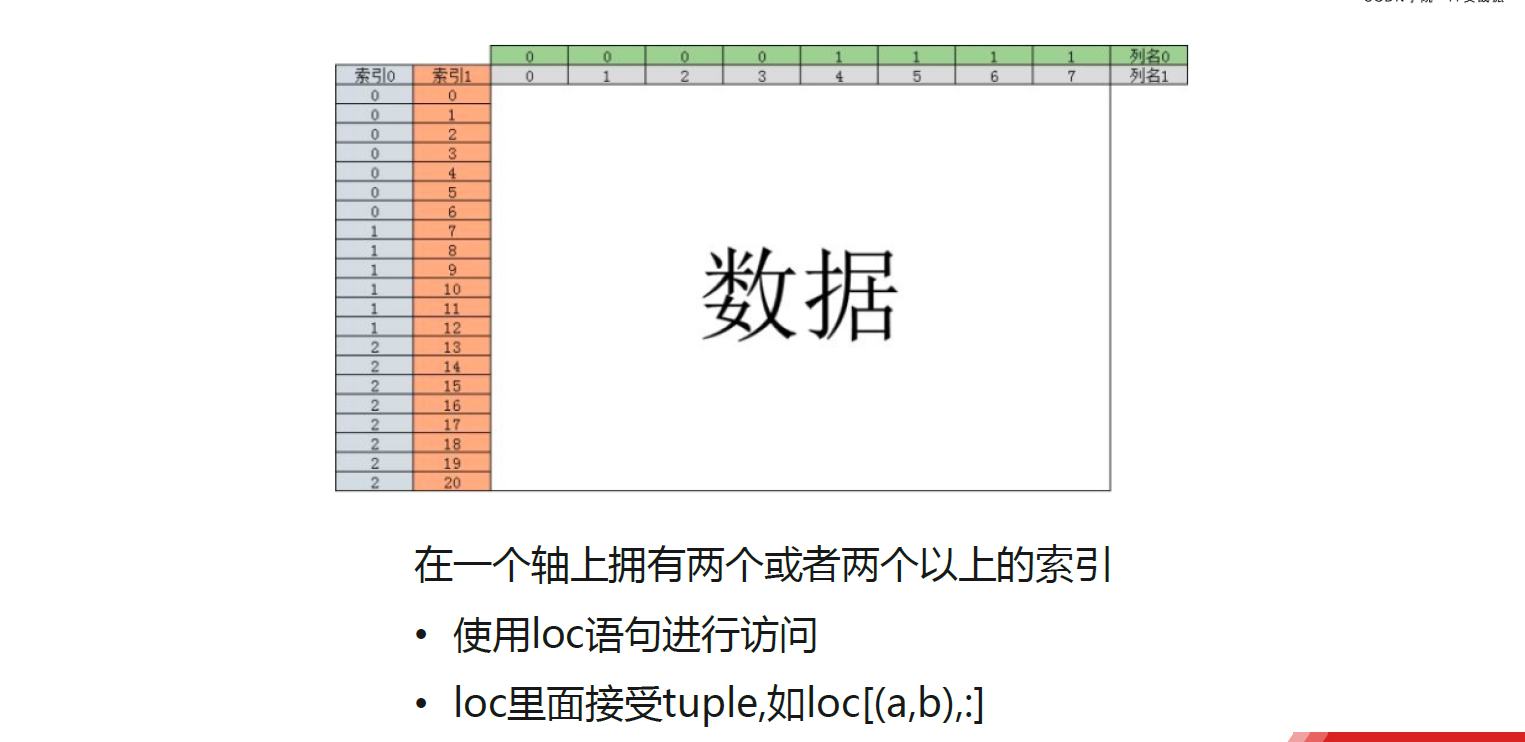
练习
df = pd.read_csv('baby_trade_history.csv', encoding='utf-8',dtype={'user_id':str},index_col=[3,1])#将数据第4列和第1列当成索引
df.head()
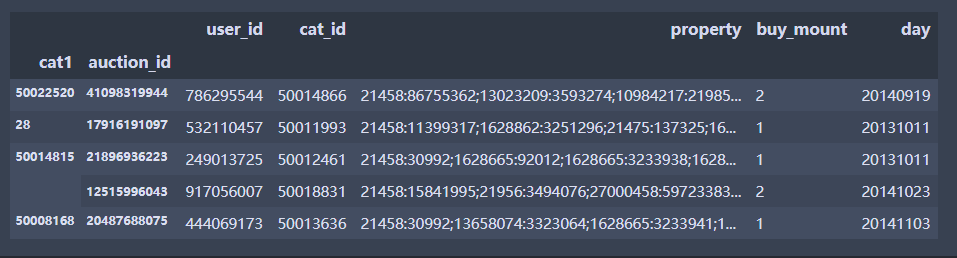
df.loc[28]#第一层引用
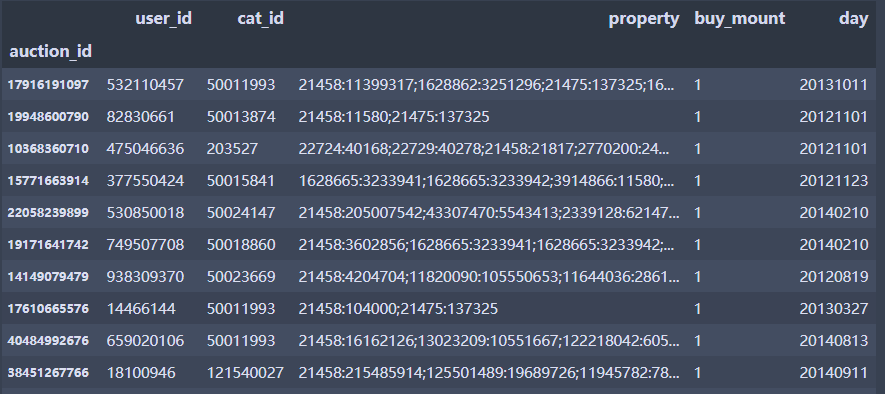
df.loc[28].loc[17916191097]#第二层引用

- 直接引用两层
- df3.loc[(a,b),:] #a和b分别代表第一层和第二层的索引
- 接受tuple
df.loc[(28,[17916191097,532110457]),:]# 第二层索引选择,多个选择
df
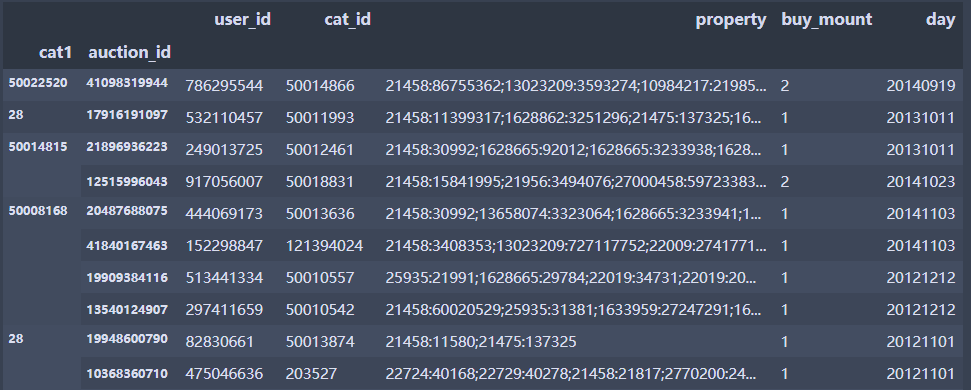
df.loc[(28,[17916191097,532110457]),['auction_id','cat_id']]# 第二层索引选择,选择2个变量

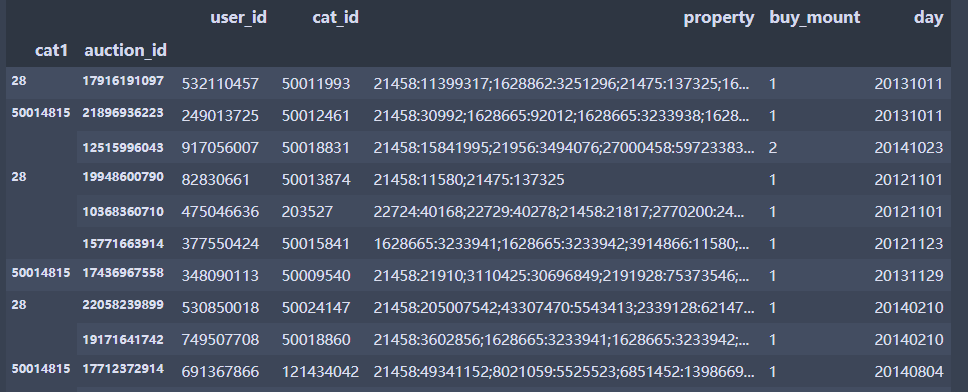
df.loc[([28,50014815])] #第一层索引为28和50014815
第四章:数据清洗之数据转换
日期数据格式处理
练习
import numpy as np
import pandas as pd
import os
os.chdir(r'G:\pythonProject\pc\Python数据清洗\data')
df = pd.read_csv('baby_trade_history.csv', encoding='utf-8',dtype={'user_id':str})
df.head(10)
# 对购买日期进行转换
df['buy_date'] = pd.to_datetime(df['day'],format='%Y%m%d',errors = 'coerce')#加errors防止报错
df.dtypes
# 可以提取对应年月日,必须为timestamp才可以,具体的时间点
df['buy_date'].dt.year#year也可以改成月日等等更精确的
- 时间差
# 对时间进行计算
df['diff_day'] = pd.datetime.now() - df['buy_date']
df['diff_day'].head(5)
# 时间差由天数,小时和毫秒构成
# timedelta可以理解为时间差类型
df['diff_day'].dt.days# 提取天数

df['diff_day'].dt.seconds# 提取秒数

df['diff_day'].dt.microseconds# 提取毫秒数
# 可以使用pd.Timedelta进行转换
df['时间差'] = df['diff_day']/pd.Timedelta('1 D') #转换为天数
df['时间差']
df['时间差'] = df['diff_day']/pd.Timedelta('1 M') #转换为分钟
df.head(5)

df['时间差'].round(decimals=3)# 显示为3小数
df["时间差"]
df['diff_day'].astype('timedelta64[D]')# 这种方式也可以,M 代表月份数,D代表天数,Y代表年份
df['diff_day']
字符串数据处理
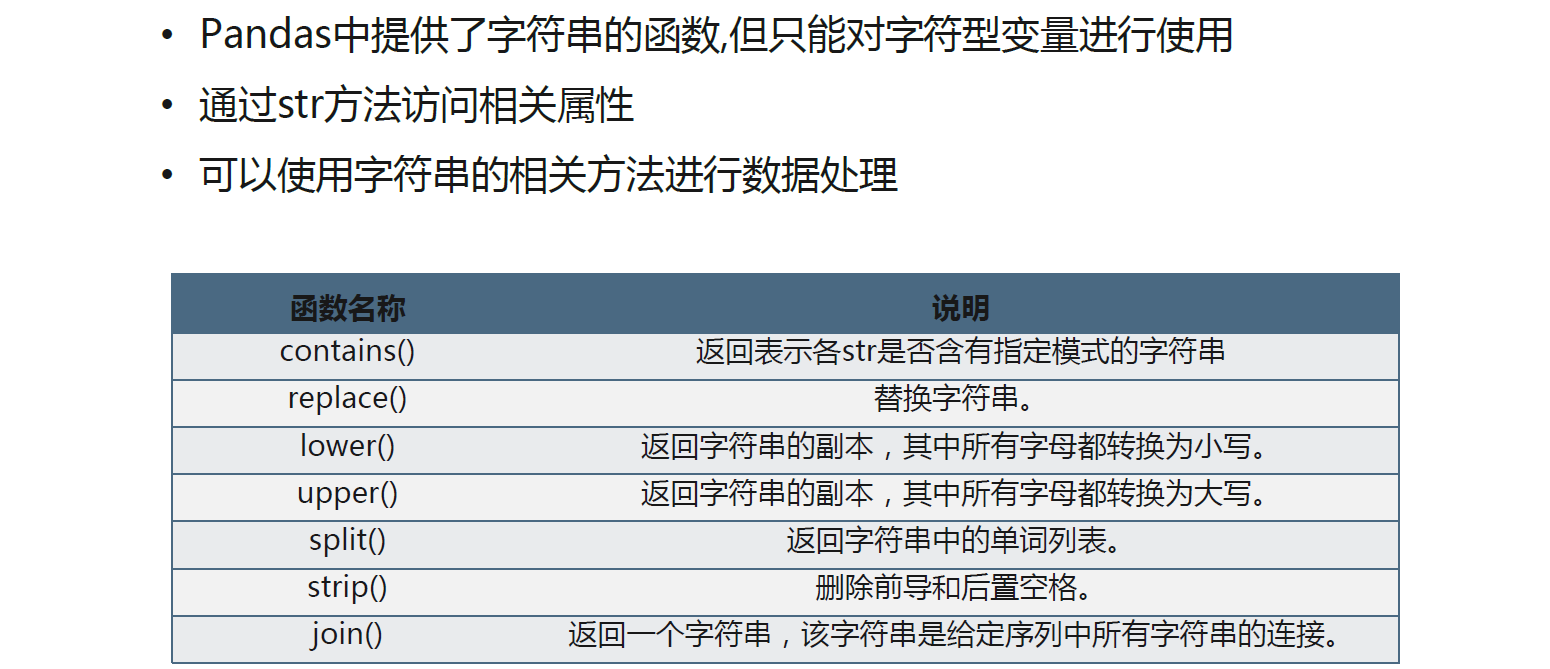
- 摩托车的销售情况
- Condition:摩托车新旧情况(new:新的 和used:使用过的)
- Condition_Desc:对当前状况的描述
- Price:价格
- Location:发获地址
- Model_Year:购买年份
- Mileage:里程
- Exterior_Color:车的颜色
- Make:制造商(牌子)
- Warranty:保修
- Model:类型
- Sub_Model:车辆类型
- Type:种类
- Vehicle_Title:车辆主题
- OBO:车辆仪表盘
- Watch_Count:表数
练习
df1 = pd.read_csv('MotorcycleData.csv',encoding='gbk')#摩托车信息
df1.head(5)
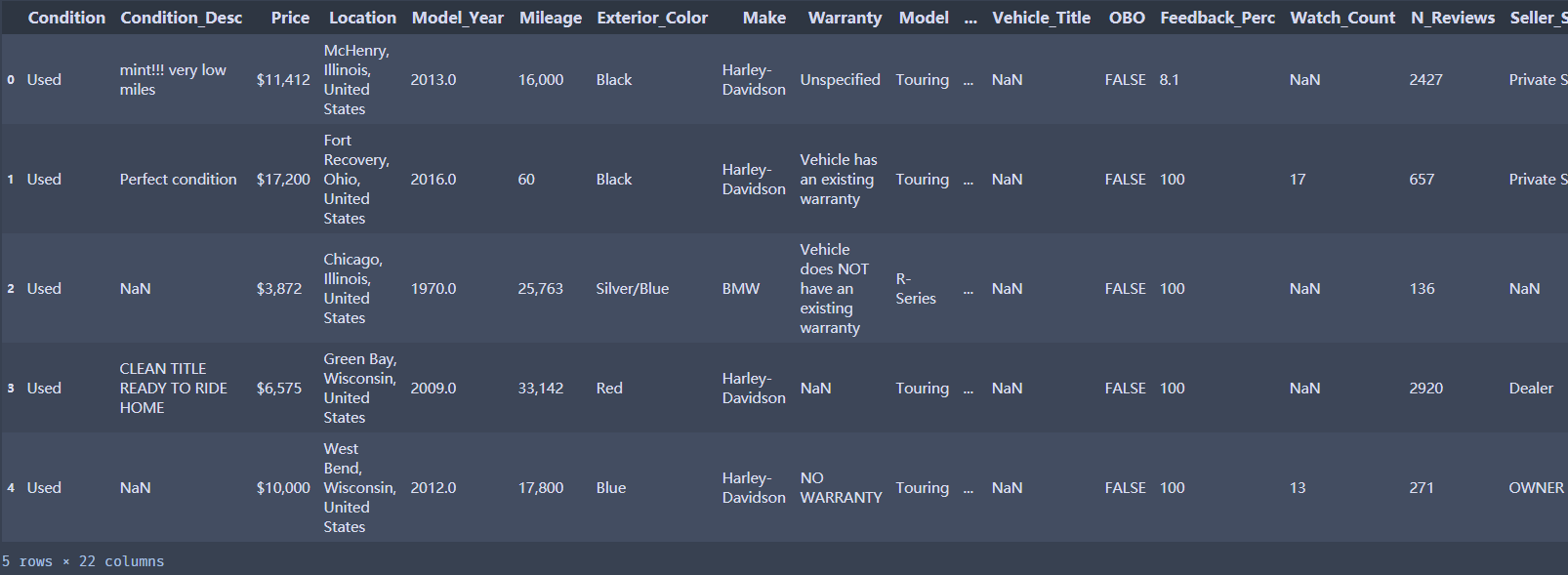
df1['Price'].str[0:4]# 字符串切片
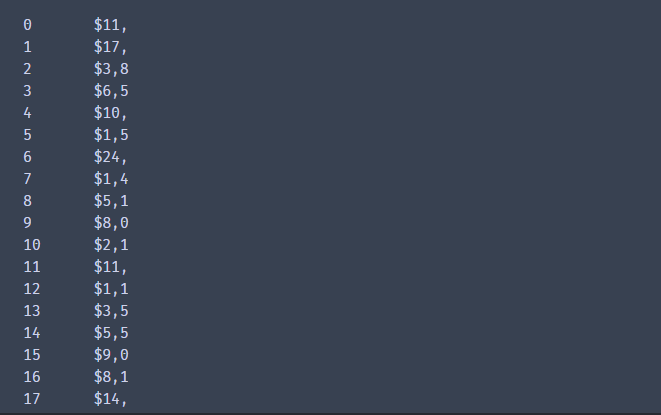
- 将价格转换为float
# df1['Price'].astype(float)
# 之间转换直接报错,需要进行字符串处理
df1['价格'] = df1['Price'].str.strip('$')#字符串相关方法
df1['价格'].head(5)
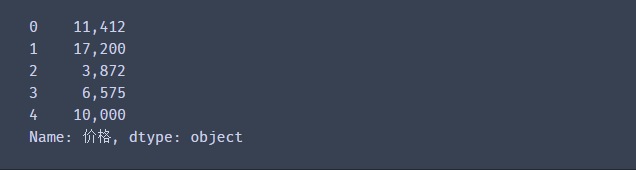
df1['价格'] = df1['价格'].str.replace(',','')
df1['价格'].head(5)
df1['价格'] = df1['价格'].astype(float)# 转换为float数据
df1['Location'].str.split(',') # 使用字符串分割,用于对文本的处理
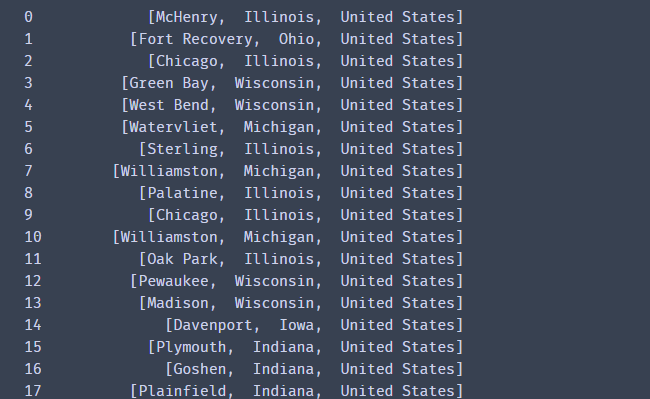
df1['Mileage'].str.len() #计算字符串长度

高阶函数数据处理

练习
df2 = pd.read_csv('sam_tianchi_mum_baby.csv',encoding = 'utf-8',dtype =str)#婴儿信息
def f(x):
if '0' in x:
return '女'
elif '1' in x :
return '男'
else:
return '未知'
# 0代表女,1代表男,2代表未知
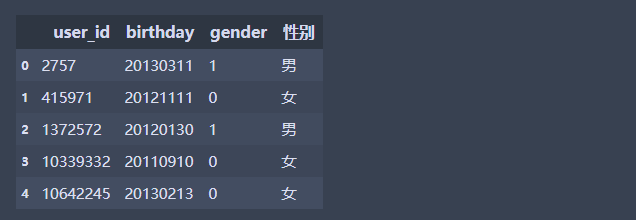
df2['性别'] = df2['gender'].apply(f)
df2.head(5)
#使用map函数
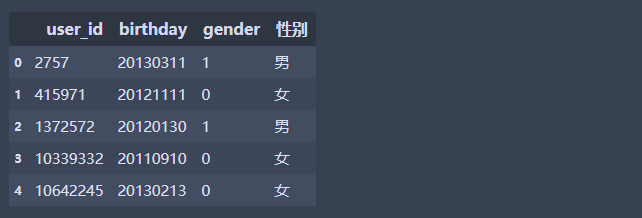
df2['性别'] = df2['gender'].map({'0':'女','1':'男','2':'未知'})
df2.head(5)
df2['user_id'].apply(lambda x: x.replace(x[1:3],'**')) #结合lambda替换
df2['birthday'].apply(lambda x: str(x)[0:4]) #提取年份

第五章:数据清洗之数据统计
数据分组方法
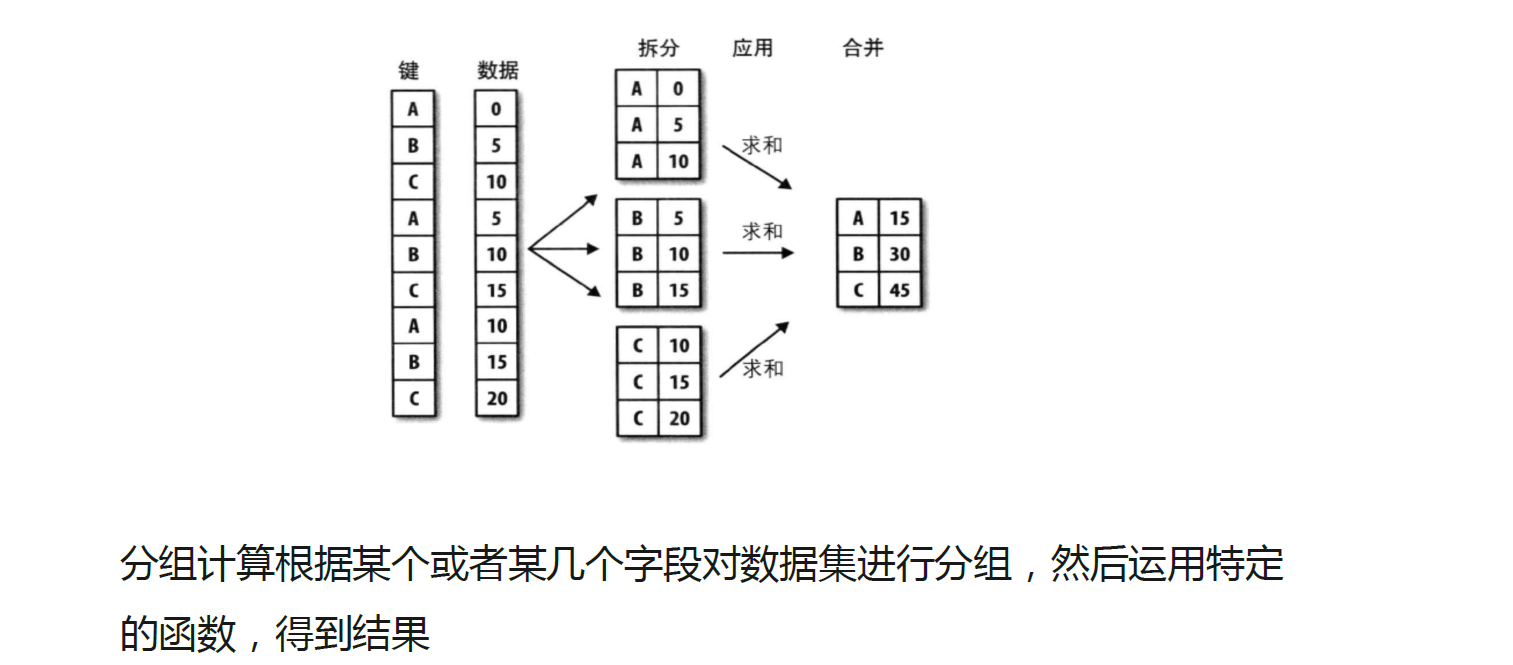
• 使用groupby方法进行分组计算,得到分组对象GroupBy
• 语法为df.groupby(by=)
• 分组对象GroupBy可以运用描述性统计方法, 如count、mean 、 median
、 max和min等

练习
import pandas as pd
import numpy as np
import os
os.chdir(r'G:\pythonProject\pc\Python数据清洗\data')
1.1在线杂货店订单数据
customer :消费者ID,一个消费者可能有多个订单
order :订单ID,订单的唯一标识,不重复
total_items :订单中购买的商品数量
discount% :收到的总折扣百分比
weekday :下单时间:星期几下单,1-7 为 周一至周日
hour :下单时间:几点下单,0-23 为二十四小时制
Food% :食物在订单总价中占比,食物为非生鲜类食物
Fresh% :生鲜类食物在订单总中占比
Drinks% :饮品在订单总价占比,由于高糖税可能导致总折扣为负
Home% :家居用品在订单总价中占比
Beauty% : 美妆类产品在订单总价中占比
Health% :保健类产品在订单总价中占比
Baby% :母婴类产品在订单总价占比
Pets% :宠物用品在订单总价占比
df = pd.read_csv('online_order.csv',encoding = 'gbk',dtype={'customer':str,'order':str})
df.dtypes
1.2 数据分组运算
df.groupby(‘a’)
df.groupby(by = [‘a’,‘b’])
df[[‘a’,‘b’,‘c’]].groupby(‘a’)
df[[‘a’,‘b’,‘c’]].groupby(by = [‘a’,‘b’])
- 使用单个分组变量
- 使用groupby方法
df.head(4)#查看数据

grouped = df.groupby('weekday') #创建分组对象,按照星期进行分组
grouped.mean() #调用方法
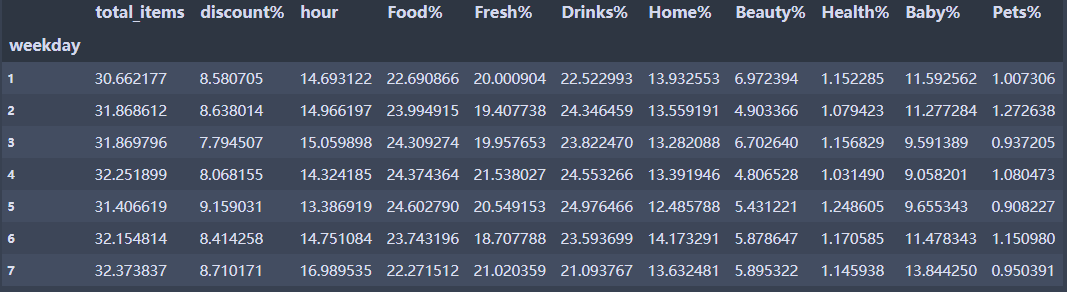
grouped.sum()['total_items']# 计算不同的星期,商品数量的总和
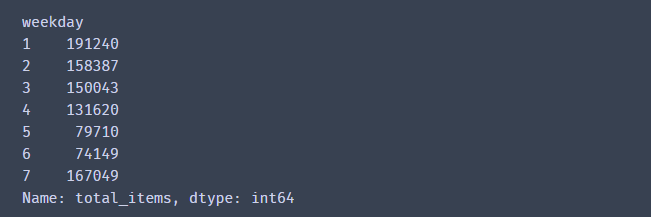
grouped = df.groupby(by =['customer','weekday'])#创建分组对象,按照用户和星期
grouped.sum()['total_items'].head(50) #调用方法,计算不同的用户周一到周天的订购商品数量的总和
聚合函数使用
edu.csdn.net
聚合函数使用
• 对分组对象使用agg聚合函数
• Groupby.agg(func)
• 针对不同的变量使用不同的统计方法

练习
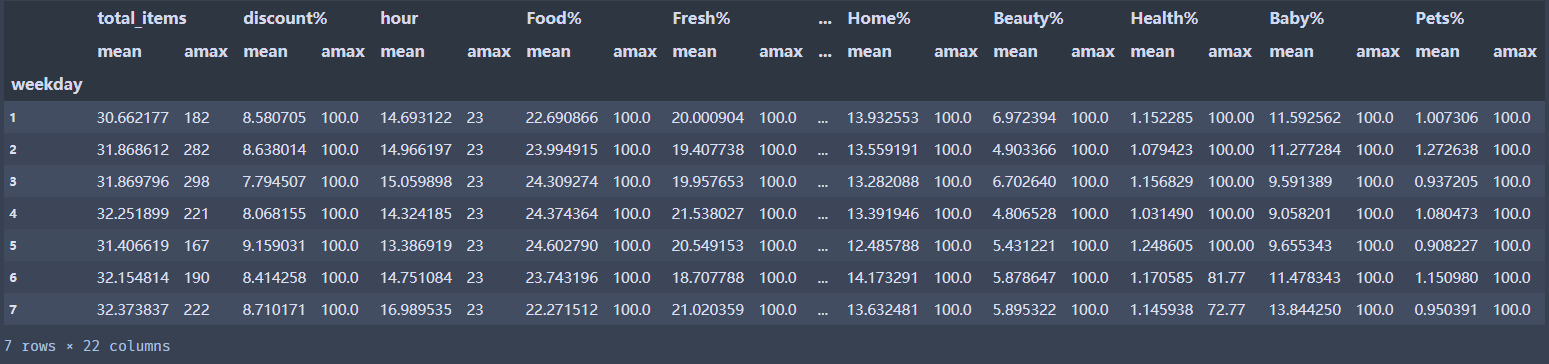
grouped = df.groupby('weekday')#创建分组对象,按照周一到周天进行分组
grouped.agg([np.mean,np.max]).head(20) #对分组后对象,计算均值和总和
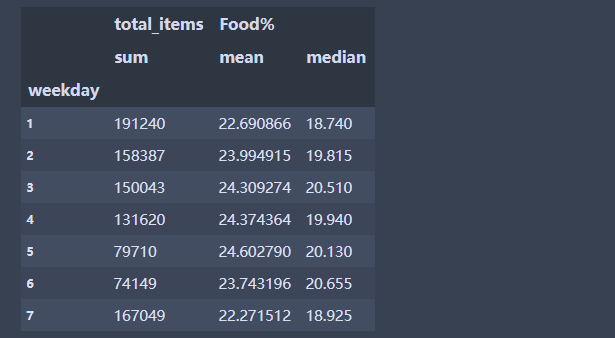
grouped.agg({'total_items':np.sum,'Food%': [np.mean,np.median]}) #对2个变量分别计算不同的统计量
df[['total_items','Food%','Drinks%']].agg([np.sum,np.mean]) #也可以直接对数据进行

分组对象与apply函数
• 函数apply即可用于分组对象,也可以作用于dataframe数据
• Groupby.apply(func)
• 需要注意axis=0和axis=1的区别

练习
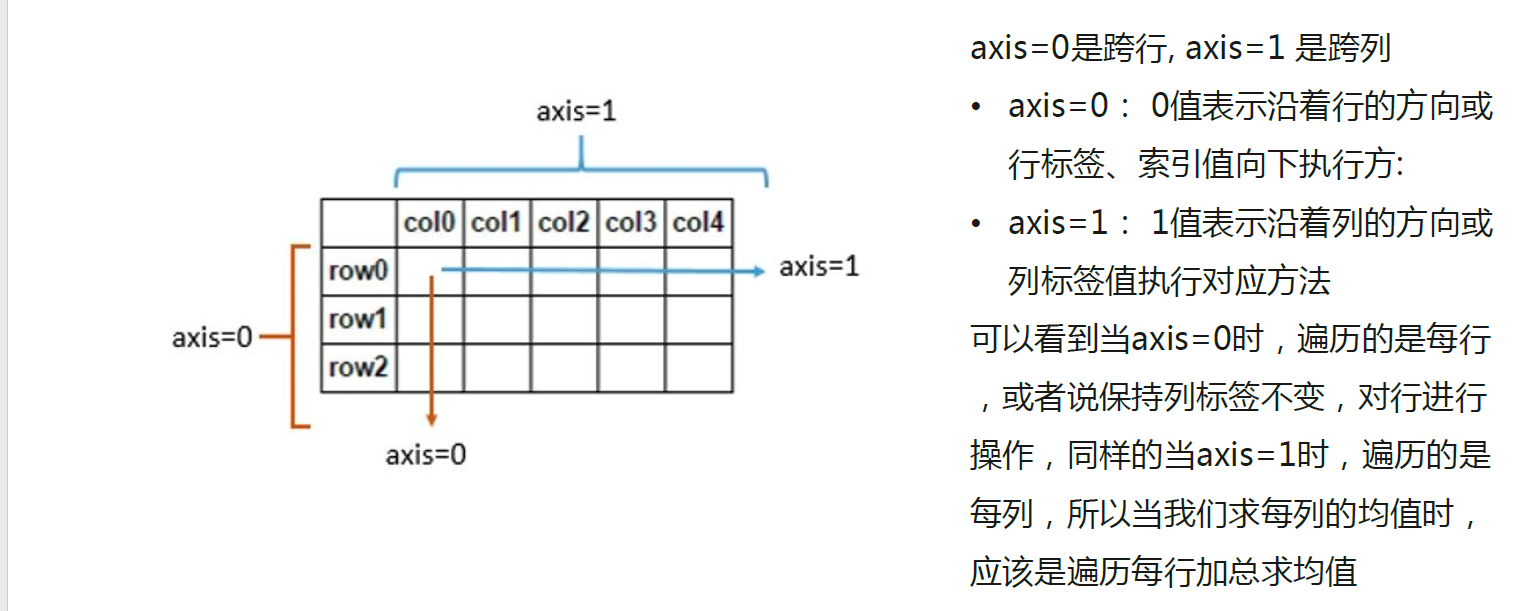
grouped = df.groupby('weekday')
grouped.apply(np.mean)[['total_items','Food%']] #可以做聚合
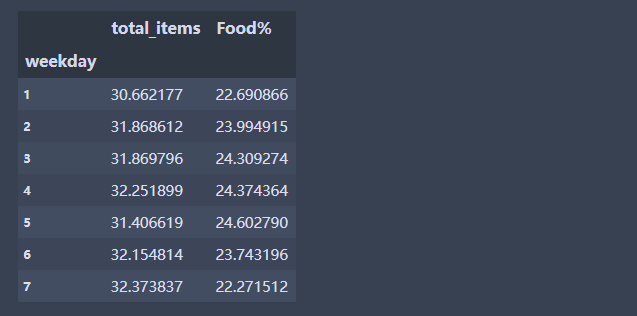
- 体验一下apply 中,axis=0 或者 axis=1的区别
df.columns

var_name = ['Food%', 'Fresh%', 'Drinks%', 'Home%', 'Beauty%', 'Health%', 'Baby%',
'Pets%'] # 不同类型的商品占比
df[var_name].apply(np.sum,axis = 0) #相当于计算每列的总和

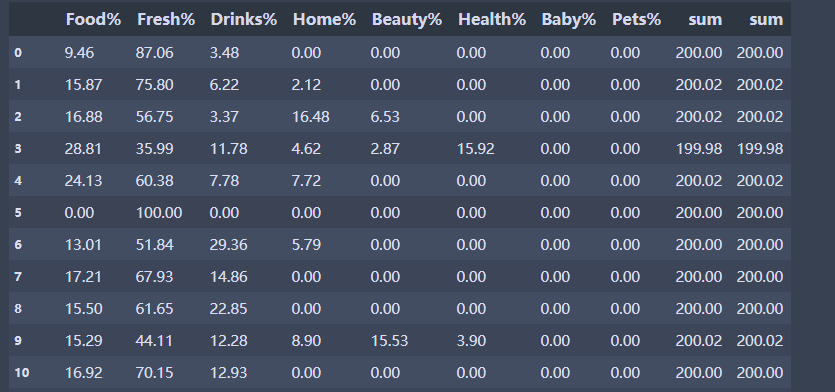
df['sum'] = df[var_name].apply(np.sum,axis=1) # 相当于计算每行的总和
var_name.append('sum')
df[var_name] #查看数据,会发现总和为1
limit_output extension: Maximum message size of 10000 exceeded with 15572 characters
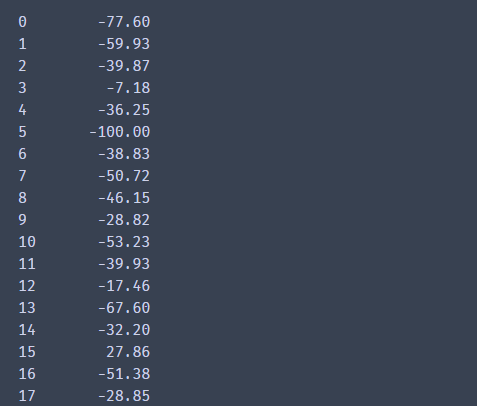
df[var_name].apply(lambda x: x[0] - x[1],axis = 1) #计算食物在订单总价中占比 - 生鲜类食物在订单总中占比
透视图与交叉表
在数据分析中,数据透视表是常见的工具之一,需要根据行或列对数据
进行各个维度数据的汇总,在pandas中,提供了相关函数解决此类问题
交叉表更多用于频数的分析
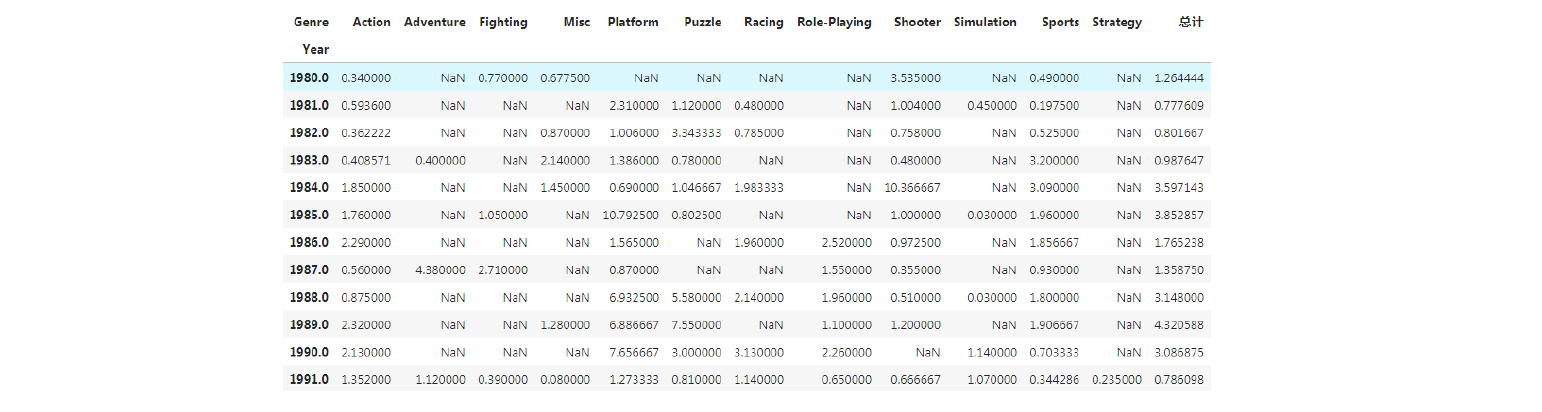
pivot_table( data, index, columns,values, aggfunc, fill_value,
margins, margins_name=)
Index : 行分组键
columns: 列分组键
values: 分组的字段,只能为数值型变量
aggfunc: 聚合函数
margins: 是否需要总计

交叉表用于计算分组频率
pd.crosstab(index,columns,normalize)
Index: 行索引
Columns: 列索引
Normalize: 数据对数据进行标准化,index表示行,column表示列

练习
#读取数据
df = pd.read_csv('online_order.csv',encoding = 'gbk',dtype={'customer':int,'order':str})
df.columns

# 单个变量
#margin =True 表示是否需要总计
pd.pivot_table(data= df,index='weekday',values='total_items',aggfunc=[np.sum,np.size],margins=True,margins_name='总计')#按照周一到周天计算购买的商品数量总数和次数
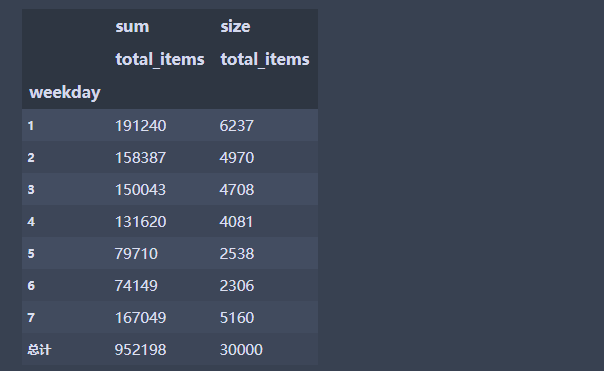
交叉表
交叉表更多用于计算分组频率
# 使用交叉表
#是一种计算分组频数的特殊透视表
# 不同的星期,不同的折扣交叉表
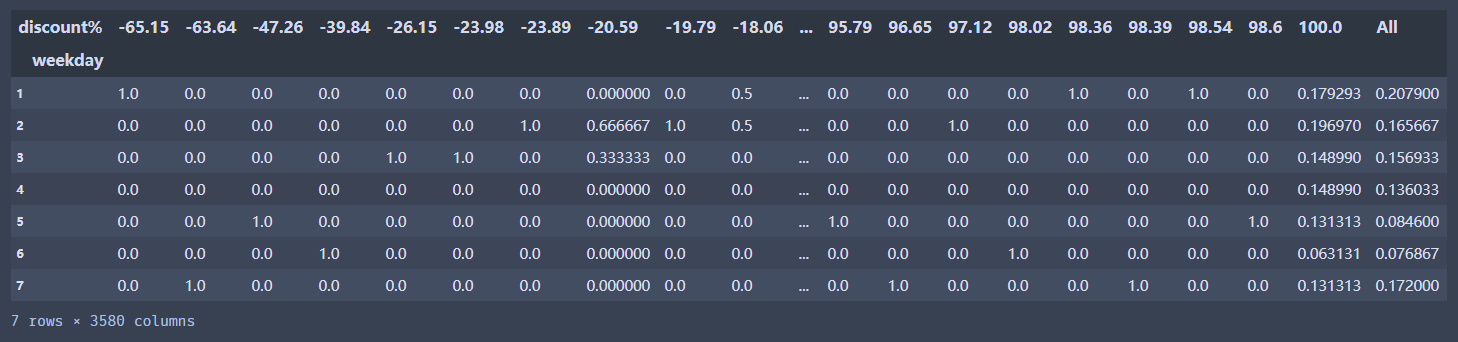
pd.crosstab(index =df['weekday'], columns=df['discount%'],margins=True)
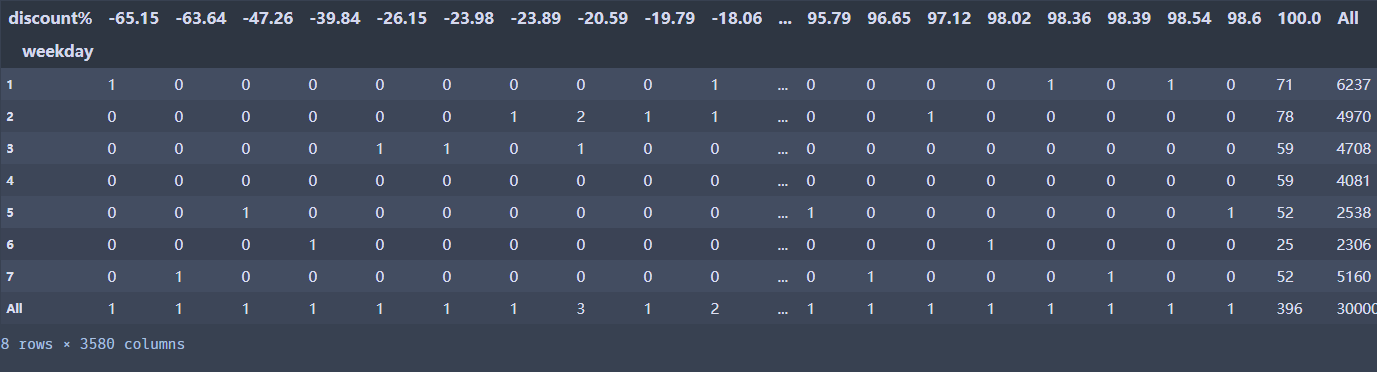
#按照行进行汇总,计算频数占比
pd.crosstab(index =df['weekday'], columns=df['discount%'],margins=True, normalize='all')
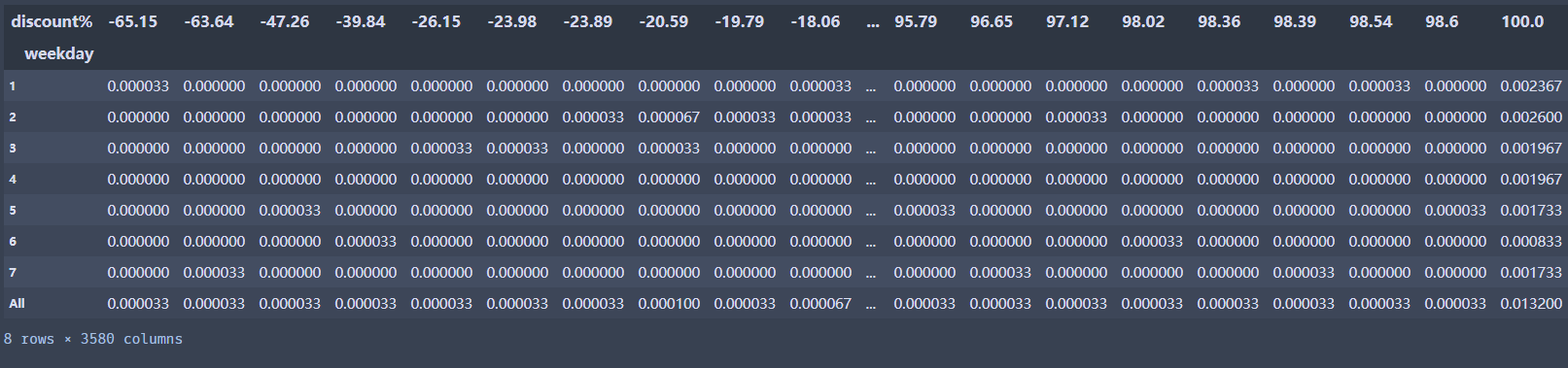
pd.crosstab(index =df['weekday'], columns=df['discount%'],margins=True, normalize='columns') #index表示计算行百分比,columns表示计算列百分比
第六章:数据清洗之数据预处理
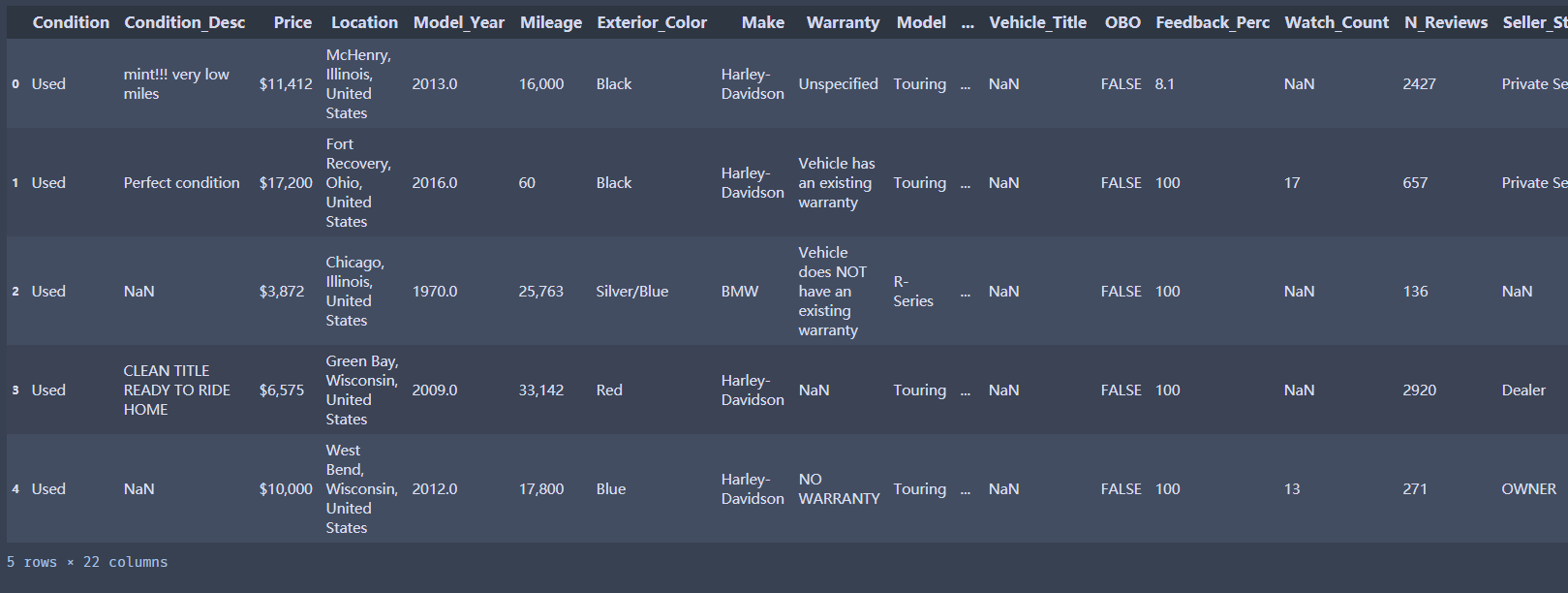
摩托车的销售情况数据
Condition:摩托车新旧情况(new:新的 和used:使用过的)
Condition_Desc:对当前状况的描述
Price:价格
Location:发获地址
Model_Year:购买年份
Mileage:里程
Exterior_Color:车的颜色
Make:制造商(牌子)
Warranty:保修
Model:类型
Sub_Model:车辆类型
Type:种类
Vehicle_Title:车辆主题
OBO:车辆仪表盘
Watch_Count:表数
N_Reviews:评测次数
Seller_Status:卖家身份
Auction:拍卖(Ture或者False)
Buy_Now:现买
Bid_Count:出价计数
import numpy as np
import pandas as pd
import os
os.chdir(r'G:\pythonProject\pc\Python数据清洗\data')
df = pd.read_csv('MotorcycleData.csv',encoding = 'gbk',na_values='Na')
1 重复值处理
• 数据清洗一般先从重复值和缺失值开始处理
• 重复值一般采取删除法来处理
• 但有些重复值不能删除,例如订单明细数据或交易明细数据等

练习
df.head(5)
对价格和里程数数据进行处理
# 自定义一个函数
def f(x):
if '$' in str(x):
x = str(x).strip('$')
x = str(x).replace(',','')
else:
x = str(x).replace(',','')
return float(x)
df['Price'] = df['Price'] .apply(f)
df['Mileage'] = df['Mileage'].apply(f)
print ('数据集是否存在重复观测: \n', any(df.duplicated()))

df[df.duplicated()] #查看那些数据重复
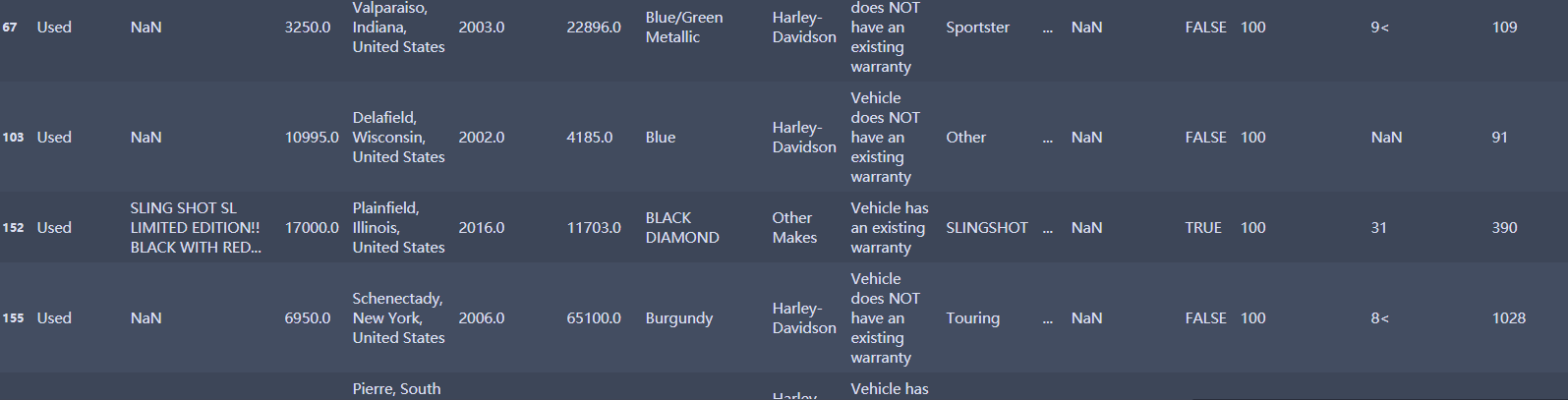
np.sum(df.duplicated()) #计算重复数量

df.drop_duplicates() #删除所有变量都重复的行, 注意没有加inplace = True
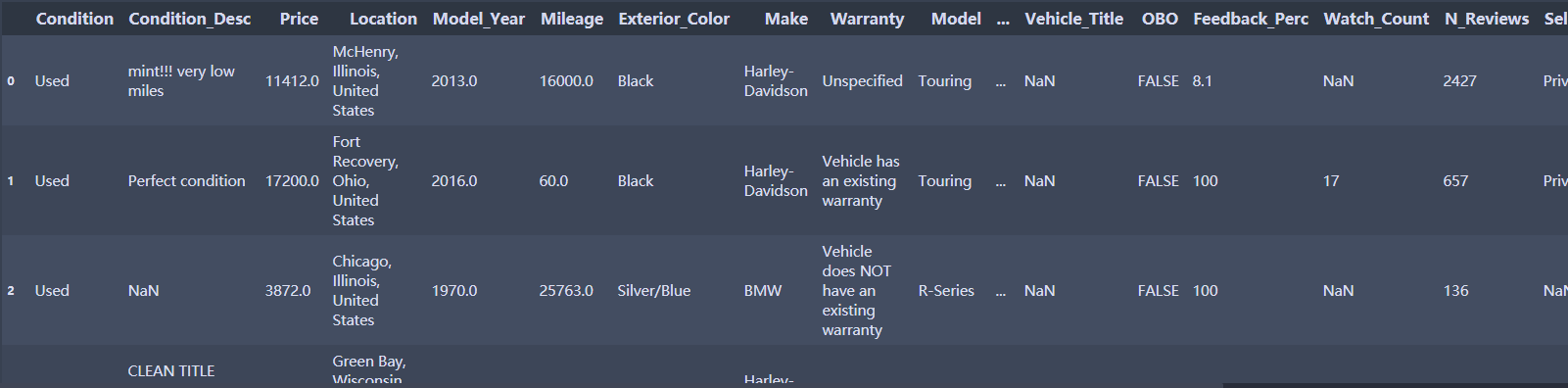
df.drop_duplicates(subset= ['Condition','Condition_Desc','Price','Location'],inplace=True) #按照两个变量重复来来去重
df.info()
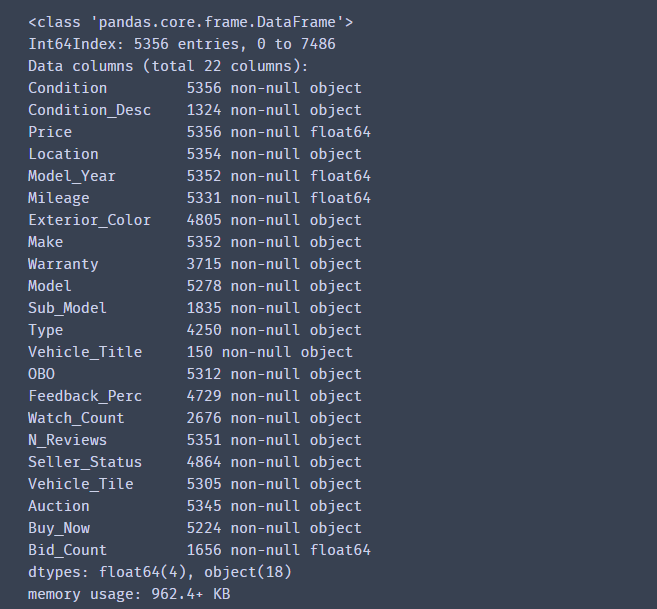
2 缺失值处理
• 缺失值首先需要根据实际情况定义
• 可以采取直接删除法
• 有时候需要使用替换法或者插值法
• 常用的替换法有均值替换、前向、后向替换和常数替换

练习
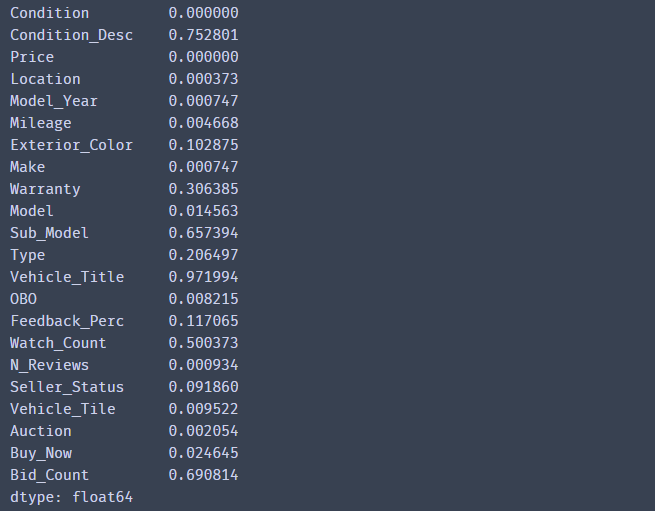
df.apply(lambda x: sum(x.isnull())/len(x),axis= 0) #缺失比例
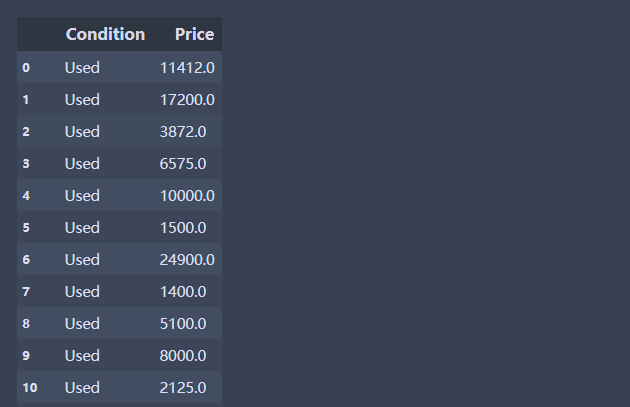
#删除法
df.dropna() #直接删除法

df.dropna(how='any',axis = 1 ) #只要有缺失,就删除这一列
df.dropna(how='any',axis = 0) #只要有缺失,就删除这一行,等价于df.dropna()

axis = 0 或者 1代表的函数在数据集作用的方向,0代表沿着行的方向,1代表沿着列的方向
df.dropna(axis = 0,how='any',subset=['Condition','Price','Mileage']) # 1代表列,0代表行,只要有缺失,就删除这一行,基于三个变量
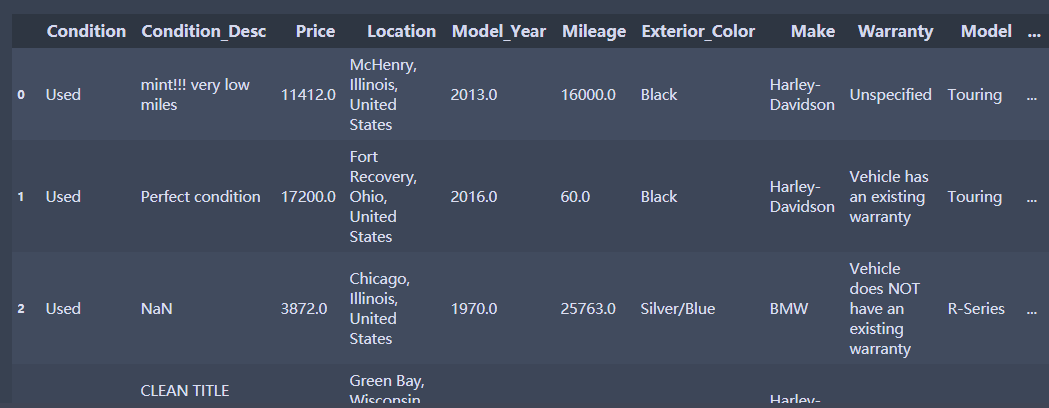
在数据分析中,实际上大部分时候都是按照行来进行删除的,很少会基于列来进行删除 列代表的是变量,是否删除删除列很多时候主要取决于缺失比例
使用替换法进行缺失值的填补
替换法
df.head(5)
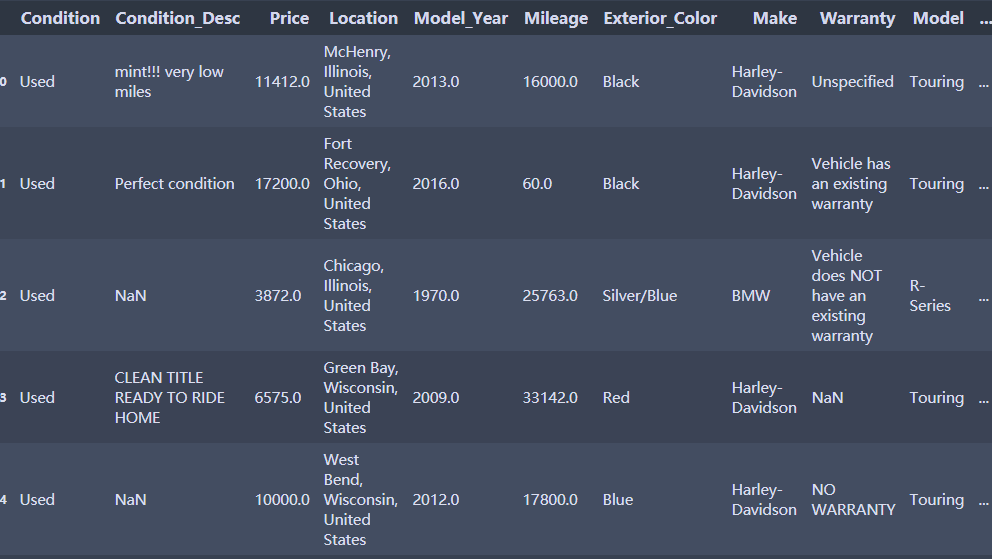
df.Mileage.fillna(df.Mileage.mean()) # 年龄用均值填补
df.Mileage.fillna(df.Mileage.median()) #中位数填补

df[df['Exterior_Color'].isnull()]
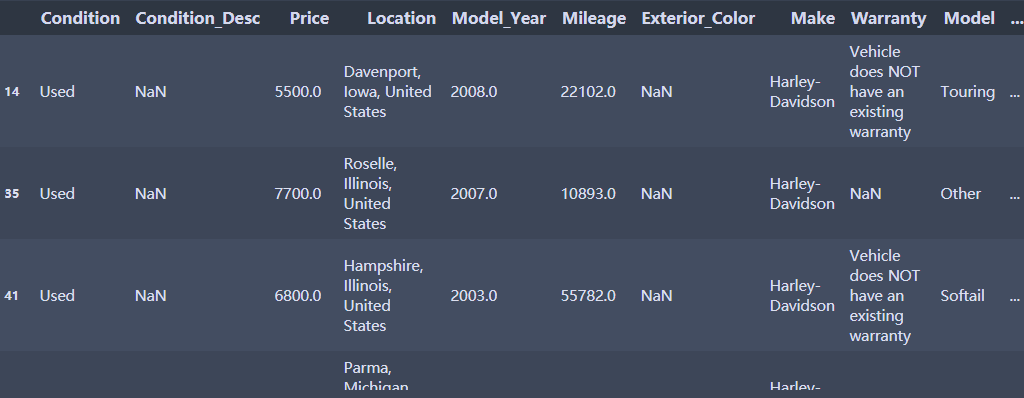
df.Exterior_Color.fillna(df.Exterior_Color.mode()[0]) #众数填补
df.fillna(20) # 所有缺失用20填补
# 婚姻状况使用众数,年龄使用均值,农户家庭人数使用中位数
df.fillna(value = {'Exterior_Color':df.Exterior_Color.mode()[0],'Mileage':df.Mileage.mean()})
df['Exterior_Color'].fillna(method='ffill') #前向填补
df['Exterior_Color'].fillna(method='bfill') #后向填补

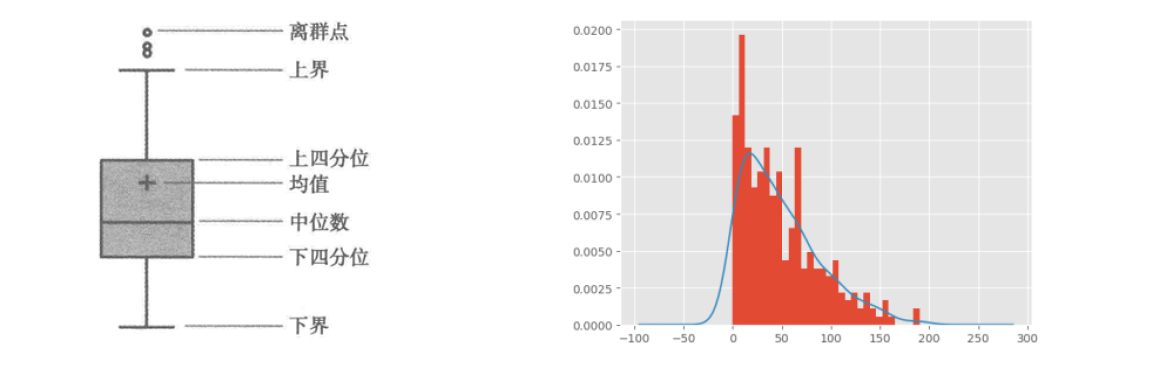
3 异常值处理
• 指那些偏离正常范围的值,不是错误值
• 异常值出现频率较低,但又会对实际项目分析造成偏差
• 异常值一般用过箱线图法(分位差法)或者分布图(标准差法)来判断
• 异常值往往采取盖帽法或者数据离散化
练习
异常值检测可以使用均值的2倍标准差范围,也可以使用上下4分位数差方法
# 异常值检测之标准差法
xbar = df.Price.mean()
xstd = df.Price.std()
print('标准差法异常值上限检测:\n',any(df.Price> xbar + 2.5 * xstd))
print('标准差法异常值下限检测:\n',any(df.Price< xbar - 2.5 * xstd))

# 异常值检测之箱线图法
Q1 = df.Price.quantile(q = 0.25)
Q3 = df.Price.quantile(q = 0.75)
IQR = Q3 - Q1
print('箱线图法异常值上限检测:\n',any(df.Price > Q3 + 1.5 * IQR))
print('箱线图法异常值下限检测:\n',any(df.Price < Q1 - 1.5 * IQR))

import matplotlib.pyplot as plt
%matplotlib inline
df.Price.plot(kind ='box')

# 导入绘图模块
import matplotlib.pyplot as plt
# 设置绘图风格
plt.style.use('seaborn')
# 绘制直方图
df.Price.plot(kind = 'hist', bins = 30, density = True)
# 绘制核密度图
df.Price.plot(kind = 'kde')
# 图形展现
plt.show()
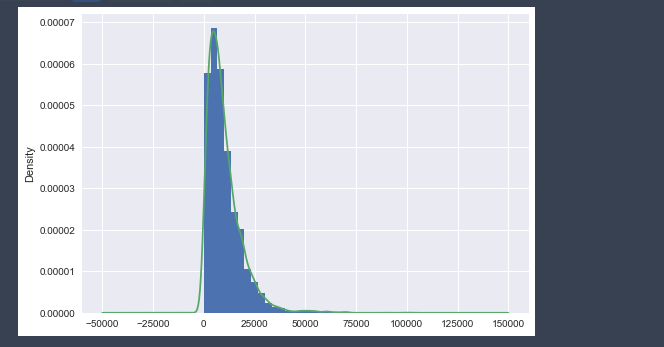
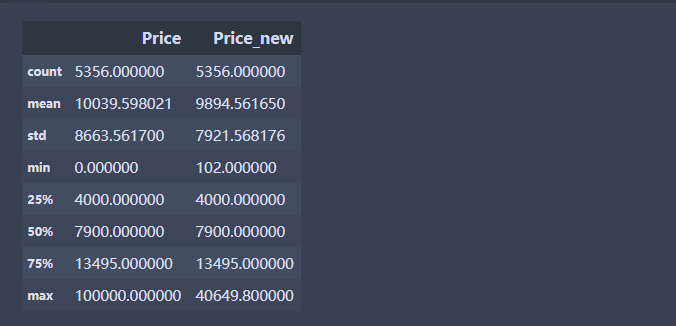
# 用99分位数和1分位数替换
#计算P1和P99
P1 =df.Price.quantile(0.01); P99 = df.Price.quantile(0.99)
#先创建一个新变量,进行赋值,然后将满足条件的数据进行替换
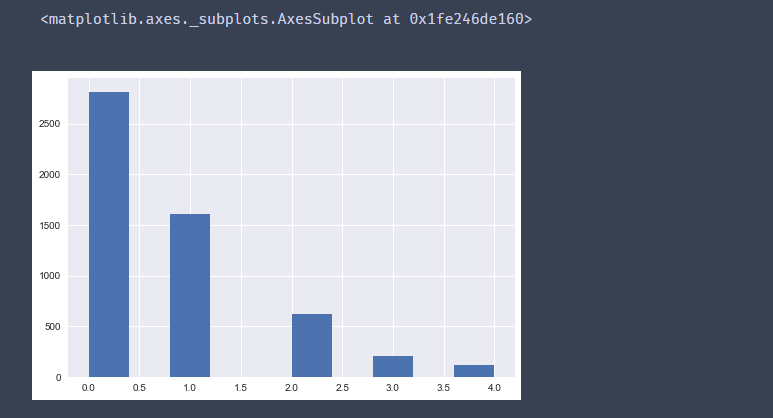
df['Price_new'] = df['Price']
df.loc[df['Price'] > P99,'Price_new'] = P99
df.loc[df['Price'] < P1,'Price_new'] = P1
df[['Price','Price_new']].describe()
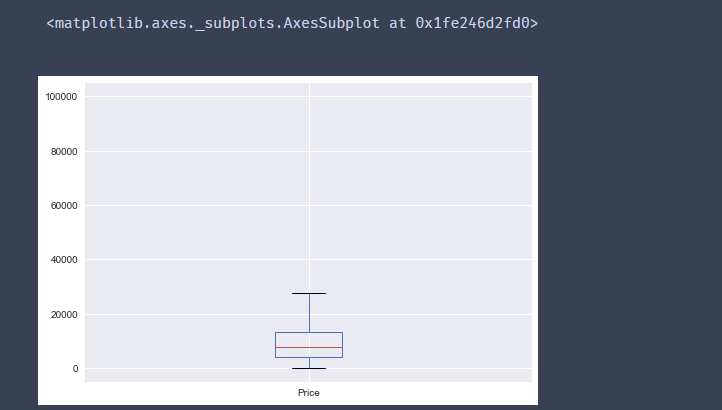
再次使用箱线图可以发现离群值已被剔除
df.Price.plot(kind ='box')
4 数据离散化
• 数据离散化就是分箱
• 一般常用分箱方法是等频分箱或者等宽分箱
• 一般使用pd.cut或者pd.qcut函数

练习
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False)
参数:
x,类array对象,且必须为一维,待切割的原形式
bins, 整数、序列尺度、或间隔索引。如果bins是一个整数,它定义了x宽度范围内的等宽面元数量,但是在这种情况下,x的范围在每个边上被延长1%,以保证包括x的最小值或最大值。如果bin是序列,它定义了允许非均匀bin宽度的bin边缘。在这种情况下没有x的范围的扩展。
right,布尔值。是否是左开右闭区间,right=True,左开右闭,right=False,左闭右开
labels,用作结果箱的标签。必须与结果箱相同长度。如果FALSE,只返回整数指标面元。
retbins,布尔值。是否返回面元
precision,整数。返回面元的小数点几位
include_lowest,布尔值。第一个区间的左端点是否包含
df.head(5)
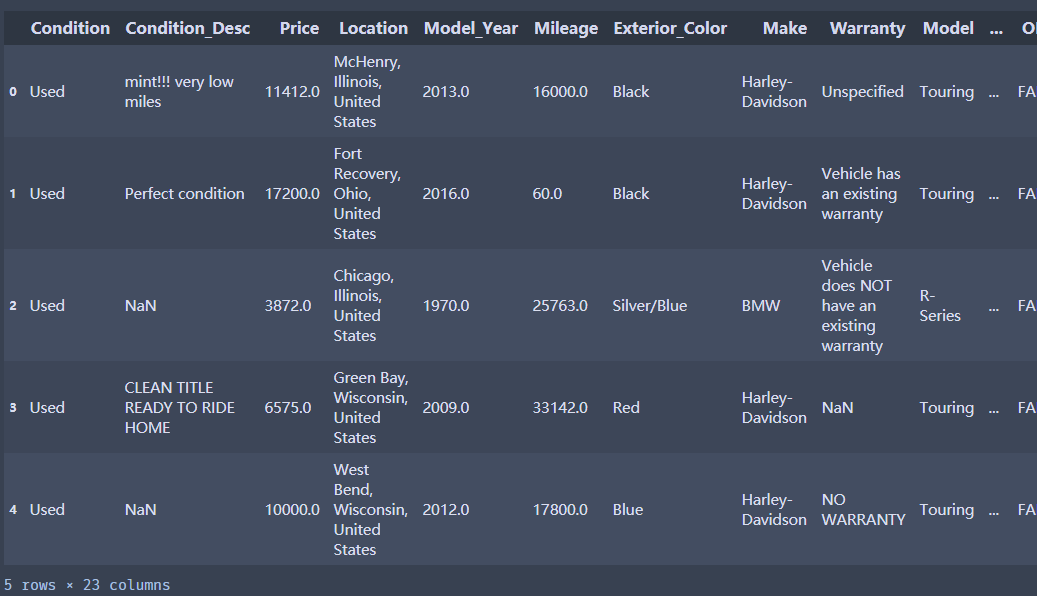
df['Price_bin'] = pd.cut(df['Price_new'],5,labels=range(5))
df['Price_bin'].hist()
这里发现分布不均匀,可以通过数据离散化让数据更加均匀
自定义分段标准和标签
df['Price_new'].describe()
w = [100,1000,5000,10000,20000,50000]
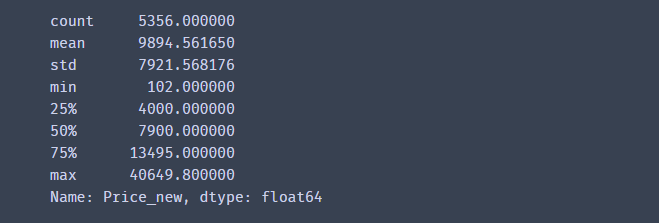
df['Price_bin'] = pd.cut(df['Price_new'], bins =w,labels=['低','便宜','划算','中等','高'],right=False)
df['Price_bin'].value_counts()
pandas.qcut(x, q, labels=None, retbins=False, precision=3, duplicates=’raise’)
参数: x
q,整数或分位数组成的数组。
q, 整数 或分位数数组 整数比如 4 代表 按照4分位数 进行切割
labels, 用作结果箱的标签。必须与结果箱相同长度。如果FALSE,只返回整数指标面元。
原理都是基于分位数来进行离散化
k = 5
w = [1.0*i/k for i in range(k+1)]
w

df['Price_bin'] = pd.qcut(df['Price_new'],w,labels=range(k))
df['Price_bin'].hist()
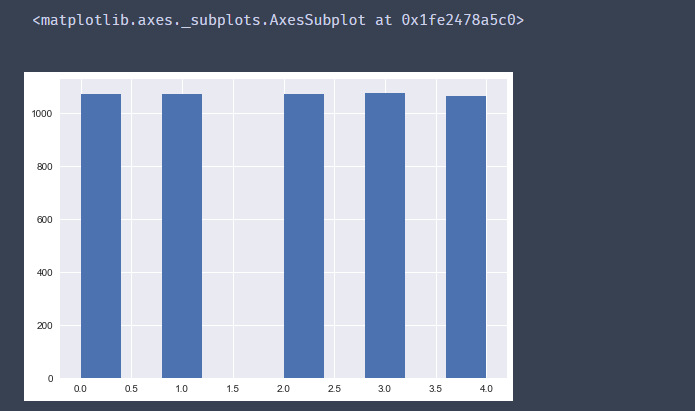
或者先计算分位数的值
k = 5
w1 = df['Price_new'].quantile([1.0*i/k for i in range(k+1)])#先计算分位数,在进行分段
w1[0] = w1[0]* 0.95 # 最小值缩小一点
w[-1] = w1[1]* 1.05 # 将最大值增大一点, 目的是为了确保数据在这个范围内
w1
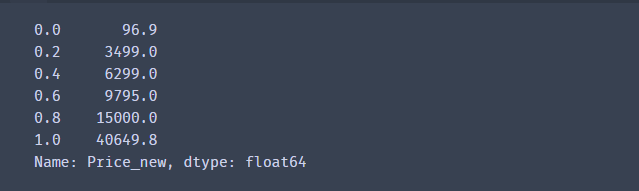
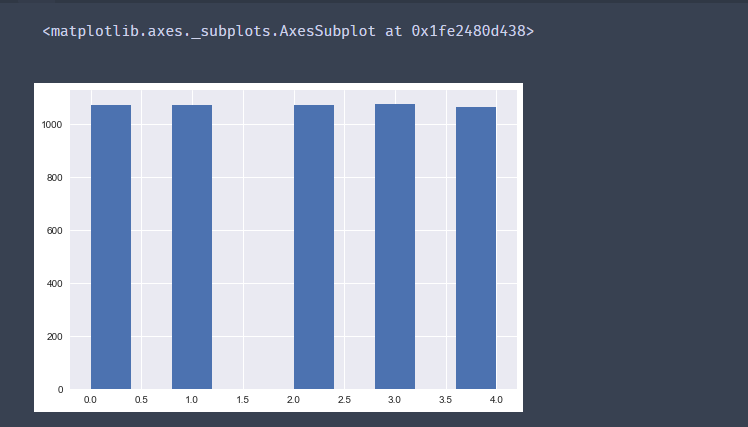
df['Price_bin'] = pd.cut(df['Price_new'],w1,labels=range(k))
df['Price_bin'].hist()
第七章:总结
数据清洗步骤
- 数据获取,使用read_csv或者read_excel
- 数据探索,使用shape,describe或者info函数
- 行列操作,使用loc或者iloc函数
- 数据整合,对不同数据源进行整理
- 数据类型转换,对不同字段数据类型进行转换
- 分组汇总,对数据进行各个维度的计算
- 处理重复值、缺失值和异常值以及数据离散化
函数大全
- merge,concat函数常常用于数据整合
- pd.to_datetime常常用于日期格式转换
- str函数用于字符串操作
- 函数astype用于数据类型转换
- 函数apply和map用于更加高级的数据处理
- Groupby用于创建分组对象
- 透视表函数pd.pivot_table和交叉表pd.crosstab
- 分组对象和agg结合使用,统计需要的信息
数据清洗的内容
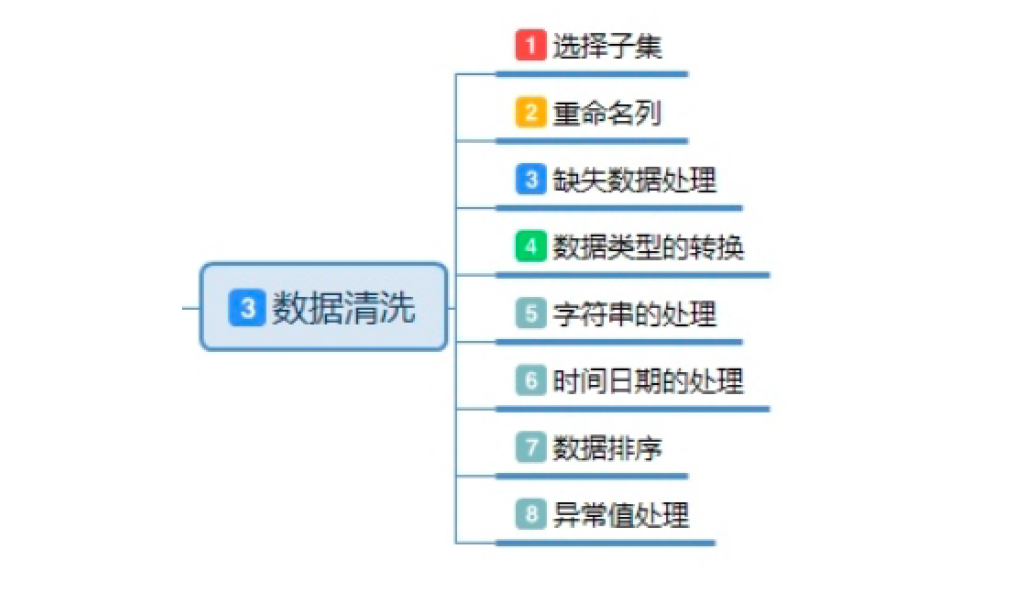
数据清洗总结
数据清洗实质上是将实际业务问题中,脏数据清洗干净,转换为’干净的数据’, 所谓的脏
,指数据可能存在以下几种问题(主要问题):
- 数据缺失 (Incomplete) 是属性值为空的情况。如 Occupancy = “ ”
- 数据噪声 (Noisy)是数据值不合常理的情况。如 Salary = “-100”
- 数据不一致 (Inconsistent)是数据前后存在矛盾的情况。如 Age = “042” 或者
Birthday = “01/09/1985” - 数据冗余 (Redundant)是数据量或者属性数目超出数据分析需要的情况
- 离群点/异常值 (Outliers)是偏离大部分值的数据
- 数据重复是在数据集中出现多次的数据
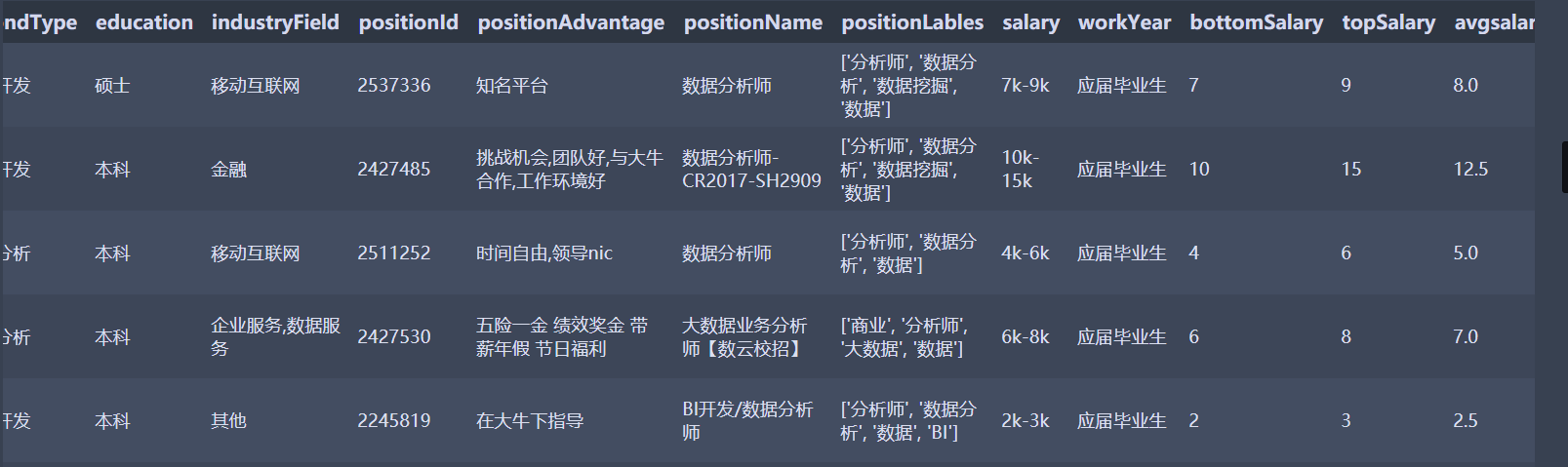
数据分析师招聘数据清洗实战
数据是数据分析师的招聘薪资,主要内容是进行数据读取,数据概述,数据清洗和整理
数据获取:链接:https://pan.baidu.com/s/1sSmyiUfkDtVHuJEQP56h3w
提取码:okic
数据导入并查看
首先载入的数据在pandas中,常用的载入函数是read_csv。除此之外还有read_excel和read_table,table可以读取txt。若是服务器相关的部署,则还会用到read_sql,直接访问数据库,但它必须配合mysql相关包。
import pandas
df = pandas.read_csv('data/DataAnalyst.csv',encoding='gb2312')
#查看表数据
df.head(5)
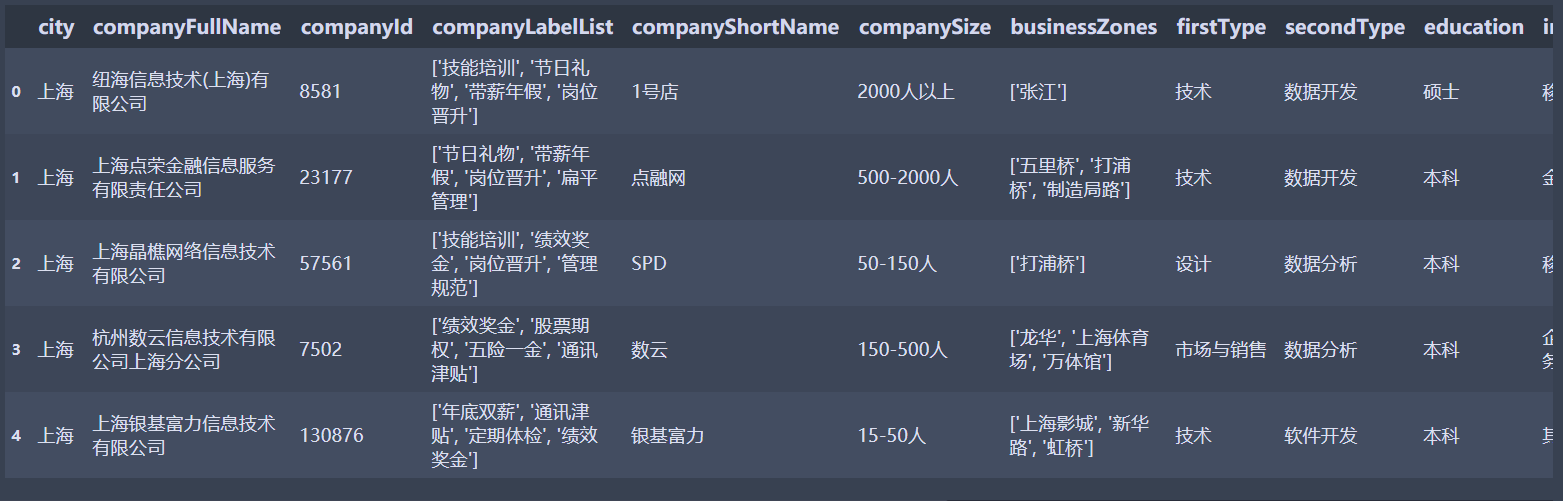
查看表结构
df.info()
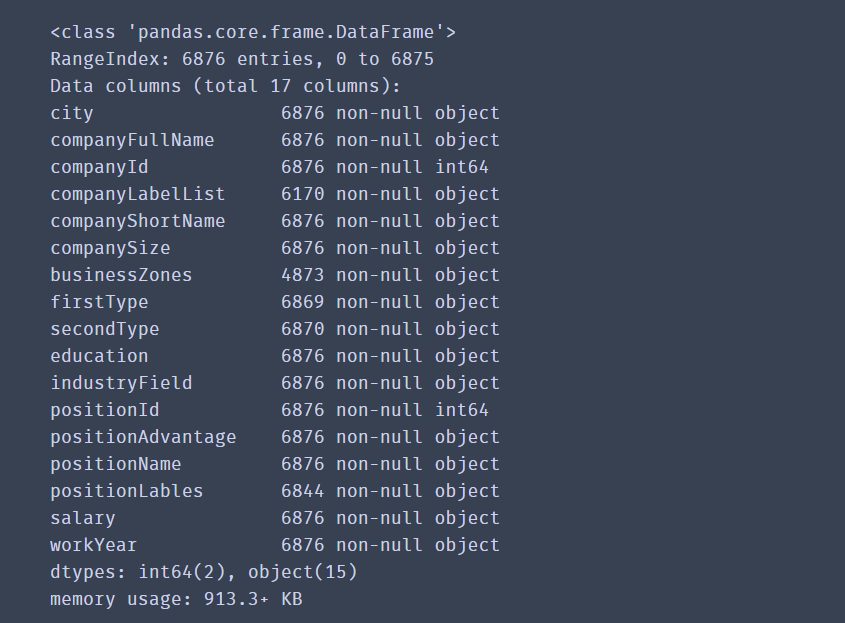
这里列举出了数据集拥有的各类字段,一共有6876个,公司id和职位id为数字,其他都是字符串。
重复数据处理
查看重复数据
print(len(df.positionId.unique()))

unique函数可以返回唯一值,数据集中positionId是职位ID,值唯一。原始值有6876,配合len函数计算出唯一值共有5031个,说明有多出来的重复值。
处理重复数据
df_duplicates=df.drop_duplicates(subset='positionId',keep='first')
df_duplicates.info()
drop_duplicates函数通过subset参数选择以哪个列为去重基准。keep参数则是保留方式,first是保留第一个,删除后余重复值,last还是删除前面,保留最后一个。duplicated函数功能类似,但它返回的是布尔值。
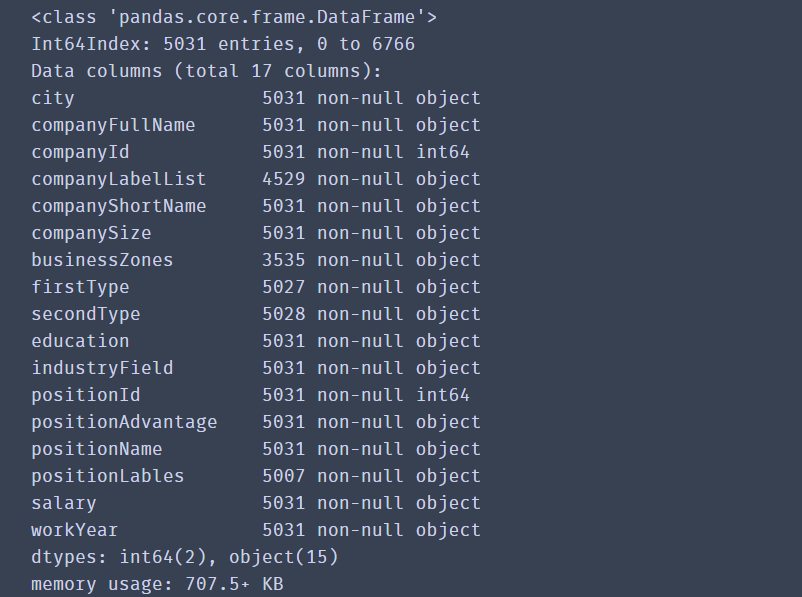
异常值处理
接下来加工salary薪资字段。目的是计算出薪资下限以及薪资上限。薪资内容没有特殊的规律,既有小写k,也有大小K。这里需要用到pandas中的apply。它可以针对DataFrame中的一行或者一行数据进行操作,允许使用自定义函数。

def cut_word(word):
position = word.find ("-")
bottomSalary = word[:position-1]
return bottomSalary
df_duplicates.salary.apply(cut_word)

定义word_cut函数,它查找「-」符号所在的位置,并且截取薪资范围开头至K之间的数字,也就是想要的薪资上限。apply将word_cut函数应用在salary列的所有行。「k以上」这类脏数据怎么办呢?find函数会返回-1,如果按照原来的方式截取,是word[:-2],不是想要的结果,所以需要加一个if判断。
def cut_word(word):
position = word.find ("-")
if position != -1:
bottomSalary = word[:position-1]
else:
bottomSalary = word[:word.upper().find("K")]
return bottomSalary
df_duplicates["bottomSalary"] = df_duplicates.salary.apply(cut_word)

因为python大小写敏感,我们用upper函数将k都转换为K,然后以K作为截取。这里不建议用「以上」,因为有部分脏数据不包含这两字。
将bottomSalary转换为数字,如果转换成功,说明所有的薪资数字都成功截取了。
df_duplicates.bottomSalary.astype("int")

薪资上限topSalary的思路也相近,只是变成截取后半部分。
def cut_word(word,method):
position = word.find ("-")
if position != -1:
bottomSalary = word[:position-1]
topSalary = word[position+1:len(word)-1]
else:
bottomSalary = word[:word.upper().find("K")]
topSalary = bottomSalary
if method == "bottom":
return bottomSalary
else:
return topSalary
df_duplicates["topSalary"] = df_duplicates.salary.apply(cut_word,method = "top")

接下来求解平均薪资。
bottomSalary和topSalary数据类型转换为数字,并为数据集添加avgSalary列
df_duplicates.bottomSalary=df_duplicates.bottomSalary.astype("int")
df_duplicates.topSalary=df_duplicates.topSalary.astype("int")
df_duplicates['avgsalary'] = df_duplicates.apply(lambda x:(x.bottomSalary+x.topSalary)/2,axis=1)
数据类型转换为数字,这里引入新的知识点,匿名函数lamba。很多时候我们并不需要复杂地使用def定义函数,而用lamdba作为一次性函数。lambda x: ******* ,前面的lambda x:理解为输入,后面的星号区域则是针对输入的x进行运算。案例中,因为同时对top和bottom求平均值,所以需要加上x.bottomSalary和x.topSalary。word_cut的apply是针对Series,现在则是DataFrame。axis是apply中的参数,axis=1表示将函数用在行,axis=1则是列。这里的lambda可以用(df_duplicates.bottomSalary + df_duplicates.topSalary)/2替代。
缺失值处理
查看缺失数据存在的列
df_duplicates.isnull().any()
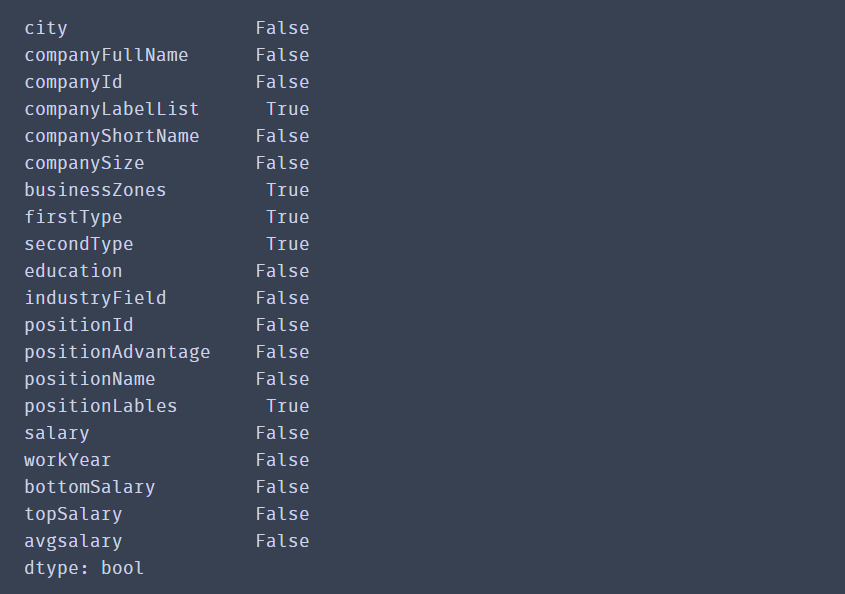
其中companyLabelList,businessZones,secondType,positionLables都存在为空的情况。由于这些字段的缺失值不能向前或者向后填充,单独填充的话数据量也很大,因此为了是数据更加精准,将有空值的行直接删除
df_duplicates.dropna(axis=0, how='any', inplace=True)

再次查看
df_duplicates.isnull().any()
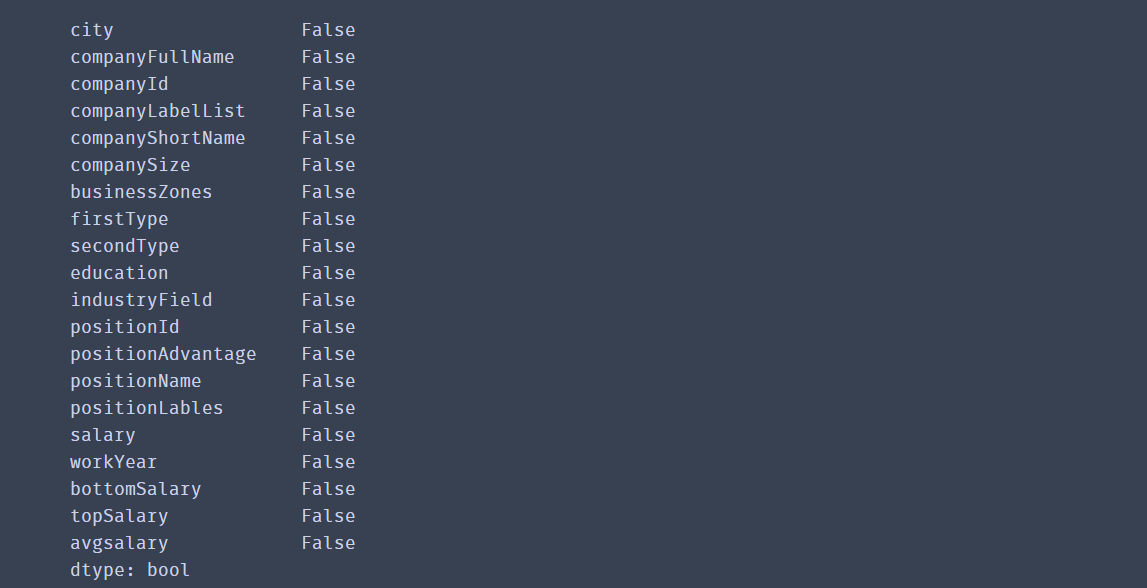
到此,数据清洗的部分完成。切选出我们想要的内容
查看一下已经处理好的数据
df_duplicates.head(10)